WindowExec Unary Physical Operator¶
WindowExec is a WindowExecBase unary physical operator for window function execution.
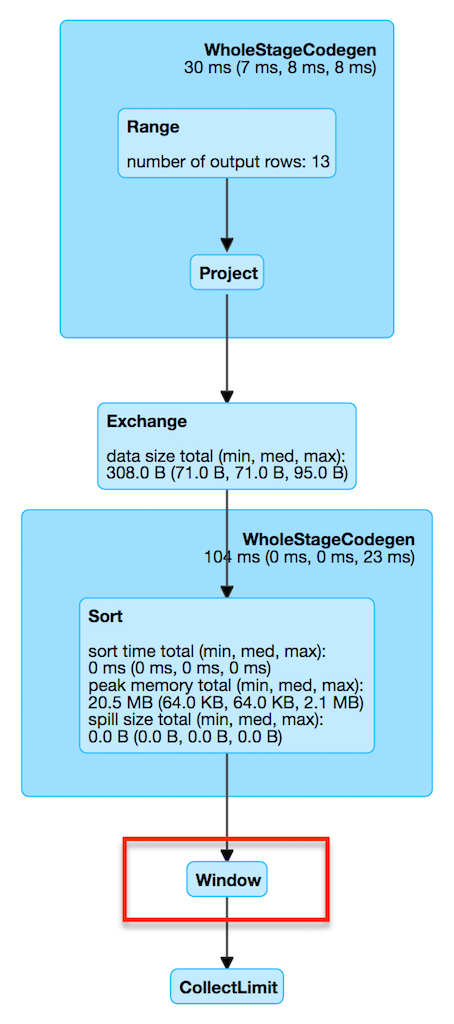
WindowExec represents Window unary logical operator at execution time.
WindowExec uses ExternalAppendOnlyUnsafeRowArray when executed. This ExternalAppendOnlyUnsafeRowArray can be fine-tuned using the Configuration Properties.
Creating Instance¶
WindowExec takes the following to be created:
- Window NamedExpression
- Partition Specification (Expressions)
- SortOrders
- Child SparkPlan
WindowExec is created when:
- Window execution planning strategy plans a Window unary logical operator with a WindowFunction or an AggregateFunction
Performance Metrics¶
spill size¶
Configuration Properties¶
WindowExec uses the following configuration properties when executed.
spark.sql.windowExec.buffer.in.memory.threshold¶
spark.sql.windowExec.buffer.in.memory.threshold
spark.sql.windowExec.buffer.spill.threshold¶
spark.sql.windowExec.buffer.spill.threshold
Executing Operator¶
doExecute requests the child physical operator to execute (to create a RDD[InternalRow]) and uses RDD.mapPartitions operator to process partition rows.
Note
When executed, doExecute creates a new MapPartitionsRDD with the RDD[InternalRow] of the child physical operator.
scala> :type we
org.apache.spark.sql.execution.window.WindowExec
val windowRDD = we.execute
scala> :type windowRDD
org.apache.spark.rdd.RDD[org.apache.spark.sql.catalyst.InternalRow]
scala> println(windowRDD.toDebugString)
(200) MapPartitionsRDD[5] at execute at <console>:35 []
| MapPartitionsRDD[4] at execute at <console>:35 []
| ShuffledRowRDD[3] at execute at <console>:35 []
+-(7) MapPartitionsRDD[2] at execute at <console>:35 []
| MapPartitionsRDD[1] at execute at <console>:35 []
| ParallelCollectionRDD[0] at execute at <console>:35 []
doExecute creates an Iterator[InternalRow] (of UnsafeRow exactly).
