MicroBatchExecution¶
MicroBatchExecution is a stream execution engine for Micro-Batch Stream Processing.
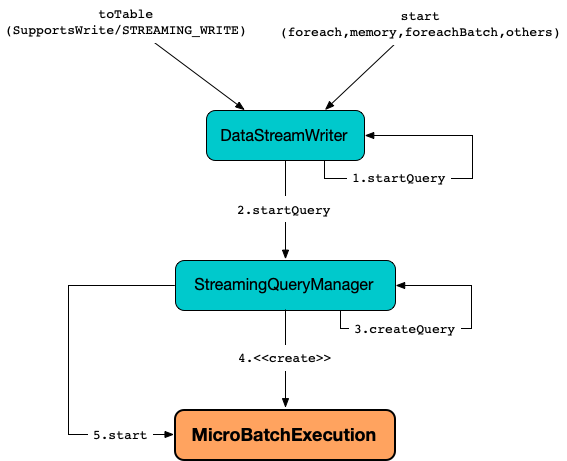
Once created, MicroBatchExecution is requested to start.
Creating Instance¶
MicroBatchExecution takes the following to be created:
-
SparkSession(Spark SQL) - Trigger
-
Clock - Extra Options (
Map[String, String]) - WriteToStream Logical Operator
MicroBatchExecution is created when:
StreamingQueryManageris requested to create a streaming query (whenDataStreamWriteris requested to start execution of the streaming query) for all triggers but ContinuousTrigger
WriteToStream Logical Operator¶
MicroBatchExecution is given a WriteToStream logical operator when created.
The WriteToStream is used to initialize the parent StreamExecution attributes:
The WriteToStream can be used to create a WriteToMicroBatchDataSource as the logical write operator when the sink table is SupportsWrite (Spark SQL).
TriggerExecutor¶
triggerExecutor: TriggerExecutor
MicroBatchExecution creates a TriggerExecutor when created (based on the given Trigger):
| Trigger | TriggerExecutor |
|---|---|
| MultiBatchExecutor | AvailableNowTrigger |
| ProcessingTimeExecutor | ProcessingTimeTrigger |
| SingleBatchExecutor | OneTimeTrigger |
MicroBatchExecution uses the TriggerExecutor for the following:
- runActivatedStream
- Determine the unique streaming sources
triggerExecutor throws an IllegalStateException when the Trigger is not one of the built-in implementations.
Unknown type of trigger: [trigger]
Execution Phases¶
MicroBatchExecution splits execution of a single micro-batch into the following execution phases (and tracks their duration):
Initializing Query Progress for New Trigger¶
startTrigger(): Unit
startTrigger is part of the ProgressReporter abstraction.
startTrigger...FIXME
SparkDataStreams¶
sources: Seq[SparkDataStream]
sources is part of the ProgressReporter abstraction.
Streaming sources and readers (of the StreamingExecutionRelations of the analyzed logical query plan of the streaming query)
Default: (empty)
Initialized when MicroBatchExecution is requested for the transformed logical query plan
Used when:
- Populating start offsets (for the available and committed offsets)
- Constructing or skipping next streaming micro-batch (and persisting offsets to write-ahead log)
Running Activated Streaming Query¶
runActivatedStream(
sparkSessionForStream: SparkSession): Unit
runActivatedStream is part of StreamExecution abstraction.
runActivatedStream requests the TriggerExecutor to execute (the batch runner).
Note
As long as the TriggerExecutor is executing the batch running as long runActivatedStream keeps running.
Batch Runner¶
The batch runner checks whether the streaming query is active (as, in the meantime, it could be terminated).
When terminated, the batch runner waits for the next trigger. Otherwise, the batch runner initializes the trigger.
startTrigger¶
When active, the batch runner initializes query progress for the new trigger (aka startTrigger).
triggerExecution Execution Phase¶
The batch runner starts triggerExecution execution phase.
populateStartOffsets¶
This phase happens only at the start or restart (resume) of a streaming query (when the current batch ID is uninitialized and -1).
The batch runner requests the OffsetSeqLog for the latest batch ID and sets the latest seen offset on the SparkDataStreams.
