SparkPlan — Physical Operators of Structured Query¶
SparkPlan is an extension of the QueryPlan abstraction for physical operators that can be executed (to generate RDD[InternalRow] that Spark can execute).
SparkPlan can build a physical query plan (query execution plan).
SparkPlan is a recursive data structure in Spark SQL's Catalyst tree manipulation framework and as such represents a single physical operator in a physical execution query plan as well as a physical execution query plan itself (i.e. a tree of physical operators in a query plan of a structured query).
High-Level Dataset API
A structured query can be expressed using Spark SQL's high-level Dataset API for Scala, Java, Python, R or good ol' SQL.
A SparkPlan physical operator is a Catalyst tree node that may have zero or more child physical operators.
Catalyst Framework
A structured query is basically a single SparkPlan physical operator with child physical operators.
Spark SQL uses Catalyst tree manipulation framework to compose nodes to build a tree of (logical or physical) operators that, in this particular case, is composing SparkPlan physical operator nodes to build the physical execution plan tree of a structured query.
explain Operator
Use explain operator to see the execution plan of a structured query.
val q = // your query here
q.explain
You may also access the execution plan of a Dataset using its queryExecution property.
val q = // your query here
q.queryExecution.sparkPlan
SparkPlan assumes that concrete physical operators define doExecute (with optional hooks).
Contract¶
Executing Operator¶
doExecute(): RDD[InternalRow]
Generates a distributed computation (that is a runtime representation of the operator in particular and a structured query in general) as an RDD of InternalRows (RDD[InternalRow]) and thus execute.
Part of execute
See:
Implementations¶
Final Methods¶
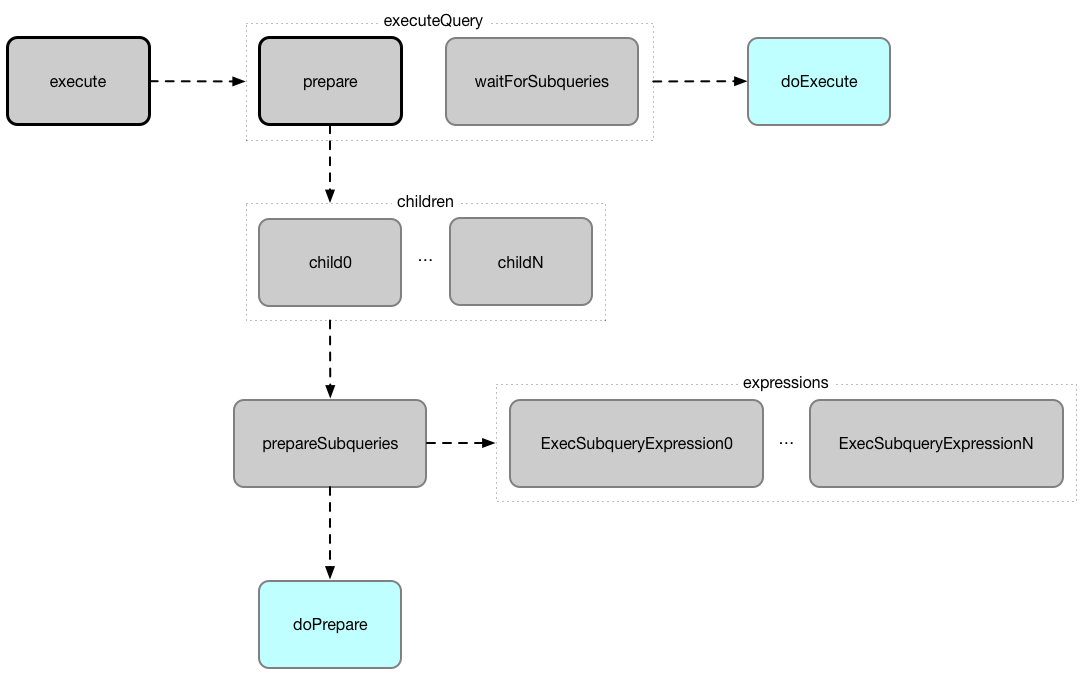
SparkPlan has the following final methods that prepare execution environment and pass calls to corresponding methods (that constitute SparkPlan abstraction).
execute¶
execute(): RDD[InternalRow]
"Executes" a physical operator (and its children) that triggers physical query planning and in the end generates an RDD of InternalRows (RDD[InternalRow]).
Used mostly when QueryExecution is requested for the <
execute is called when QueryExecution is requested for the RDD that is Spark Core's physical execution plan (as a RDD lineage) that triggers query execution (i.e. physical planning, but not execution of the plan) and could be considered execution of a structured query.
