ProgressReporter¶
ProgressReporter is an abstraction of execution progress reporters that report statistics of execution of a streaming query.
Contract¶
currentBatchId¶
currentBatchId: Long
ID of the micro-batch
Used when:
MicroBatchExecutionis requested to plan a query for the batch (while running a batch)ContinuousExecutionis requested to plan a query for the epoch (while running continuously)ProgressReporteris requested for a new StreamingQueryProgress (while finishing a trigger)- other usage
id¶
id: UUID
Universally unique identifier (UUID) of the streaming query (that remains unchanged between restarts)
lastExecution¶
lastExecution: QueryExecution
IncrementalExecution of the streaming execution round (a batch or an epoch)
IncrementalExecution is created and executed in the queryPlanning phase of MicroBatchExecution and ContinuousExecution stream execution engines.
logicalPlan¶
logicalPlan: LogicalPlan
Logical query plan of the streaming query
Important
The most interesting usage of the LogicalPlan is when stream execution engines replace (transform) input StreamingExecutionRelation and StreamingDataSourceV2Relation operators with (operators with) data or LocalRelation (to represent no data at a source).
Used when ProgressReporter is requested for the following:
- extract statistics from the most recent query execution (to add
watermarkmetric for streaming watermark) - extractSourceToNumInputRows
name¶
name: String
Name of the streaming query
newData¶
newData: Map[SparkDataStream, LogicalPlan]
SparkDataStreams (from all data sources) with the more recent unprocessed input data (as LogicalPlan)
Used exclusively for MicroBatchExecution (when requested to run a single micro-batch)
Used when ProgressReporter is requested to extractSourceToNumInputRows
offsetSeqMetadata¶
offsetSeqMetadata: OffsetSeqMetadata
OffsetSeqMetadata (with the current micro-batch event-time watermark and timestamp)
postEvent¶
postEvent(
event: StreamingQueryListener.Event): Unit
Posts StreamingQueryListener.Event
Used when:
ProgressReporteris requested to update progress (and posts a QueryProgressEvent)StreamExecutionis requested to run stream processing (and posts a QueryStartedEvent at the beginning and a QueryTerminatedEvent after a query has been stopped)
runId¶
runId: UUID
Universally unique identifier (UUID) of a single run of the streaming query (that changes every restart)
Sink¶
sink: Table
Table (Spark SQL) this streaming query writes to
Used when:
ProgressReporteris requested to finish a streaming batch
sinkCommitProgress¶
sinkCommitProgress: Option[StreamWriterCommitProgress]
StreamWriterCommitProgress with number of output rows:
-
NonewhenMicroBatchExecutionstream execution engine is requested to populateStartOffsets -
Assigned a
StreamWriterCommitProgresswhenMicroBatchExecutionstream execution engine is about to complete running a micro-batch
Used when finishTrigger (and updating progress)
SparkDataStreams¶
sources: Seq[SparkDataStream]
SparkDataStreams of this streaming query
sparkSession¶
sparkSession: SparkSession
SparkSession (Spark SQL) of the streaming query
triggerClock¶
triggerClock: Clock
Clock of the streaming query
Implementations¶
Demo¶
import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val sampleQuery = spark
.readStream
.format("rate")
.load
.writeStream
.format("console")
.option("truncate", false)
.trigger(Trigger.ProcessingTime(10.seconds))
.start
// Using public API
import org.apache.spark.sql.streaming.SourceProgress
scala> sampleQuery.
| lastProgress.
| sources.
| map { case sp: SourceProgress =>
| s"source = ${sp.description} => endOffset = ${sp.endOffset}" }.
| foreach(println)
source = RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8] => endOffset = 663
scala> println(sampleQuery.lastProgress.sources(0))
res40: org.apache.spark.sql.streaming.SourceProgress =
{
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : 333,
"endOffset" : 343,
"numInputRows" : 10,
"inputRowsPerSecond" : 0.9998000399920015,
"processedRowsPerSecond" : 200.0
}
// With a hack
import org.apache.spark.sql.execution.streaming.StreamingQueryWrapper
val offsets = sampleQuery.
asInstanceOf[StreamingQueryWrapper].
streamingQuery.
availableOffsets.
map { case (source, offset) =>
s"source = $source => offset = $offset" }
scala> offsets.foreach(println)
source = RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8] => offset = 293
StreamingQueryProgress Queue¶
progressBuffer: Queue[StreamingQueryProgress]
progressBuffer is a scala.collection.mutable.Queue of StreamingQueryProgresses.
progressBuffer has a new StreamingQueryProgress added when ProgressReporter is requested to update progress of a streaming query.