The batch runner populates start offsets from checkpoint and prints out the following INFO message to the logs (with the committedOffsets):
Stream started from [committedOffsets]
getBatchDescriptionString¶
The batch runner sets the human-readable description for any Spark job submitted as part of this micro-batch as the batch description (using SparkContext.setJobDescription).
A Spark job can be submitted while streaming sources are pulling new data or as part of a sink (e.g., DataStreamWriter.foreachBatch operator).
isCurrentBatchConstructed¶
Unless already constructed, the batch runner constructs the next streaming micro-batch with the value of spark.sql.streaming.noDataMicroBatches.enabled configuration property.
Recording Offsets¶
The batch runner records the trigger offset range for progress reporting (with the committed, available and latestOffsets offsets).
currentBatchHasNewData¶
The batch runner uses currentBatchHasNewData to remember whether the current batch has data or not (based on the offsets available and committed that can change over time).
The batch runner updates isDataAvailable of the StreamingQueryStatus.
Running Micro-Batch¶
With the streaming micro-batch constructed, the batch runner updates the status message to one of the following (based on whether the current batch has data or not):
Processing new data
No new data but cleaning up state
The batch runner runs the streaming micro-batch.
Waiting for data to arrive¶
Otherwise, the batch runner updates the status message to the following:
Waiting for data to arrive
finishTrigger¶
The batch runner finalizes query progress for the trigger (with the flags that indicate whether the current batch had new data and the isCurrentBatchConstructed).
Closing Up¶
At the final step of runActivatedStream when the isActive was enabled, the batch runner does some closing-up work.
isCurrentBatchConstructed¶
With the isCurrentBatchConstructed flag enabled, the batch runner increments the currentBatchId and turns the isCurrentBatchConstructed flag off.
MultiBatchExecutor¶
For MultiBatchExecutor, the batch runner prints out the following INFO message to the logs:
Finished processing all available data for the trigger,
terminating this Trigger.AvailableNow query
The batch runner sets the state to TERMINATED.
Otherwise¶
With the isCurrentBatchConstructed flag disabled (false) and the non-MultiBatchExecutor triggerExecutor, the batch runner sleeps (as long as configured using the spark.sql.streaming.pollingDelay configuration property).
Waiting for next trigger¶
When inactive, the batch runner updates the status message to the following:
Waiting for next trigger
In the end, the batch runner returns whether the streaming query is active or not.
Note
The state of the streaming query (i.e., whether the streaming query is active or not) can change while a micro-batch is executed (e.g., for MultiBatchExecutor when no next batch was constructed).
Populating Start Offsets From Checkpoint (Resuming from Checkpoint)¶
populateStartOffsets(
sparkSessionToRunBatches: SparkSession): Unit
populateStartOffsets requests the Offset Write-Ahead Log for the latest committed batch id with metadata (i.e. OffsetSeq).
Note
The batch id could not be available in the write-ahead log when a streaming query started with a new log or no batch was persisted (added) to the log before.
populateStartOffsets branches off based on whether the latest committed batch was available or not.
populateStartOffsets is used when MicroBatchExecution is requested to run an activated streaming query (before the first "zero" micro-batch).
Latest Committed Batch Available¶
When the latest committed batch id with the metadata was available in the Offset Write-Ahead Log, populateStartOffsets (re)initializes the internal state as follows:
-
Sets the current batch ID to the latest committed batch ID found
-
Turns the isCurrentBatchConstructed internal flag on (
true) -
Sets the available offsets to the offsets (from the metadata)
When the latest batch ID found is greater than 0, populateStartOffsets requests the Offset Write-Ahead Log for the second latest batch ID with metadata or throws an IllegalStateException if not found.
batch [latestBatchId - 1] doesn't exist
populateStartOffsets sets the committed offsets to the second latest committed offsets.
populateStartOffsets updates the offset metadata.
CAUTION: FIXME Describe me
populateStartOffsets requests the Offset Commit Log for the latest committed batch id with metadata.
