ShuffleExchangeExec Physical Operator¶
ShuffleExchangeExec is an Exchange (indirectly as a ShuffleExchangeLike) unary physical operator that is used to perform a shuffle.
Creating Instance¶
ShuffleExchangeExec takes the following to be created:
- Output Partitioning
- Child physical operator
- ShuffleOrigin (default: ENSURE_REQUIREMENTS)
ShuffleExchangeExec is created when:
- BasicOperators execution planning strategy is executed and plans the following:
- Repartition with the shuffle flag enabled
- RepartitionByExpression
- EnsureRequirements physical optimization is executed
Node Name¶
nodeName: String
nodeName is part of the TreeNode abstraction.
nodeName is Exchange.
Performance Metrics¶
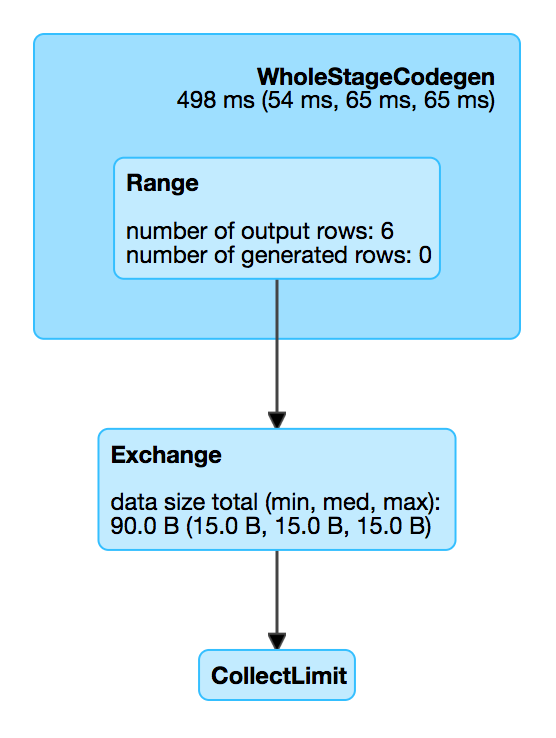
data size¶
number of partitions¶
Number of partitions (of the Partitioner of this ShuffleDependency)
Posted as the only entry in accumUpdates of a SparkListenerDriverAccumUpdates
Read Metrics¶
Used to create a ShuffledRowRDD when:
fetch wait time¶
local blocks read¶
local bytes read¶
records read¶
remote blocks read¶
remote bytes read¶
remote bytes read to disk¶
Write Metrics¶
The write metrics are used to (passed directly to) create a ShuffleDependency (that in turn is used to create a ShuffleWriteProcessor)
shuffle bytes written¶
shuffle records written¶
shuffle write time¶
Executing Physical Operator¶
doExecute(): RDD[InternalRow]
doExecute is part of the SparkPlan abstraction.
doExecute gives a ShuffledRowRDD (with the ShuffleDependency and read performance metrics).
doExecute uses cachedShuffleRDD to avoid multiple execution.
UnsafeRowSerializer¶
serializer: Serializer
serializer is an UnsafeRowSerializer with the following properties:
- Number of fields is the number of the output attributes of the child physical operator
- dataSize performance metric
serializer is used when ShuffleExchangeExec operator is requested for a ShuffleDependency.
ShuffledRowRDD¶
cachedShuffleRDD: ShuffledRowRDD
cachedShuffleRDD is an internal registry for the ShuffledRowRDD that ShuffleExchangeExec operator creates when executed.
The purpose of cachedShuffleRDD is to avoid multiple executions of ShuffleExchangeExec operator when it is reused in a query plan:
cachedShuffleRDDis uninitialized (null) whenShuffleExchangeExecoperator is createdcachedShuffleRDDis assigned aShuffledRowRDDwhenShuffleExchangeExecoperator is executed for the first time
ShuffleDependency¶
shuffleDependency: ShuffleDependency[Int, InternalRow, InternalRow]
shuffleDependency is a ShuffleDependency (Spark Core).
Lazy Value
shuffleDependency is a Scala lazy value to guarantee that the code to initialize it is executed once only (when accessed for the first time) and the computed value never changes afterwards.
Learn more in the Scala Language Specification.
ShuffleExchangeExec operator creates a ShuffleDependency for the following:
- Input RDD
- Output attributes of the child physical operator
- Output partitioning
- UnsafeRowSerializer
- writeMetrics
shuffleDependency is used when:
CustomShuffleReaderExecphysical operator is executed- OptimizeShuffleWithLocalRead is requested to
getPartitionSpecs - OptimizeSkewedJoin physical optimization is executed
ShuffleExchangeExecphysical operator is executed and requested for MapOutputStatistics
mapOutputStatisticsFuture¶
mapOutputStatisticsFuture: Future[MapOutputStatistics]
mapOutputStatisticsFuture requests the inputRDD for the number of partitions:
-
If there are zero partitions,
mapOutputStatisticsFuturesimply creates an already completedFuture(Scala) withnullvalue -
Otherwise,
mapOutputStatisticsFuturerequests the operator'sSparkContexttosubmitMapStage(Spark Core) with the ShuffleDependency.
Lazy Value
mapOutputStatisticsFuture is a Scala lazy value to guarantee that the code to initialize it is executed once only (when accessed for the first time) and the computed value never changes afterwards.