The oldest StreamingQueryProgress is removed (dequeued) above spark.sql.streaming.numRecentProgressUpdates threshold.
progressBuffer is used when ProgressReporter is requested for the last and the recent StreamingQueryProgresses.
Current StreamingQueryStatus¶
status: StreamingQueryStatus
status is the current StreamingQueryStatus.
status is used when StreamingQueryWrapper is requested for the current status of a streaming query.
Starting (Initializing) New Trigger¶
startTrigger(): Unit
startTrigger prints out the following DEBUG message to the logs:
Starting Trigger Calculation
.startTrigger's Internal Registry Changes For New Trigger [cols="30,70",options="header",width="100%"] |=== | Registry | New Value
| <
| <
| <true) the isTriggerActive flag of the <
| <null
| <null
| <
|===
startTrigger is used when:
-
MicroBatchExecutionstream execution engine is requested to run an activated streaming query (at the beginning of every trigger) -
ContinuousExecutionstream execution engine is requested to run an activated streaming query (at the beginning of every trigger)
StreamExecution starts running batches (as part of TriggerExecutor executing a batch runner).
Time-Tracking Section (Recording Execution Time)¶
reportTimeTaken[T](
triggerDetailKey: String)(
body: => T): T
reportTimeTaken measures the time to execute body and records it in the currentDurationsMs internal registry under triggerDetailKey key. If the triggerDetailKey key was recorded already, the current execution time is added.
In the end, reportTimeTaken prints out the following DEBUG message to the logs and returns the result of executing body.
[triggerDetailKey] took [time] ms
reportTimeTaken is used when stream execution engines are requested to execute the following phases (that appear as triggerDetailKey in the DEBUG message in the logs):
-
MicroBatchExecution -
ContinuousExecution
Updating Status Message¶
updateStatusMessage(
message: String): Unit
updateStatusMessage simply updates the message in the StreamingQueryStatus internal registry.
updateStatusMessage is used when:
-
StreamExecutionis requested to run stream processing -
MicroBatchExecutionis requested to run an activated streaming query or construct the next streaming micro-batch
Finishing Up Batch (Trigger)¶
finishTrigger(
hasNewData: Boolean,
hasExecuted: Boolean): Unit
finishTrigger updates progress with a new StreamingQueryProgress and resets the lastNoExecutionProgressEventTime (to the current time).
If the given hasExecuted flag is disabled, finishTrigger does the above only when lastNoDataProgressEventTime elapsed.
The given hasNewData and hasExecuted flags indicate the state of MicroBatchExecution.
| Input Flag | MicroBatchExecution |
|---|---|
hasNewData | currentBatchHasNewData |
hasExecuted | isCurrentBatchConstructed |
finishTrigger expects that the following are initialized or throws an AssertionError:
FIXME
Why is this so important?
finishTrigger sets currentTriggerEndTimestamp to the current time.
finishTrigger extractExecutionStats.
finishTrigger prints out the following DEBUG message to the logs:
Execution stats: [executionStats]
finishTrigger calculates the processing time (batchDuration) as the time difference between the end and start timestamps.
finishTrigger calculates the input time (in seconds) as the time difference between the start time of the current and last triggers (if there were two batches already) or the infinity.

For every unique SparkDataStream (in sources), finishTrigger creates a SourceProgress.
| SourceProgress | Value |
|---|---|
| description | A string representation of this SparkDataStream |
| startOffset | Looks up this SparkDataStream in currentTriggerStartOffsets |
| endOffset | Looks up this SparkDataStream in currentTriggerEndOffsets |
| latestOffset | Looks up this SparkDataStream in currentTriggerLatestOffsets |
| numInputRows | Looks up this SparkDataStream in the inputRows of ExecutionStats |
| inputRowsPerSecond | numInputRows divided by the input time |
| processedRowsPerSecond | numInputRows divided by the processing time |
| metrics | metrics for ReportsSourceMetrics data streams or empty |
finishTrigger creates a SinkProgress (sink statistics) for the sink Table.
finishTrigger extractObservedMetrics.
finishTrigger creates a StreamingQueryProgress.