CAUTION: FIXME Describe me
When the latest committed batch id with metadata was found which is exactly the latest batch ID (found in the Offset Commit Log), populateStartOffsets...FIXME
When the latest committed batch id with metadata was found, but it is not exactly the second latest batch ID (found in the Offset Commit Log), populateStartOffsets prints out the following WARN message to the logs:
Batch completion log latest batch id is [latestCommittedBatchId], which is not trailing batchid [latestBatchId] by one
When no commit log present in the Offset Commit Log, populateStartOffsets prints out the following INFO message to the logs:
no commit log present
In the end, populateStartOffsets prints out the following DEBUG message to the logs:
Resuming at batch [currentBatchId] with committed offsets [committedOffsets] and available offsets [availableOffsets]
No Latest Committed Batch¶
When the latest committed batch id with the metadata could not be found in the Offset Write-Ahead Log, it is assumed that the streaming query is started for the very first time (or the checkpoint location has changed).
populateStartOffsets prints out the following INFO message to the logs:
Starting new streaming query.
[[populateStartOffsets-currentBatchId-0]] populateStartOffsets sets the current batch ID to 0 and creates a new WatermarkTracker.
Constructing Next Micro-Batch (Or Skipping It)¶
constructNextBatch(
noDataBatchesEnabled: Boolean): Boolean
constructNextBatch is used when MicroBatchExecution is requested to run the activated streaming query.
Note
constructNextBatch is only executed when the isCurrentBatchConstructed internal flag is disabled (false).
As a matter of fact, isCurrentBatchConstructed guards execution of constructNextBatch in runActivatedStream so it should not be called.
constructNextBatch performs the following steps:
-
Updating availableOffsets StreamProgress with the latest available offsets
-
Updating batch metadata with the current event-time watermark and batch timestamp
-
Checking whether to construct the next micro-batch or not (skip it)
In the end, constructNextBatch returns whether the next streaming micro-batch was constructed or should be skipped.
Requesting Next and Recent Offsets from Data Streams¶
constructNextBatch uses the uniqueSources registry to request every SparkDataStream for the next and recent offsets (based on the type of a SparkDataStream).
For all types of data streams, constructNextBatch updates the status message to the following:
Getting offsets from [source]
AvailableNowDataStreamWrappers¶
For AvailableNowDataStreamWrappers, constructNextBatch does the following in latestOffset time-tracking section:
- Gets the start offset of the wrapped SparkDataStream (of this
AvailableNowDataStreamWrapper) - Requests the
AvailableNowDataStreamWrapperfor the latest offset per ReadLimit (for the start offset and the ReadLimit) - Requests the
AvailableNowDataStreamWrapperfor the latest offset available
In the end (of this phase), constructNextBatch gives the following pair (of pairs):
- The wrapped SparkDataStream (of this
AvailableNowDataStreamWrapper) with the latest offset - The wrapped SparkDataStream (of this
AvailableNowDataStreamWrapper) with the latest offset reported
SupportsAdmissionControls¶
For SupportsAdmissionControls, constructNextBatch does the following in latestOffset time-tracking section:
- Gets the start offset of the
SupportsAdmissionControl - Requests the
SupportsAdmissionControlfor the latest offset per ReadLimit (for the start offset and the ReadLimit) - Requests the
SupportsAdmissionControlfor the latest offset available
In the end (of this phase), constructNextBatch gives the following pair (of pairs):
- The
SupportsAdmissionControlwith the latest offset - The
SupportsAdmissionControlwith the latest offset reported
Note
The difference of how constructNextBatch handles AvailableNowDataStreamWrappers and SupportsAdmissionControls is only that the AvailableNowDataStreamWrapper is requested for the wrapped SparkDataStream while SupportsAdmissionControl are used directly.
Others¶
FIXME Describe Sources and MicroBatchStreams
Requesting Latest Offsets from Data Streams¶
FIXME
Likely to be merged with the above section
constructNextBatch requests every SparkDataStream (from uniqueSources registry) for a pair of the next and recent offsets. constructNextBatch checks out the offsets in every SparkDataStream sequentially (i.e. one data source at a time).
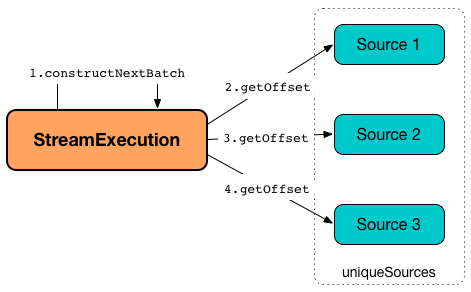
For every streaming source (Data Source API V1), constructNextBatch updates the status message to the following:
Getting offsets from [source]
getOffset Phase¶
FIXME This phase should be merged with the above one
In getOffset time-tracking section, constructNextBatch requests the Source for the latest offset.