The could part above refers to the fact that the final execution of a structured query happens only when a RDD action is executed on the RDD of a structured query. And hence the need for Spark SQL's high-level Dataset API in which the Dataset operators simply execute a RDD action on the corresponding RDD. Easy, isn't it?
Internally, execute first <
Note
Executing doExecute in a named scope happens only after the operator is <
executeBroadcast¶
executeBroadcast[T](): broadcast.Broadcast[T]
Calls doExecuteBroadcast.
executeColumnar¶
executeColumnar(): RDD[ColumnarBatch]
executeColumnar executeQuery with doExecuteColumnar.
executeColumnar is used when:
- ColumnarToRowExec unary physical operator is executed and requested for the inputRDDs
executeQuery¶
executeQuery[T](
query: => T): T
Executes the physical operator in a single RDD scope (all RDDs created during execution of the physical operator have the same scope).
executeQuery executes the input query block after the following (in order):
executeQuery is used when:
SparkPlanis requested for the following:- execute (the input
queryis doExecute) - executeBroadcast (the input
queryis doExecuteBroadcast) - executeColumnar (the input
queryis doExecuteColumnar()) CodegenSupportis requested to produce a Java source code of a physical operator (with the inputquerybeing doProduce)QueryStageExecis requested to materialize (with the inputquerybeing doMaterialize)
executeWrite¶
executeWrite(
writeFilesSpec: WriteFilesSpec): RDD[WriterCommitMessage]
executeWrite executeQuery followed by doExecuteWrite.
Used when:
FileFormatWriteris requested to executeWrite
prepare¶
prepare(): Unit
Prepares a physical operator for execution
prepare is used mainly when a physical operator is requested to <
prepare is also used recursively for every child physical operator (down the physical plan) and when a physical operator is requested to <
Note
prepare is idempotent, i.e. can be called multiple times with no change to the final result. It uses <
Internally, prepare calls <
logicalLink¶
logicalLink: Option[LogicalPlan]
logicalLink gets the value of logical_plan node tag (if defined) or logical_plan_inherited node tag.
In other words, logicalLink is the LogicalPlan this SparkPlan was planned from.
logicalLink is used when:
AdaptiveSparkPlanExecphysical operator is requested for the final physical plan, setLogicalLinkForNewQueryStage and replaceWithQueryStagesInLogicalPlan- InsertAdaptiveSparkPlan, PlanAdaptiveDynamicPruningFilters and DisableUnnecessaryBucketedScan physical optimizations are executed
Extension Hooks¶
doExecuteBroadcast¶
doExecuteBroadcast[T](): broadcast.Broadcast[T]
doExecuteBroadcast reports an UnsupportedOperationException by default:
[nodeName] does not implement doExecuteBroadcast
Part of executeBroadcast
doExecuteColumnar¶
doExecuteColumnar(): RDD[ColumnarBatch]
doExecuteColumnar throws an IllegalStateException by default:
Internal Error [class] has column support mismatch:
[this]
Part of Columnar Execution
doExecuteWrite¶
doExecuteWrite(
writeFilesSpec: WriteFilesSpec): RDD[WriterCommitMessage]
Throws SparkException by Default
doExecuteColumnar throws an SparkException by default and is supposed to be overriden by the implementations.
Internal Error [class] has write support mismatch:
[this]
Used by executeWrite
See:
doPrepare¶
doPrepare(): Unit
doPrepare prepares the physical operator for execution
Part of prepare
Required Child Output Distribution¶
requiredChildDistribution: Seq[Distribution]
Required Partition Requirements (child output distributions) of the input data, i.e. how child physical operators' output is split across partitions.
Defaults to a UnspecifiedDistribution for all of the child operators.
Used when:
- EnsureRequirements physical optimization is executed
Required Child Ordering¶
requiredChildOrdering: Seq[Seq[SortOrder]]
Specifies required sort ordering for every partition of the input data for this operator (from child operators)
Defaults to no sort ordering from all the children of this operator
Seq[Seq[SortOrder]] Return Type
Seq[Seq[SortOrder]] allows specifying sort ordering per every child and then every partition (of every child operator's output).
In other words, for unary physical operators there will only be a single Seq[SortOrder] within the top-level Seq[...], if at all.
See:
Used when:
- EnsureRequirements physical optimization is executed
- OptimizeSkewedJoin physical optimization is executed (indirectly through
ValidateRequirements)
Preparing Subqueries¶
prepareSubqueries(): Unit
prepareSubqueries...FIXME
Part of prepare
Waiting for Subqueries to Finish¶
waitForSubqueries(): Unit
waitForSubqueries requests every subquery expression (in runningSubqueries registry) to update.