With the given hasExecuted flag enabled, finishTrigger resets the lastNoExecutionProgressEventTime to the current time and updates progress (with the new StreamingQueryProgress).
Otherwise, with the given hasExecuted disabled, finishTrigger resets the lastNoExecutionProgressEventTime to the current time and updates progress (with the new StreamingQueryProgress) only when lastNoDataProgressEventTime elapsed.
In the end, finishTrigger turns isTriggerActive flag off of the StreamingQueryStatus.
finishTrigger is used when:
MicroBatchExecutionis requested to run the activated streaming query
Execution Statistics¶
extractExecutionStats(
hasNewData: Boolean,
hasExecuted: Boolean): ExecutionStats
extractExecutionStats generates an ExecutionStats of the last execution (of this streaming query).
hasNewData is exactly finishTrigger's hasNewData that is exactly isNewDataAvailable.
For the given hasNewData disabled, extractExecutionStats returns an ExecutionStats with the execution statistics:
- Empty input rows per data source
- State operator metrics
- Event-time statistics with
watermarkonly (and only if there is EventTimeWatermark in the query plan)
Otherwise, with the given hasNewData enabled, extractExecutionStats generates event-time statistics (with max, min, and avg statistics). extractStateOperatorMetrics collects all EventTimeWatermarkExec operators with non-empty EventTimeStats (from the optimized execution plan of the last QueryExecution).
In the end, extractExecutionStats creates an ExecutionStats with the execution statistics:
- Input rows per data source
- State operator metrics
- Event-time statistics (
max,min,avg,watermark)
State Operators Metrics¶
extractStateOperatorMetrics(
hasExecuted: Boolean): Seq[StateOperatorProgress]
extractStateOperatorMetrics returns no StateOperatorProgresss when the lastExecution is uninitialized.
extractStateOperatorMetrics requests the last QueryExecution for the optimized execution plan (Spark SQL).
extractStateOperatorMetrics traverses the execution plan and collects all StateStoreWriter operators that are requested to report progress.
When the given hasExecuted flag is enabled, extractStateOperatorMetrics leaves all the progress reports unchanged. Otherwise, extractStateOperatorMetrics clears (zero'es) the newNumRowsUpdated and newNumRowsDroppedByWatermark metrics.
ObservedMetrics¶
extractObservedMetrics(
hasNewData: Boolean,
lastExecution: QueryExecution): Map[String, Row]
extractObservedMetrics returns the observedMetrics from the given QueryExecution when either the given hasNewData flag is enabled (true) or the given QueryExecution is initialized.
Updating Stream Progress¶
updateProgress(
newProgress: StreamingQueryProgress): Unit
updateProgress records the input newProgress and posts a QueryProgressEvent event.
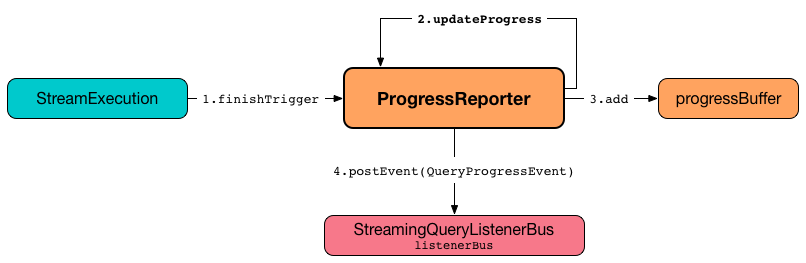
updateProgress adds the input newProgress to progressBuffer.
updateProgress removes elements from progressBuffer if their number is or exceeds the value of spark.sql.streaming.numRecentProgressUpdates configuration property.
updateProgress posts a QueryProgressEvent (with the input newProgress).
updateProgress prints out the following INFO message to the logs:
Streaming query made progress: [newProgress]
lastNoExecutionProgressEventTime¶
lastNoExecutionProgressEventTime: Long
ProgressReporter initializes lastNoExecutionProgressEventTime internal time marker to the minimum timestamp when created.
lastNoExecutionProgressEventTime is the time when finishTrigger happens and hasExecuted flag is enabled. Otherwise, lastNoExecutionProgressEventTime is reset only when noDataProgressEventInterval threshold has been reached.
noDataProgressEventInterval¶
ProgressReporter uses spark.sql.streaming.noDataProgressEventInterval configuration property to control whether to updateProgress or not when requested to finish up a trigger.