For every data source, constructNextBatch updates the status message to the following:
Getting offsets from [source]
setOffsetRange Phase¶
FIXME There is no setOffsetRange phase anymore
In setOffsetRange time-tracking section, constructNextBatch finds the available offsets of the source (in the available offset internal registry) and, if found, requests the MicroBatchReader to...FIXME (from JSON format). constructNextBatch requests the MicroBatchReader to...FIXME
getEndOffset Phase¶
FIXME There is no getEndOffset phase anymore
In getEndOffset time-tracking section, constructNextBatch requests the MicroBatchReader for...FIXME
Updating availableOffsets StreamProgress with Latest Available Offsets¶
constructNextBatch updates the availableOffsets StreamProgress with the latest reported offsets.
Updating Batch Metadata with Current Event-Time Watermark and Batch Timestamp¶
constructNextBatch updates the batch metadata with the current event-time watermark (from the WatermarkTracker) and the batch timestamp.
Checking Whether to Construct Next Micro-Batch or Not (Skip It)¶
constructNextBatch checks whether or not the next streaming micro-batch should be constructed (lastExecutionRequiresAnotherBatch).
constructNextBatch uses the last IncrementalExecution if the last execution requires another micro-batch (using the batch metadata) and the given noDataBatchesEnabled flag is enabled (true).
constructNextBatch also checks out whether new data is available (based on available and committed offsets).
Note
shouldConstructNextBatch local flag is enabled (true) when there is new data available (based on offsets) or the last execution requires another micro-batch (and the given noDataBatchesEnabled flag is enabled).
constructNextBatch prints out the following TRACE message to the logs:
noDataBatchesEnabled = [noDataBatchesEnabled], lastExecutionRequiresAnotherBatch = [lastExecutionRequiresAnotherBatch], isNewDataAvailable = [isNewDataAvailable], shouldConstructNextBatch = [shouldConstructNextBatch]
constructNextBatch branches off per whether to constructs or skip the next batch (per shouldConstructNextBatch flag in the above TRACE message).
Constructing Next Micro-Batch¶
With the shouldConstructNextBatch flag enabled (true), constructNextBatch updates the status message to the following:
Writing offsets to log
[[constructNextBatch-walCommit]] In walCommit time-tracking section, constructNextBatch requests the availableOffsets StreamProgress to convert to OffsetSeq (with the BaseStreamingSources and the current batch metadata (event-time watermark and timestamp)) that is in turn added to the write-ahead log for the current batch ID.
constructNextBatch prints out the following INFO message to the logs:
Committed offsets for batch [currentBatchId]. Metadata [offsetSeqMetadata]
Fixme
(if (currentBatchId != 0) ...)
Fixme
(if (minLogEntriesToMaintain < currentBatchId) ...)
constructNextBatch turns the noNewData internal flag off (false).
In case of a failure while adding the available offsets to the write-ahead log, constructNextBatch throws an AssertionError:
Concurrent update to the log. Multiple streaming jobs detected for [currentBatchId]
Skipping Next Micro-Batch¶
With the shouldConstructNextBatch flag disabled (false), constructNextBatch turns the noNewData flag on (true) and wakes up (notifies) all threads waiting for the awaitProgressLockCondition lock.
Running Single Streaming Micro-Batch¶
runBatch(
sparkSessionToRunBatch: SparkSession): Unit
runBatch prints out the following DEBUG message to the logs (with the current batch ID):
Running batch [currentBatchId]
runBatch then performs the following steps (aka phases):
- getBatch Phase -- Creating Logical Query Plans For Unprocessed Data From Sources and MicroBatchReaders
- Transforming Logical Plan to Include Sources and MicroBatchReaders with New Data
- Transforming CurrentTimestamp and CurrentDate Expressions (Per Batch Metadata)
- Adapting Transformed Logical Plan to Sink with StreamWriteSupport
- Setting Local Properties
- queryPlanning Phase -- Creating and Preparing IncrementalExecution for Execution
- nextBatch Phase -- Creating DataFrame (with IncrementalExecution for New Data)
- addBatch Phase -- Adding DataFrame With New Data to Sink
- Updating Watermark and Committing Offsets to Offset Commit Log
In the end, runBatch prints out the following DEBUG message to the logs (with the current batch ID):
Completed batch [currentBatchId]
Note
runBatch is used exclusively when MicroBatchExecution is requested to run an activated streaming query (and there is a new data to process).