Demo¶
// arguably the most trivial example
// just a dataset of 3 rows per group
// to demo how partitions and frames work
// note the rows per groups are not consecutive (in the middle)
val metrics = Seq(
(0, 0, 0), (1, 0, 1), (2, 5, 2), (3, 0, 3), (4, 0, 1), (5, 5, 3), (6, 5, 0)
).toDF("id", "device", "level")
scala> metrics.show
+---+------+-----+
| id|device|level|
+---+------+-----+
| 0| 0| 0|
| 1| 0| 1|
| 2| 5| 2| // <-- this row for device 5 is among the rows of device 0
| 3| 0| 3| // <-- as above but for device 0
| 4| 0| 1| // <-- almost as above but there is a group of two rows for device 0
| 5| 5| 3|
| 6| 5| 0|
+---+------+-----+
// create windows of rows to use window aggregate function over every window
import org.apache.spark.sql.expressions.Window
val rangeWithTwoDevicesById = Window.
partitionBy('device).
orderBy('id).
rangeBetween(start = -1, end = Window.currentRow) // <-- demo rangeBetween first
val sumOverRange = metrics.withColumn("sum", sum('level) over rangeWithTwoDevicesById)
// Logical plan with Window unary logical operator
val optimizedPlan = sumOverRange.queryExecution.optimizedPlan
scala> println(optimizedPlan)
Window [sum(cast(level#9 as bigint)) windowspecdefinition(device#8, id#7 ASC NULLS FIRST, RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#15L], [device#8], [id#7 ASC NULLS FIRST]
+- LocalRelation [id#7, device#8, level#9]
// Physical plan with WindowExec unary physical operator (shown as Window)
scala> sumOverRange.explain
== Physical Plan ==
Window [sum(cast(level#9 as bigint)) windowspecdefinition(device#8, id#7 ASC NULLS FIRST, RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#15L], [device#8], [id#7 ASC NULLS FIRST]
+- *Sort [device#8 ASC NULLS FIRST, id#7 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(device#8, 200)
+- LocalTableScan [id#7, device#8, level#9]
// Going fairly low-level...you've been warned
val plan = sumOverRange.queryExecution.executedPlan
import org.apache.spark.sql.execution.window.WindowExec
val we = plan.asInstanceOf[WindowExec]
val windowRDD = we.execute()
scala> :type windowRDD
org.apache.spark.rdd.RDD[org.apache.spark.sql.catalyst.InternalRow]
scala> windowRDD.toDebugString
res0: String =
(200) MapPartitionsRDD[5] at execute at <console>:35 []
| MapPartitionsRDD[4] at execute at <console>:35 []
| ShuffledRowRDD[3] at execute at <console>:35 []
+-(7) MapPartitionsRDD[2] at execute at <console>:35 []
| MapPartitionsRDD[1] at execute at <console>:35 []
| ParallelCollectionRDD[0] at execute at <console>:35 []
// no computation on the source dataset has really occurred
// Let's trigger a RDD action
scala> windowRDD.first
res0: org.apache.spark.sql.catalyst.InternalRow = [0,2,5,2,2]
scala> windowRDD.foreach(println)
[0,2,5,2,2]
[0,0,0,0,0]
[0,5,5,3,3]
[0,6,5,0,3]
[0,1,0,1,1]
[0,3,0,3,3]
[0,4,0,1,4]
scala> sumOverRange.show
+---+------+-----+---+
| id|device|level|sum|
+---+------+-----+---+
| 2| 5| 2| 2|
| 5| 5| 3| 3|
| 6| 5| 0| 3|
| 0| 0| 0| 0|
| 1| 0| 1| 1|
| 3| 0| 3| 3|
| 4| 0| 1| 4|
+---+------+-----+---+
// use rowsBetween
val rowsWithTwoDevicesById = Window.
partitionBy('device).
orderBy('id).
rowsBetween(start = -1, end = Window.currentRow)
val sumOverRows = metrics.withColumn("sum", sum('level) over rowsWithTwoDevicesById)
// let's see the result first to have them close
// and compare row- vs range-based windows
scala> sumOverRows.show
+---+------+-----+---+
| id|device|level|sum|
+---+------+-----+---+
| 2| 5| 2| 2|
| 5| 5| 3| 5| <-- a difference
| 6| 5| 0| 3|
| 0| 0| 0| 0|
| 1| 0| 1| 1|
| 3| 0| 3| 4| <-- another difference
| 4| 0| 1| 4|
+---+------+-----+---+
val rowsOptimizedPlan = sumOverRows.queryExecution.optimizedPlan
scala> println(rowsOptimizedPlan)
Window [sum(cast(level#901 as bigint)) windowspecdefinition(device#900, id#899 ASC NULLS FIRST, ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#1458L], [device#900], [id#899 ASC NULLS FIRST]
+- LocalRelation [id#899, device#900, level#901]
scala> sumOverRows.explain
== Physical Plan ==
Window [sum(cast(level#901 as bigint)) windowspecdefinition(device#900, id#899 ASC NULLS FIRST, ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#1458L], [device#900], [id#899 ASC NULLS FIRST]
+- *Sort [device#900 ASC NULLS FIRST, id#899 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(device#900, 200)
+- LocalTableScan [id#899, device#900, level#901]
// a more involved example
val dataset = spark.range(start = 0, end = 13, step = 1, numPartitions = 4)
import org.apache.spark.sql.expressions.Window
val groupsOrderById = Window.partitionBy('group).rangeBetween(-2, Window.currentRow).orderBy('id)
val query = dataset.
