SortAggregateExec Unary Physical Operator¶
SortAggregateExec is an AggregateCodegenSupport physical operator for Sort-Based Aggregation that uses SortBasedAggregationIterator (to iterate over UnsafeRows in partitions) when executed.
SortAggregateExec is an OrderPreservingUnaryExecNode.
Creating Instance¶
SortAggregateExec takes the following to be created:
- Required Child Distribution
-
isStreamingflag - Number of Shuffle Partitions
- Grouping Keys (NamedExpressions)
- Aggregates (AggregateExpressions)
- Aggregate Attributes
- Initial Input Buffer Offset
- Result (NamedExpressions)
- Child Physical Operator
SortAggregateExec is created when:
AggUtilsutility is used to create a physical operator for aggregationBaseAggregateExecis requested to toSortAggregate
Performance Metrics¶
number of output rows¶
Whole-Stage Code Generation¶
As an AggregateCodegenSupport physical operator, SortAggregateExec supports Whole-Stage Code Generation only when supportCodegen flag is enabled.
Executing Physical Operator¶
doExecute requests the child physical operator to execute (that triggers physical query planning and generates an RDD[InternalRow]).
doExecute transforms the RDD[InternalRow] with the transformation f function for every partition (using RDD.mapPartitionsWithIndex transformation).
Note
This is exactly as in HashAggregateExec.
Transformation Function¶
doExecute uses RDD.mapPartitionsWithIndex to process partition InternalRows (with a partition ID).
// (partition ID, partition rows)
f: (Int, Iterator[T]) => Iterator[U]
For every partition, mapPartitionsWithIndex...FIXME
Note
This is exactly as in HashAggregateExec except that SortAggregateExec uses SortBasedAggregationIterator.
supportCodegen¶
AggregateCodegenSupport
supportCodegen: Boolean
supportCodegen is part of the AggregateCodegenSupport abstraction.
supportCodegen is enabled (true) when all the following hold:
- The parent supportCodegen is enabled
- spark.sql.codegen.aggregate.sortAggregate.enabled is enabled
- No grouping keys
Required Child Ordering¶
SparkPlan
requiredChildOrdering: Seq[Seq[SortOrder]]
requiredChildOrdering is part of the SparkPlan abstraction.
requiredChildOrdering is SortOrders in Ascending direction for every grouping key.
Ordering Expressions¶
AliasAwareQueryOutputOrdering
orderingExpressions: Seq[SortOrder]
orderingExpressions is part of the AliasAwareQueryOutputOrdering abstraction.
orderingExpressions is SortOrders in Ascending direction for every grouping key.
Demo¶
Let's disable preference for ObjectHashAggregateExec physical operator (using the spark.sql.execution.useObjectHashAggregateExec configuration property).
spark.conf.set("spark.sql.execution.useObjectHashAggregateExec", false)
assert(spark.sessionState.conf.useObjectHashAggregation == false)
val names = Seq(
(0, "zero"),
(1, "one"),
(2, "two")).toDF("num", "name")
Let's use immutable data types for aggregateBufferAttributes (so HashAggregateExec physical operator will not be selected).