Whether to updateProgress or not is driven by whether a batch was executed based on isCurrentBatchConstructed and how much time passed since the last updateProgress.
Recording Trigger Offsets (StreamProgresses)¶
recordTriggerOffsets(
from: StreamProgress,
to: StreamProgress,
latest: StreamProgress): Unit
recordTriggerOffsets updates (records) the following registries with the given StreamProgress (and with the values JSON-fied).
| Registry | StreamProgress |
|---|---|
| currentTriggerStartOffsets | from |
| currentTriggerEndOffsets | to |
| currentTriggerLatestOffsets | latest |
In the end, recordTriggerOffsets updates (records) the latestStreamProgress registry to be to.
recordTriggerOffsets is used when:
MicroBatchExecutionis requested to run the activated streaming queryContinuousExecutionis requested to commit an epoch
Last StreamingQueryProgress¶
lastProgress: StreamingQueryProgress
The last StreamingQueryProgress
currentDurationsMs¶
currentDurationsMs: HashMap[String, Long]
ProgressReporter creates a currentDurationsMs registry (Scala's collection.mutable.HashMap) with action names (aka triggerDetailKey) and their cumulative execution times (in millis).
currentDurationsMs is initialized empty when ProgressReporter sets the state for a new batch with new entries added or updated when reporting execution time (of an execution phase).
currentDurationsMs is available as durationMs of a StreamingQueryProgress of a StreamingQuery.
assert(stream.isInstanceOf[org.apache.spark.sql.streaming.StreamingQuery])
assert(stream.lastProgress.isInstanceOf[org.apache.spark.sql.streaming.StreamingQueryProgress])
scala> println(stream.lastProgress.durationMs)
{triggerExecution=122, queryPlanning=3, getBatch=1, latestOffset=0, addBatch=36, walCommit=42}
scala> println(stream.lastProgress)
{
"id" : "4976adb3-e8a6-4c4d-b895-912808013992",
"runId" : "9cdd9f2c-15bc-41c3-899b-42bcc1e994de",
"name" : null,
"timestamp" : "2022-10-13T10:03:30.000Z",
"batchId" : 10,
"numInputRows" : 15,
"inputRowsPerSecond" : 1.000333444481494,
"processedRowsPerSecond" : 122.95081967213115,
"durationMs" : {
"addBatch" : 37,
"getBatch" : 0,
"latestOffset" : 0,
"queryPlanning" : 4,
"triggerExecution" : 122,
"walCommit" : 42
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateStreamV2[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=default",
"startOffset" : 127,
"endOffset" : 142,
"latestOffset" : 142,
"numInputRows" : 15,
"inputRowsPerSecond" : 1.000333444481494,
"processedRowsPerSecond" : 122.95081967213115
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleTable$@396a0033",
"numOutputRows" : 15
}
}
Current Trigger's Start Offsets (by SparkDataStream)¶
currentTriggerStartOffsets: Map[SparkDataStream, String]
currentTriggerStartOffsets is a collection of Offsets (in JSON format) of every SparkDataStream (in this streaming query) at the beginning of the following:
currentTriggerStartOffsets is reset (null-ified) upon starting a new trigger.
currentTriggerStartOffsets is updated (initialized) to committedOffsets upon recording offsets.
ProgressReporter makes sure that currentTriggerStartOffsets is initialized when finishing a trigger to create a SourceProgress (startOffset).
Internal Properties¶
currentTriggerEndTimestamp¶
Timestamp of when the current batch/trigger has ended
Default: -1L
currentTriggerStartTimestamp¶
Timestamp of when the current batch/trigger has started
Default: -1L
lastTriggerStartTimestamp¶
Timestamp of when the last batch/trigger started
Default: -1L
Logging¶
ProgressReporter is an abstract class and logging is configured using the logger of the implementations.