Learn more in the Scala Language Specification.
mapOutputStatisticsFuture is part of the ShuffleExchangeLike abstraction.
Creating ShuffleWriteProcessor¶
createShuffleWriteProcessor(
metrics: Map[String, SQLMetric]): ShuffleWriteProcessor
createShuffleWriteProcessor creates a ShuffleWriteProcessor (Spark Core) to plug in SQLShuffleWriteMetricsReporter (as a ShuffleWriteMetricsReporter (Spark Core)) with the write metrics.
createShuffleWriteProcessor is used when:
ShuffleExchangeExecoperator is executed (and requested for a ShuffleDependency)
Runtime Statistics¶
runtimeStatistics: Statistics
runtimeStatistics is part of the ShuffleExchangeLike abstraction.
runtimeStatistics creates a Statistics with the value of the following metrics.
| Statistics | Metric |
|---|---|
| Output size | data size |
| Number of rows | shuffle records written |
Creating ShuffleDependency¶
prepareShuffleDependency(
rdd: RDD[InternalRow],
outputAttributes: Seq[Attribute],
newPartitioning: Partitioning,
serializer: Serializer,
writeMetrics: Map[String, SQLMetric]): ShuffleDependency[Int, InternalRow, InternalRow]
prepareShuffleDependency is used when:
- CollectLimitExec, ShuffleExchangeExec and
TakeOrderedAndProjectExecphysical operators are executed
prepareShuffleDependency creates a ShuffleDependency (Apache Spark) with the following:
- rddWithPartitionIds
PartitionIdPassthroughserializer (with the number of partitions as the Partitioner)- The input
Serializer(e.g., the UnsafeRowSerializer forShuffleExchangeExecphysical operators) - Write Metrics
Write Metrics for ShuffleExchangeExec
For ShuffleExchangeExecs, the write metrics are the following:
Partitioner¶
prepareShuffleDependency determines a Partitioner based on the given newPartitioning Partitioning:
- For RoundRobinPartitioning,
prepareShuffleDependencycreates aHashPartitionerfor the same number of partitions - For HashPartitioning,
prepareShuffleDependencycreates aPartitionerfor the same number of partitions andgetPartitionthat is an "identity" - For
RangePartitioning,prepareShuffleDependencycreates aRangePartitionerfor the same number of partitions andsamplePointsPerPartitionHintbased on spark.sql.execution.rangeExchange.sampleSizePerPartition configuration property - For SinglePartition,
prepareShuffleDependencycreates aPartitionerwith1for the number of partitions andgetPartitionthat always gives0
getPartitionKeyExtractor¶
getPartitionKeyExtractor(): InternalRow => Any
getPartitionKeyExtractor uses the given newPartitioning Partitioning:
- For RoundRobinPartitioning,...FIXME
- For HashPartitioning,...FIXME
- For
RangePartitioning,...FIXME - For SinglePartition,...FIXME
isRoundRobin Flag¶
prepareShuffleDependency determines whether "this" is isRoundRobin or not based on the given newPartitioning partitioning. It is isRoundRobin when the partitioning is a RoundRobinPartitioning with more than one partition.
rddWithPartitionIds RDD¶
prepareShuffleDependency creates a rddWithPartitionIds:
- Firstly,
prepareShuffleDependencydetermines anewRddbased onisRoundRobinflag and spark.sql.execution.sortBeforeRepartition configuration property. When both are enabled (true),prepareShuffleDependencysorts partitions (using aUnsafeExternalRowSorter) Otherwise,prepareShuffleDependencyreturns the givenRDD[InternalRow](unchanged). - Secondly,
prepareShuffleDependencydetermines whether this isisOrderSensitiveor not. This isisOrderSensitivewhenisRoundRobinflag is enabled (true) while spark.sql.execution.sortBeforeRepartition configuration property is not (false).
prepareShuffleDependency...FIXME
Demo¶
ShuffleExchangeExec and Repartition Logical Operator¶
val q = spark.range(6).repartition(2)
scala> q.explain(extended = true)
== Parsed Logical Plan ==
Repartition 2, true
+- Range (0, 6, step=1, splits=Some(16))
== Analyzed Logical Plan ==
id: bigint
Repartition 2, true
+- Range (0, 6, step=1, splits=Some(16))
== Optimized Logical Plan ==
Repartition 2, true
+- Range (0, 6, step=1, splits=Some(16))
== Physical Plan ==
Exchange RoundRobinPartitioning(2), false, [id=#8]
+- *(1) Range (0, 6, step=1, splits=16)
ShuffleExchangeExec and RepartitionByExpression Logical Operator¶
val q = spark.range(6).repartition(2, 'id % 2)
scala> q.explain(extended = true)
== Parsed Logical Plan ==
'RepartitionByExpression [('id % 2)], 2
+- Range (0, 6, step=1, splits=Some(16))
== Analyzed Logical Plan ==
id: bigint
RepartitionByExpression [(id#4L % cast(2 as bigint))], 2
+- Range (0, 6, step=1, splits=Some(16))
== Optimized Logical Plan ==
RepartitionByExpression [(id#4L % 2)], 2
+- Range (0, 6, step=1, splits=Some(16))
== Physical Plan ==
Exchange hashpartitioning((id#4L % 2), 2), false, [id=#17]
+- *(1) Range (0, 6, step=1, splits=16)