getBatch Phase -- Creating Logical Query Plans For Unprocessed Data From Sources and MicroBatchReaders¶
In getBatch time-tracking section, runBatch goes over the available offsets and processes every Source and MicroBatchReader (associated with the available offsets) to create logical query plans (newData) for data processing (per offset ranges).
Note
runBatch requests sources and readers for data per offset range sequentially, one by one.
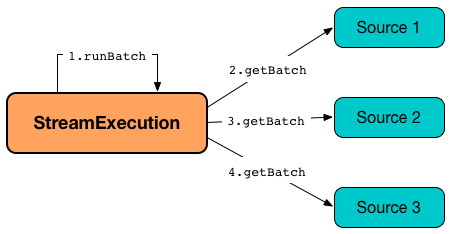
getBatch Phase and Sources¶
For a Source (with the available offsets different from the committedOffsets registry), runBatch does the following:
-
Requests the committedOffsets for the committed offsets for the
Source(if available) -
Requests the
Sourcefor a dataframe for the offset range (the current and available offsets)
runBatch prints out the following DEBUG message to the logs.
Retrieving data from [source]: [current] -> [available]
In the end, runBatch returns the Source and the logical plan of the streaming dataset (for the offset range).
In case the Source returns a dataframe that is not streaming, runBatch throws an AssertionError:
DataFrame returned by getBatch from [source] did not have isStreaming=true\n[logicalQueryPlan]
getBatch Phase and MicroBatchReaders¶
runBatch does the following...FIXME
-
Requests the committedOffsets for the committed offsets for the
MicroBatchReader(if available) -
Requests the
MicroBatchReaderto...FIXME (if available) -
Requests the
MicroBatchReaderto...FIXME (only for SerializedOffsets) -
Requests the
MicroBatchReaderto...FIXME (the current and available offsets)
runBatch prints out the following DEBUG message to the logs.
Retrieving data from [reader]: [current] -> [availableV2]
runBatch looks up the DataSourceV2 and the options for the MicroBatchReader (in the readerToDataSourceMap internal registry).
In the end, runBatch requests the MicroBatchReader for...FIXME and creates a StreamingDataSourceV2Relation logical operator (with the read schema, the DataSourceV2, options, and the MicroBatchReader).
Transforming Logical Plan to Include Sources and MicroBatchReaders with New Data¶
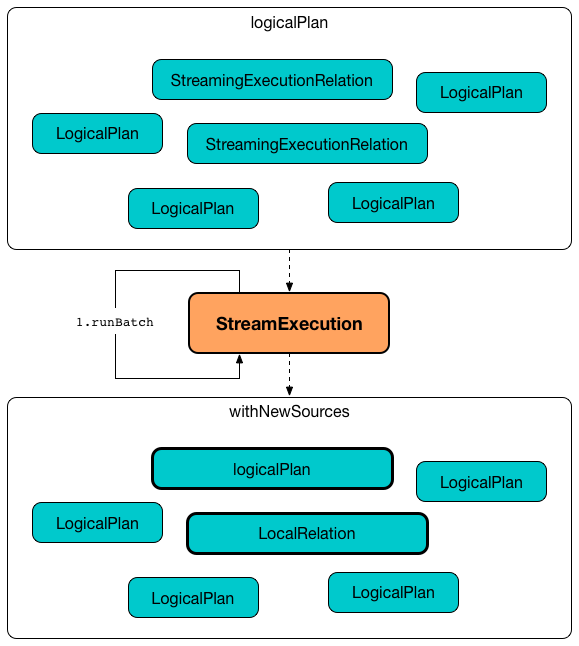
runBatch transforms the analyzed logical plan to include Sources and MicroBatchReaders with new data (newBatchesPlan with logical plans to process data that has arrived since the last batch).
For every StreamingExecutionRelation, runBatch tries to find the corresponding logical plan for processing new data.
