SortMergeJoinExec Physical Operator¶
SortMergeJoinExec is a shuffle-based join physical operator for sort-merge join (with the left join keys being orderable).
SortMergeJoinExec supports Java code generation (variable prefix: smj) for inner and cross joins.
Performance Metrics¶
| Key | Name (in web UI) | Description |
|---|---|---|
| numOutputRows | number of output rows | Number of output rows |
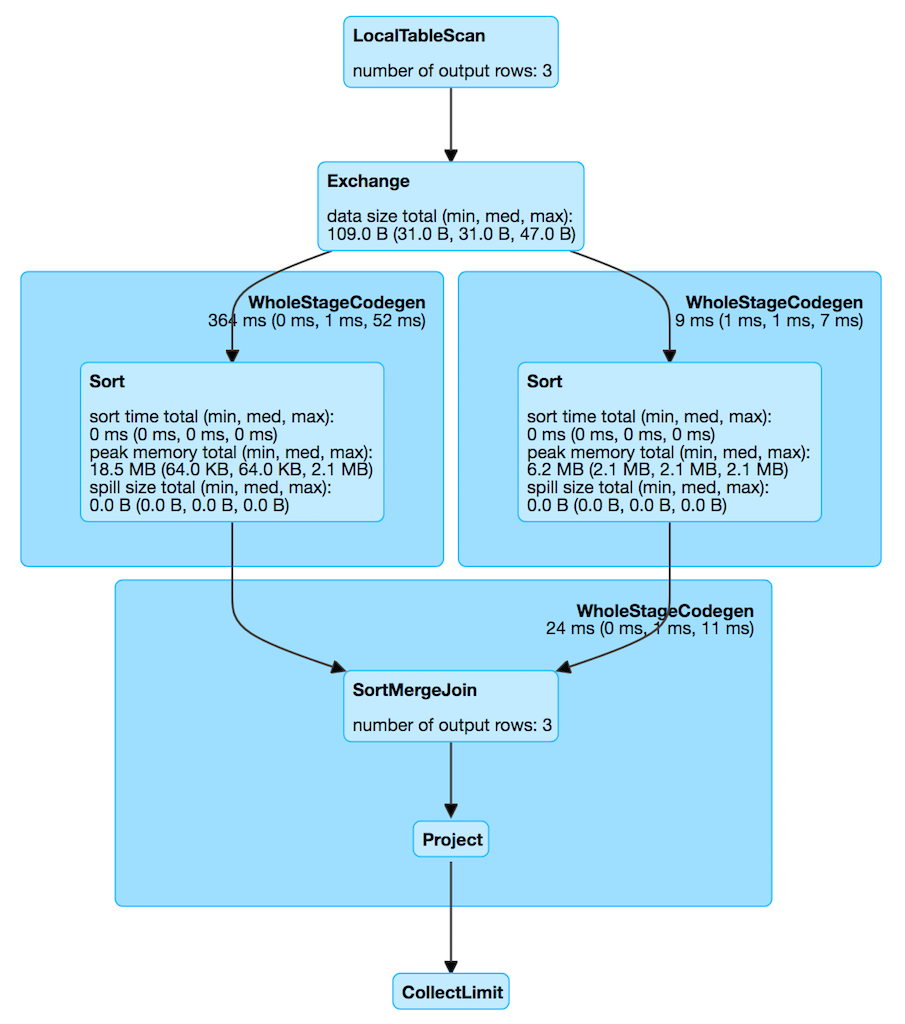
Creating Instance¶
ShuffledHashJoinExec takes the following to be created:
- Left Join Key Expressions
- Right Join Key Expressions
- JoinType
- Optional Join Expression
- Left Physical Operator
- Right Physical Operator
- isSkewJoin flag
ShuffledHashJoinExec is created when:
- JoinSelection execution planning strategy is executed (for equi joins with the left join keys orderable).
Physical Optimizations¶
-
OptimizeSkewedJoin is used to optimize skewed sort-merge joins
-
CoalesceBucketsInJoin physical optimization is used for...FIXME
isSkewJoin Flag¶
ShuffledHashJoinExec can be given isSkewJoin flag when created.
isSkewJoin flag is false by default.
isSkewJoin flag is true when:
- FIXME
isSkewJoin is used for the following:
- FIXME
Node Name¶
nodeName: String
nodeName is part of the TreeNode abstraction.
nodeName adds (skew=true) suffix to the default node name for isSkewJoin flag on.
Required Child Output Distribution¶
requiredChildDistribution: Seq[Distribution]
requiredChildDistribution is part of the SparkPlan abstraction.
HashClusteredDistributions of left and right join keys.
| Left Child | Right Child |
|---|---|
| HashClusteredDistribution (per left join key expressions) | HashClusteredDistribution (per right join key expressions) |
Demo¶
// Disable auto broadcasting so Broadcast Hash Join won't take precedence
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val tokens = Seq(
(0, "playing"),
(1, "with"),
(2, "SortMergeJoinExec")
).toDF("id", "token")
// all data types are orderable
scala> tokens.printSchema
root
|-- id: integer (nullable = false)
|-- token: string (nullable = true)
// Spark Planner prefers SortMergeJoin over Shuffled Hash Join
scala> println(spark.conf.get("spark.sql.join.preferSortMergeJoin"))
true
val q = tokens.join(tokens, Seq("id"), "inner")
scala> q.explain
== Physical Plan ==
*(3) Project [id#5, token#6, token#10]
+- *(3) SortMergeJoin [id#5], [id#9], Inner
:- *(1) Sort [id#5 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id#5, 200)
: +- LocalTableScan [id#5, token#6]
+- *(2) Sort [id#9 ASC NULLS FIRST], false, 0
+- ReusedExchange [id#9, token#10], Exchange hashpartitioning(id#5, 200)
scala> q.queryExecution.debug.codegen
Found 3 WholeStageCodegen subtrees.
== Subtree 1 / 3 ==
*Project [id#5, token#6, token#11]
+- *SortMergeJoin [id#5], [id#10], Inner
:- *Sort [id#5 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id#5, 200)
: +- LocalTableScan [id#5, token#6]
+- *Sort [id#10 ASC NULLS FIRST], false, 0
+- ReusedExchange [id#10, token#11], Exchange hashpartitioning(id#5, 200)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIterator(references);
/* 003 */ }
/* 004 */
/* 005 */ final class GeneratedIterator extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 006 */ private Object[] references;
/* 007 */ private scala.collection.Iterator[] inputs;
/* 008 */ private scala.collection.Iterator smj_leftInput;
/* 009 */ private scala.collection.Iterator smj_rightInput;
/* 010 */ private InternalRow smj_leftRow;
/* 011 */ private InternalRow smj_rightRow;
/* 012 */ private int smj_value2;
/* 013 */ private org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArray smj_matches;
/* 014 */ private int smj_value3;
/* 015 */ private int smj_value4;
/* 016 */ private UTF8String smj_value5;
/* 017 */ private boolean smj_isNull2;
/* 018 */ private org.apache.spark.sql.execution.metric.SQLMetric smj_numOutputRows;
/* 019 */ private UnsafeRow smj_result;
/* 020 */ private org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder smj_holder;
/* 021 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter smj_rowWriter;
...