val q = names
.withColumn("initial", substring('name, 0, 1))
.groupBy('initial)
.agg(collect_set('initial))
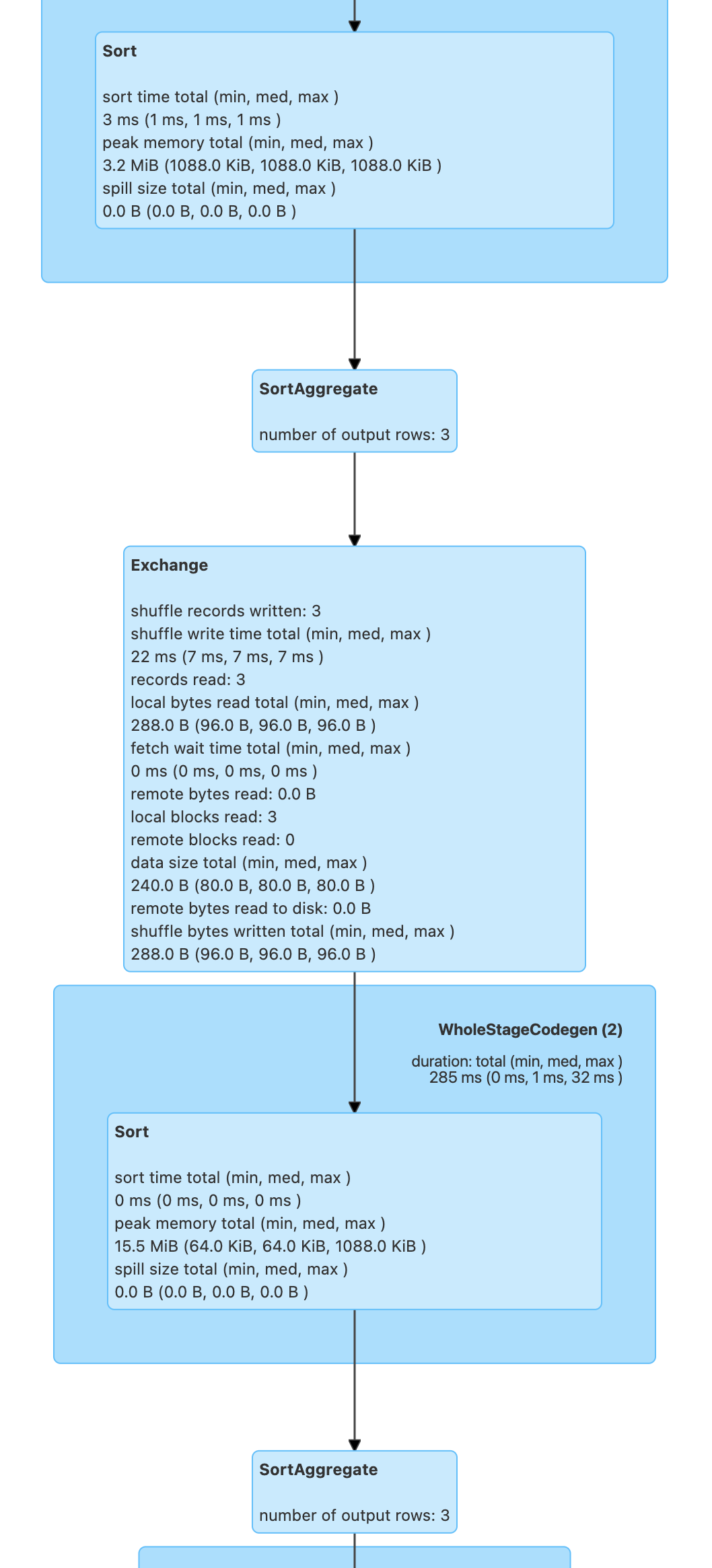
q.explain
== Physical Plan ==
SortAggregate(key=[initial#160], functions=[collect_set(initial#160, 0, 0)])
+- *(2) Sort [initial#160 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(initial#160, 200), ENSURE_REQUIREMENTS, [id=#122]
+- SortAggregate(key=[initial#160], functions=[partial_collect_set(initial#160, 0, 0)])
+- *(1) Sort [initial#160 ASC NULLS FIRST], false, 0
+- *(1) LocalTableScan [initial#160]
import q.queryExecution.optimizedPlan
import org.apache.spark.sql.catalyst.plans.logical.Aggregate
val aggLog = optimizedPlan.asInstanceOf[Aggregate]
import org.apache.spark.sql.catalyst.planning.PhysicalAggregation
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression
val (_, aggregateExpressions: Seq[AggregateExpression], _, _) = PhysicalAggregation.unapply(aggLog).get
val aggregateBufferAttributes =
aggregateExpressions.flatMap(_.aggregateFunction.aggBufferAttributes)
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
assert(HashAggregateExec.supportsAggregate(aggregateBufferAttributes) == false)