If the logical plan is found, runBatch makes the plan a child operator of Project (with Aliases) logical operator and replaces the StreamingExecutionRelation.
Otherwise, if not found, runBatch simply creates an empty streaming LocalRelation (for scanning data from an empty local collection).
In case the number of columns in dataframes with new data and StreamingExecutionRelation's do not match, runBatch throws an AssertionError:
Invalid batch: [output] != [dataPlan.output]
Transforming CurrentTimestamp and CurrentDate Expressions (Per Batch Metadata)¶
runBatch replaces all CurrentTimestamp and CurrentDate expressions in the transformed logical plan (with new data) with the current batch timestamp (based on the batch metadata).
Note
CurrentTimestamp and CurrentDate expressions correspond to current_timestamp and current_date standard function, respectively.
Adapting Transformed Logical Plan to Sink with StreamWriteSupport¶
runBatch...FIXME
For a Sink (Data Source API V1), runBatch changes nothing.
For any other BaseStreamingSink type, runBatch simply throws an IllegalArgumentException:
unknown sink type for [sink]
Setting Local Properties¶
runBatch sets the local properties.
| Local Property | Value |
|---|---|
| streaming.sql.batchId | currentBatchId |
| __is_continuous_processing | false |
queryPlanning Phase -- Creating and Preparing IncrementalExecution for Execution¶

In queryPlanning time-tracking section, runBatch creates a new IncrementalExecution with the following:
-
statecheckpoint directory
In the end (of the queryPlanning phase), runBatch requests the IncrementalExecution to prepare the transformed logical plan for execution (i.e. execute the executedPlan query execution phase).
nextBatch Phase — Creating DataFrame (with IncrementalExecution for New Data)¶
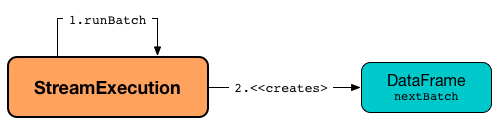
runBatch creates a new DataFrame with the new IncrementalExecution.
The DataFrame represents the result of executing the current micro-batch of the streaming query.
addBatch Phase¶
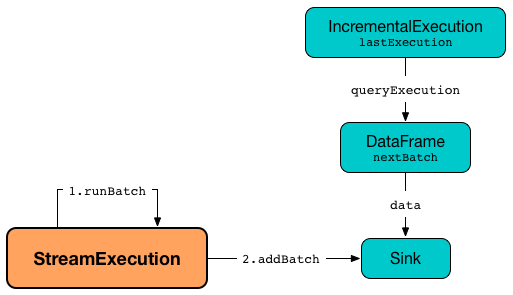
runBatch starts addBatch phase (time-tracking section).
runBatch uses SQLExecution.withNewExecutionId (Spark SQL) (with the Last Incremental QueryExecution) to execute and track all the Spark jobs under one execution id (so it is reported as one single multi-job execution, e.g. in web UI).
SQLExecution.withNewExecutionId, SparkListenerSQLExecutionStart and SparkListenerSQLExecutionEnd
SQLExecution.withNewExecutionId posts a SparkListenerSQLExecutionStart event before query execution and a SparkListenerSQLExecutionEnd event right afterwards.
Register SparkListener to get notified about these two SQL execution events (SparkListenerSQLExecutionStart and SparkListenerSQLExecutionEnd).
runBatch branches off based on the Table (Spark SQL) to write the microbatch to:
- For a Sink (Data Source API V1),
runBatchrequests it to add the DataFrame - For a
SupportsWrite(Spark SQL),runBatchrequests it tocollectthe rows (that, although looks as a performance "nightmare", pulls no data to the driver and just forces execution of the microbatch writer)
In the end (of the addBatch phase), runBatch requests the underlying WriteToDataSourceV2Exec physical operator for the StreamWriterCommitProgress (with numOutputRows metric).
Updating Watermark and Committing Offsets to Offset Commit Log¶
runBatch requests the WatermarkTracker to update event-time watermark (with the executedPlan of the IncrementalExecution).
runBatch requests the Offset Commit Log to persisting metadata of the streaming micro-batch (with the current batch ID and event-time watermark of the WatermarkTracker).
In the end, runBatch adds the available offsets to the committed offsets (and updates the offsets of every source with new data in the current micro-batch).
