Spark Standalone¶
Spark Standalone (Standalone Cluster) is Spark's own built-in cluster environment. Since Spark Standalone is available in the default distribution of Apache Spark it is the easiest way to run your Spark applications in a clustered environment in many cases.
Standalone Master (standalone Master) is the resource manager for the Spark Standalone cluster.
Standalone Worker is a worker in a Spark Standalone cluster. There can be one or many workers in a standalone cluster.
In Standalone cluster mode Spark allocates resources based on cores. By default, an application will grab all the cores in the cluster.
Standalone cluster mode is subject to the constraint that only one executor can be allocated on each worker per application.
A Spark Standalone cluster is available using spark://-prefixed master URL.
Round-robin Scheduling Across Nodes¶
If enabled (using spark.deploy.spreadOut), standalone Master attempts to spread out an application's executors on as many workers as possible (instead of trying to consolidate it onto a small number of nodes).
scheduleExecutorsOnWorkers¶
scheduleExecutorsOnWorkers(
app: ApplicationInfo,
usableWorkers: Array[WorkerInfo],
spreadOutApps: Boolean): Array[Int]
scheduleExecutorsOnWorkers schedules executors on workers.
SPARK_WORKER_INSTANCES (and SPARK_WORKER_CORES)¶
There is really no need to run multiple workers per machine in Spark 1.5 (perhaps in 1.4, too). You can run multiple executors on the same machine with one worker.
Use SPARK_WORKER_INSTANCES (default: 1) in spark-env.sh to define the number of worker instances.
If you use SPARK_WORKER_INSTANCES, make sure to set SPARK_WORKER_CORES explicitly to limit the cores per worker, or else each worker will try to use all the cores.
You can set up the number of cores as an command line argument when you start a worker daemon using --cores.
Multiple executors per worker in Standalone mode¶
CAUTION: It can be a duplicate of the above section.
It is possible to start multiple executors in a single JVM process of a worker.
To launch multiple executors on a machine you start multiple standalone workers, each with its own JVM. It introduces unnecessary overhead due to these JVM processes, provided that there are enough cores on that worker.
If you are running Spark in standalone mode on memory-rich nodes it can be beneficial to have multiple worker instances on the same node as a very large heap size has two disadvantages:
- Garbage collector pauses can hurt throughput of Spark jobs.
- Heap size of >32 GB can’t use CompressedOoops. So 35 GB is actually less than 32 GB.
Mesos and YARN can, out of the box, support packing multiple, smaller executors onto the same physical host, so requesting smaller executors doesn’t mean your application will have fewer overall resources.
SparkDeploySchedulerBackend¶
SparkDeploySchedulerBackend is the xref:scheduler:SchedulerBackend.md[Scheduler Backend] for Spark Standalone, i.e. it is used when you xref:ROOT:SparkContext.md#creating-instance[create a SparkContext] using spark:// master URL.
It is a specialized xref:scheduler:CoarseGrainedSchedulerBackend.md[CoarseGrainedSchedulerBackend] that uses <AppClientListener.
.SparkDeploySchedulerBackend.start() (while SparkContext starts) image::SparkDeploySchedulerBackend-AppClient-start.png[align="center"]
CAUTION: FIXME AppClientListener & ApplicationDescription
It uses <
AppClient¶
AppClient is an interface to allow Spark applications to talk to a Standalone cluster (using a RPC Environment). It takes an RPC Environment, a collection of master URLs, a ApplicationDescription, and a AppClientListener.
It is solely used by <
AppClient registers AppClient RPC endpoint (using ClientEndpoint class) to a given RPC Environment.
AppClient uses a daemon cached thread pool (askAndReplyThreadPool) with threads' name in the format of appclient-receive-and-reply-threadpool-ID, where ID is a unique integer for asynchronous asks and replies. It is used for requesting executors (via RequestExecutors message) and kill executors (via KillExecutors).
sendToMaster sends one-way ExecutorStateChanged and UnregisterApplication messages to master.
Initialization - AppClient.start() method¶
When AppClient starts, AppClient.start() method is called that merely registers <
AppClient RPC Endpoint¶
AppClient RPC endpoint is started as part of <
It is a ThreadSafeRpcEndpoint that knows about the RPC endpoint of the primary active standalone Master (there can be a couple of them, but only one can be active and hence primary).
When it starts, it sends <
RegisterApplication RPC message¶
An AppClient registers the Spark application to a single master (regardless of the number of the standalone masters given in the master URL).
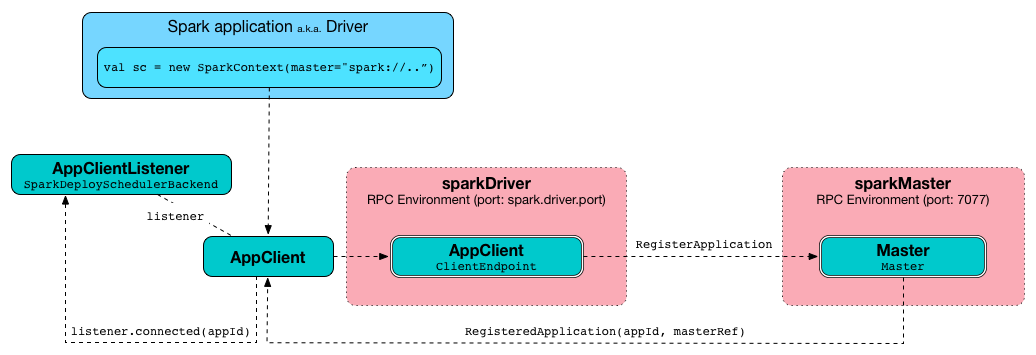
It uses a dedicated thread pool appclient-register-master-threadpool to asynchronously send RegisterApplication messages, one per standalone master.
Connecting to master spark://localhost:7077...
An AppClient tries connecting to a standalone master 3 times every 20 seconds per master before giving up. They are not configurable parameters.
The appclient-register-master-threadpool thread pool is used until the registration is finished, i.e. AppClient is connected to the primary standalone Master or the registration fails. It is then shutdown.
RegisteredApplication RPC message¶
RegisteredApplication is a one-way message from the primary master to confirm successful application registration. It comes with the application id and the master's RPC endpoint reference.
The AppClientListener gets notified about the event via listener.connected(appId) with appId being an application id.
ApplicationRemoved RPC message¶
ApplicationRemoved is received from the primary master to inform about having removed the application. AppClient RPC endpoint is stopped afterwards.
It can come from the standalone Master after a kill request from Web UI, application has finished properly or the executor where the application was still running on has been killed, failed, lost or exited.
ExecutorAdded RPC message¶
ExecutorAdded is received from the primary master to inform about...FIXME
CAUTION: FIXME the message
Executor added: %s on %s (%s) with %d cores
ExecutorUpdated RPC message¶
ExecutorUpdated is received from the primary master to inform about...FIXME
CAUTION: FIXME the message
Executor updated: %s is now %s%s
MasterChanged RPC message¶
MasterChanged is received from the primary master to inform about...FIXME
CAUTION: FIXME the message
Master has changed, new master is at
StopAppClient RPC message¶
StopAppClient is a reply-response message from the SparkDeploySchedulerBackend to stop the AppClient after the SparkContext has been stopped (and so should the running application on the standalone cluster).
It stops the AppClient RPC endpoint.
RequestExecutors RPC message¶
RequestExecutors is a reply-response message from the SparkDeploySchedulerBackend that is passed on to the master to request executors for the application.
KillExecutors RPC message¶
KillExecutors is a reply-response message from the SparkDeploySchedulerBackend that is passed on to the master to kill executors assigned to the application.