In the end, waitForSubqueries clears up the runningSubqueries registry.
waitForSubqueries is used when:
- A physical operator is requested to executeQuery
Naming Convention (Exec Suffix)¶
The naming convention of physical operators in Spark's source code is to have their names end with the Exec prefix, e.g. DebugExec or LocalTableScanExec that is however removed when the operator is displayed, e.g. in web UI.
Physical Operator Execution Pipeline¶
The entry point to Physical Operator Execution Pipeline is execute.
When <SparkPlan <
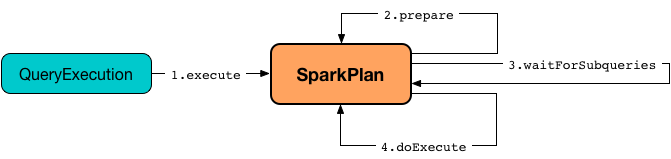
The result of <SparkPlan is an RDD of InternalRows (RDD[InternalRow]).
Note
Executing a structured query is simply a translation of the higher-level Dataset-based description to an RDD-based runtime representation that Spark will in the end execute (once an Dataset action is used).
CAUTION: FIXME Picture between Spark SQL's Dataset => Spark Core's RDD
Decoding Byte Arrays Back to UnsafeRows¶
decodeUnsafeRows(
bytes: Array[Byte]): Iterator[InternalRow]
decodeUnsafeRows...FIXME
decodeUnsafeRows is used when:
SparkPlanis requested to executeCollect, executeCollectIterator, executeToIterator, and executeTake
Compressing RDD Partitions (of UnsafeRows) to Byte Arrays¶
getByteArrayRdd(
n: Int = -1,
takeFromEnd: Boolean = false): RDD[(Long, Array[Byte])]
getByteArrayRdd executes this operator and maps over partitions (Spark Core) using the partition processing function.
Note
getByteArrayRdd adds a MapPartitionsRDD (Spark Core) to the RDD lineage.
getByteArrayRdd is used when:
SparkPlanis requested to executeCollect, executeCollectIterator, executeToIterator, and executeTake
Partition Processing Function¶
The function creates a CompressionCodec (Spark Core) (to compress the output to a byte array).
The function takes UnsafeRows from the partition (one at a time) and writes them out (compressed) to the output as a series of the size and the bytes of a single row.
Once all rows have been processed, the function writes out -1 to the output, flushes and closes it.
In the end, the function returns the count of the rows written out and the byte array (with the rows).
Preparing SparkPlan for Query Execution¶
executeQuery[T](
query: => T): T
executeQuery executes the input query in a named scope (i.e. so that all RDDs created will have the same scope for visualization like web UI).
Internally, executeQuery calls <query.
executeQuery is executed as part of <CodegenSupport-enabled physical operator produces a Java source code.
Broadcasting Result of Structured Query¶
executeBroadcast[T](): broadcast.Broadcast[T]
executeBroadcast returns the result of a structured query as a broadcast variable.
Internally, executeBroadcast calls doExecuteBroadcast inside executeQuery.
executeBroadcast is used when:
SubqueryBroadcastExecphysical operator is requested forrelationFuture- QueryStageExec physical operator is requested for doExecuteBroadcast
- DebugExec physical operator is requested for doExecuteBroadcast
- ReusedExchangeExec physical operator is requested for doExecuteBroadcast
- BroadcastHashJoinExec physical operator is requested to doExecute, multipleOutputForOneInput, prepareBroadcast and for doExecuteBroadcast
- BroadcastNestedLoopJoinExec physical operator is requested for doExecuteBroadcast
Performance Metrics¶
metrics: Map[String, SQLMetric] = Map.empty
metrics is the SQLMetrics by their names.
By default, metrics contains no SQLMetrics (i.e. Map.empty).
metrics is used when...FIXME
Taking First N UnsafeRows¶
executeTake(
n: Int): Array[InternalRow]
executeTake gives an array of up to n first internal rows.
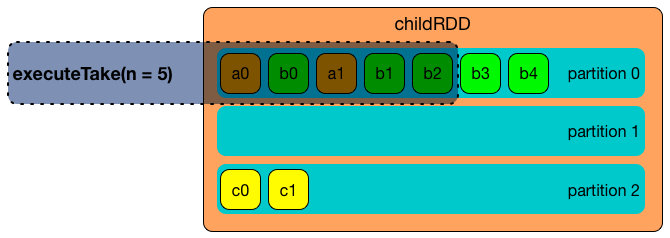
executeTake gets an RDD of byte array of n unsafe rows and scans the RDD partitions one by one until n is reached or all partitions were processed.
executeTake runs Spark jobs that take all the elements from requested number of partitions, starting from the 0th partition and increasing their number by spark.sql.limit.scaleUpFactor property (but minimum twice as many).
Note
executeTake uses SparkContext.runJob to run a Spark job.