Stopping Stream Processing (Execution of Streaming Query)¶
stop(): Unit
stop sets the state to TERMINATED.
When the stream execution thread is alive, stop requests the current SparkContext to cancelJobGroup identified by the runId and waits for this thread to die. Just to make sure that there are no more streaming jobs, stop requests the current SparkContext to cancelJobGroup identified by the runId again.
In the end, stop prints out the following INFO message to the logs:
Query [prettyIdString] was stopped
stop is part of the StreamingQuery abstraction.
Checking Whether New Data Is Available¶
isNewDataAvailable: Boolean
isNewDataAvailable returns whether or not there are streaming sources (in the available offsets) for which committed offsets are different from the available offsets or not available (committed) at all.
isNewDataAvailable is true when there is at least one such streaming source.
isNewDataAvailable is used when:
MicroBatchExecutionis requested to run an activated streaming query and construct the next streaming micro-batch
(Transformed) Analyzed Logical Plan¶
logicalPlan: LogicalPlan
logicalPlan is part of the ProgressReporter abstraction.
Lazy Value and ProgressReporter
logicalPlan is a Scala lazy value to guarantee that the code to initialize it is executed once only (when accessed for the first time) and the computed value never changes afterwards.
Learn more in the Scala Language Specification.
Note that logicalPlan is part of the ProgressReporter abstraction in which logicalPlan is a method (def).
Initialization of logicalPlan is done using the following four steps:
- Transforming the analyzed logical plan
- Initializing sources registry
- Initializing uniqueSources registry
- Rewriting the plan for SupportsWrite sink
Transforming Analyzed Logical Plan¶
logicalPlan transforms the analyzed logical plan focusing on the following logical operators:
StreamingRelation¶
For a StreamingRelation, logicalPlan finds a corresponding StreamingExecutionRelation (in the toExecutionRelationMap), if available.
If not found, logicalPlan requests the DataSource (of this StreamingRelation) to createSource for the following metadata path (with resolvedCheckpointRoot and the next consecutive source ID):
[resolvedCheckpointRoot]/sources/[nextSourceId]
logicalPlan increments nextSourceId internal counter.
logicalPlan prints out the following INFO message to the logs:
Using Source [[source]] from DataSourceV1 named '[sourceName]' [[dataSourceV1]]
In the end, logicalPlan creates a StreamingExecutionRelation (for the source and the output schema of this StreamingRelation).
StreamingRelationV2¶
For a StreamingRelationV2, logicalPlan checks if the Table is a SupportsRead and supports MICRO_BATCH_READ table capability. If so, logicalPlan...FIXME
Otherwise, logicalPlan checks if the optional v1Relation (of this StreamingRelationV2) is not defined. If so, logicalPlan...FIXME
For all other cases, logicalPlan finds a corresponding StreamingExecutionRelation (in the v2ToExecutionRelationMap), if available.
If not found, logicalPlan requests the the optional v1Relation (of this StreamingRelationV2), that is supposed to be a StreamingRelation for the DataSource to createSource for the following metadata path (with resolvedCheckpointRoot and the next consecutive source ID):
[resolvedCheckpointRoot]/sources/[nextSourceId]
logicalPlan increments nextSourceId internal counter.
logicalPlan prints out the following INFO message to the logs:
Using Source [[source]] from DataSourceV2 named '[srcName]' [dsStr]
In the end, logicalPlan creates a StreamingExecutionRelation (for the source and the output schema of this StreamingRelationV2).
Initializing Sources Registry¶
logicalPlan initializes the sources registry. logicalPlan collects all the SparkDataStreams (from StreamingExecutionRelations and StreamingDataSourceV2Relations) in the transformed analyzed logical plan.
Initializing uniqueSources Registry¶
logicalPlan initializes the uniqueSources registry based on the TriggerExecutor:
MultiBatchExecutor¶
FIXME
ProcessingTimeExecutor¶
For ProcessingTimeExecutor, logicalPlan takes distinct (unique) SparkDataStreams from sources registry (of all the data streams in a streaming query).
For every unique SparkDataStream, logicalPlan creates a pair of this SparkDataStream and the default ReadLimit if it is SupportsAdmissionControl (or defaults to ReadAllAvailable).