withColumn("group", 'id % 4).
select('*, sum('id) over groupsOrderById as "sum")
scala> query.explain
== Physical Plan ==
Window [sum(id#25L) windowspecdefinition(group#244L, id#25L ASC NULLS FIRST, RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum#249L], [group#244L], [id#25L ASC NULLS FIRST]
+- *Sort [group#244L ASC NULLS FIRST, id#25L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(group#244L, 200)
+- *Project [id#25L, (id#25L % 4) AS group#244L]
+- *Range (0, 13, step=1, splits=4)
val plan = query.queryExecution.executedPlan
import org.apache.spark.sql.execution.window.WindowExec
val we = plan.asInstanceOf[WindowExec]
// the whole schema is as follows
val schema = query.queryExecution.executedPlan.output.toStructType
scala> println(schema.treeString)
root
|-- id: long (nullable = false)
|-- group: long (nullable = true)
|-- sum: long (nullable = true)
// Let's see ourselves how the schema is made up of
scala> :type we
org.apache.spark.sql.execution.window.WindowExec
// child's output
scala> println(we.child.output.toStructType.treeString)
root
|-- id: long (nullable = false)
|-- group: long (nullable = true)
// window expressions' output
val weExprSchema = we.windowExpression.map(_.toAttribute).toStructType
scala> println(weExprSchema.treeString)
root
|-- sum: long (nullable = true)
ROWS BETWEEN¶
val vs = Seq(
(1,0), (1,1), (1,3), (2, 0), (2,4)).toDF("gid", "v")
scala> vs.show
+---+---+
|gid| v|
+---+---+
| 1| 0|
| 1| 1|
| 1| 3|
| 2| 0|
| 2| 4|
+---+---+
import org.apache.spark.sql.expressions.Window
val byRowsBetween = Window
.partitionBy('gid)
.orderBy('v)
.rowsBetween(-1, Window.currentRow)
val q = vs.withColumn("vs", collect_list('v).over(byRowsBetween))
scala> q.show
+---+---+---------+
|gid| v| vs|
+---+---+---------+
| 1| 0|[0, 1, 3]|
| 1| 1|[0, 1, 3]|
| 1| 3|[0, 1, 3]|
| 2| 0| [0, 4]|
| 2| 4| [0, 4]|
+---+---+---------+
RANGE BETWEEN¶
val vs = Seq(
(1,0), (1,1), (1,3), (2, 0), (2,4)).toDF("gid", "v")
scala> vs.show
+---+---+
|gid| v|
+---+---+
| 1| 0|
| 1| 1|
| 1| 3|
| 2| 0|
| 2| 4|
+---+---+
import org.apache.spark.sql.expressions.Window
val byRangeBetween = Window
.partitionBy('gid)
.orderBy('v)
.rangeBetween(Window.unboundedPreceding, Window.unboundedFollowing)
val q = vs.withColumn("vs", collect_list('v).over(byRangeBetween))
scala> q.show
+---+---+---------+
|gid| v| vs|
+---+---+---------+
| 1| 0|[0, 1, 3]|
| 1| 1|[0, 1, 3]|
| 1| 3|[0, 1, 3]|
| 2| 0| [0, 4]|
| 2| 4| [0, 4]|
+---+---+---------+
Logging¶
Enable ALL logging level for org.apache.spark.sql.execution.WindowExec logger to see what happens inside.
Add the following line to conf/log4j2.properties:
log4j.logger.org.apache.spark.sql.execution.WindowExec=ALL
Refer to Logging.