In the end, executeTake decodes the unsafe rows.
Note
executeTake gives an empty collection when n is 0 (and no Spark job is executed).
Note
executeTake may take and decode more unsafe rows than really needed since all unsafe rows from a partition are read (if the partition is included in the scan).
Demo¶
import org.apache.spark.sql.internal.SQLConf.SHUFFLE_PARTITIONS
spark.sessionState.conf.setConf(SHUFFLE_PARTITIONS, 10)
// 8 groups over 10 partitions
// only 7 partitions are with numbers
val nums = spark.
range(start = 0, end = 20, step = 1, numPartitions = 4).
repartition($"id" % 8)
import scala.collection.Iterator
val showElements = (it: Iterator[java.lang.Long]) => {
val ns = it.toSeq
import org.apache.spark.TaskContext
val pid = TaskContext.get.partitionId
println(s"[partition: $pid][size: ${ns.size}] ${ns.mkString(" ")}")
}
// ordered by partition id manually for demo purposes
scala> nums.foreachPartition(showElements)
[partition: 0][size: 2] 4 12
[partition: 1][size: 2] 7 15
[partition: 2][size: 0]
[partition: 3][size: 0]
[partition: 4][size: 0]
[partition: 5][size: 5] 0 6 8 14 16
[partition: 6][size: 0]
[partition: 7][size: 3] 3 11 19
[partition: 8][size: 5] 2 5 10 13 18
[partition: 9][size: 3] 1 9 17
scala> println(spark.sessionState.conf.limitScaleUpFactor)
4
// Think how many Spark jobs will the following queries run?
// Answers follow
scala> nums.take(13)
res0: Array[Long] = Array(4, 12, 7, 15, 0, 6, 8, 14, 16, 3, 11, 19, 2)
// The number of Spark jobs = 3
scala> nums.take(5)
res34: Array[Long] = Array(4, 12, 7, 15, 0)
// The number of Spark jobs = 4
scala> nums.take(3)
res38: Array[Long] = Array(4, 12, 7)
// The number of Spark jobs = 2
executeTake is used when:
- CollectLimitExec physical operator is requested to executeCollect
- AnalyzeColumnCommand logical command is executed
Executing Physical Operator and Collecting Results¶
executeCollect(): Array[InternalRow]
executeCollect executes the physical operator and compresses partitions of UnsafeRows as byte arrays (that gives a RDD[(Long, Array[Byte])] and so no real Spark jobs may have been submitted).
executeCollect runs a Spark job to collect the elements of the RDD and for every pair in the result (of a count and bytes per partition) decodes the byte arrays back to UnsafeRows and stores the decoded arrays together as the final Array[InternalRow].
Note
executeCollect runs a Spark job using Spark Core's RDD.collect operator.
Array[InternalRow]
executeCollect returns Array[InternalRow], i.e. keeps the internal representation of rows unchanged and does not convert rows to JVM types.
executeCollect is used when:
-
Datasetis requested for the Dataset.md#logicalPlan[logical plan] (being a single Command.md[Command] or theirUnion) -
dataset/index.md#explain[explain] and dataset/index.md#count[count] operators are executed
-
Datasetis requested tocollectFromPlan -
SubqueryExecis requested to SubqueryExec.md#doPrepare[prepare for execution] (and initializes SubqueryExec.md#relationFuture[relationFuture] for the first time) -
SparkPlanis requested to < -
ScalarSubquery and InSubquery plan expressions are requested to
updateResult
Output Data Partitioning Requirements¶
outputPartitioning: Partitioning
outputPartitioning specifies the output data partitioning requirements, i.e. a hint for the Spark Physical Optimizer for the number of partitions the output of the physical operator should be split across.
outputPartitioning defaults to a UnknownPartitioning (with 0 partitions).
outputPartitioning is used when:
-
EnsureRequirements physical optimization is executed
-
Datasetis requested to checkpoint
Checking Support for Columnar Processing¶
supportsColumnar: Boolean
supportsColumnar specifies whether the physical operator supports Columnar Execution.
supportsColumnar is false by default (and is expected to be overriden by implementations).
See:
supportsColumnar is used when:
- ApplyColumnarRulesAndInsertTransitions physical optimization is executed
- BatchScanExec physical operator is requested for an inputRDD
- ColumnarToRowExec physical operator is created and executed
- DataSourceV2Strategy execution planning strategy is executed
- FileSourceScanExec physical operator is requested for metadata and metrics
Internal Properties¶
prepared¶
Flag that controls that prepare is executed only once.
subexpressionEliminationEnabled¶
Flag to control whether the subexpression elimination optimization is enabled or not.
Used when the following physical operators are requested to execute (i.e. describe a distributed computation as an RDD of internal rows):