SingleBatchExecutor¶
FIXME
Rewriting Plan For SupportsWrite Sink¶
In the end, logicalPlan is the transformed analyzed logical plan unless the sink is SupportsWrite (Spark SQL).
For the sink to be a SupportsWrite (e.g. KafkaTable, ForeachWriterTable), logicalPlan...FIXME
AssertionError¶
logicalPlan throws an AssertionError when not on the stream execution thread:
logicalPlan must be initialized in QueryExecutionThread "but the current thread was [currentThread]
streaming.sql.batchId Local Property¶
MicroBatchExecution defines streaming.sql.batchId as the name of the local property to be the current batch or epoch IDs (that Spark tasks can use at execution time).
streaming.sql.batchId is used when:
MicroBatchExecutionis requested to run a single streaming micro-batch (and sets the property to be the current batch ID)DataWritingSparkTaskis requested to run (and needs an epoch ID)
WatermarkTracker¶
MicroBatchExecution creates a WatermarkTracker while populating start offsets (when requested to run an activated streaming query).
The WatermarkTracker is used then for the following:
- Setting watermark while populating start offsets
- Reading the current watermark while the following:
- Updating watermark while running a single streaming micro-batch
isCurrentBatchConstructed¶
isCurrentBatchConstructed: Boolean
MicroBatchExecution uses isCurrentBatchConstructed flag to guard (skip) execution of constructNextBatch altogether (since, as the name says, a next batch has already been constructed).
isCurrentBatchConstructed is false initially (when MicroBatchExecution is created).
isCurrentBatchConstructed can change when MicroBatchExecution is requested for the following:
- populateStartOffsets while restarting the streaming query (and there is the latest batch in the offset log). If however the latest batch (in the offset log) was successfully processed (and committed to the commit log),
isCurrentBatchConstructedis changed tofalse
While running the activated streaming query, when false, isCurrentBatchConstructed lets constructing a next batch (that returns whether a next batch was constructed or not and that response becomes isCurrentBatchConstructed).
At the end of a trigger and with isCurrentBatchConstructed enabled, isCurrentBatchConstructed is reset to false.
Upon re-starting a streaming query from a checkpoint (using the Offset Write-Ahead Log) while populating start offsets (while running an activated streaming query), isCurrentBatchConstructed is true initially. isCurrentBatchConstructed can be set to false when the latest offset has already been successfully processed and committed (to the Offset Commit Log).
Used in finishTrigger.
getTrigger¶
getTrigger(): TriggerExecutor
Streaming Sources
getTrigger asserts that the sources have already been retrieved from the plan.
getTrigger creates a TriggerExecutor for this Trigger.
| Trigger | TriggerExecutor |
|---|---|
| ProcessingTimeTrigger | ProcessingTimeExecutor |
| OneTimeTrigger | SingleBatchExecutor |
| OneTimeTrigger | ProcessingTimeExecutor |
| AvailableNowTrigger |
IllegalStateException
getTrigger reports IllegalStateException for an unknown Trigger.
Unknown type of trigger: [trigger]
getTrigger is used when:
MicroBatchExecutionis requested for the LogicalPlan
Demo¶
import org.apache.spark.sql.streaming.Trigger
val query = spark
.readStream
.format("rate")
.load
.writeStream
.format("console") // <-- not a StreamWriteSupport sink
.option("truncate", false)
.trigger(Trigger.Once) // <-- Gives MicroBatchExecution
.queryName("rate2console")
.start
// The following gives access to the internals
// And to MicroBatchExecution
import org.apache.spark.sql.execution.streaming.StreamingQueryWrapper
val engine = query.asInstanceOf[StreamingQueryWrapper].streamingQuery
import org.apache.spark.sql.execution.streaming.StreamExecution
assert(engine.isInstanceOf[StreamExecution])
import org.apache.spark.sql.execution.streaming.MicroBatchExecution
val microBatchEngine = engine.asInstanceOf[MicroBatchExecution]
assert(microBatchEngine.trigger == Trigger.Once)
Logging¶
Enable ALL logging level for org.apache.spark.sql.execution.streaming.MicroBatchExecution logger to see what happens inside.
Add the following line to conf/log4j.properties:
log4j.logger.org.apache.spark.sql.execution.streaming.MicroBatchExecution=ALL
Refer to Logging.