InputAdapter Unary Physical Operator¶
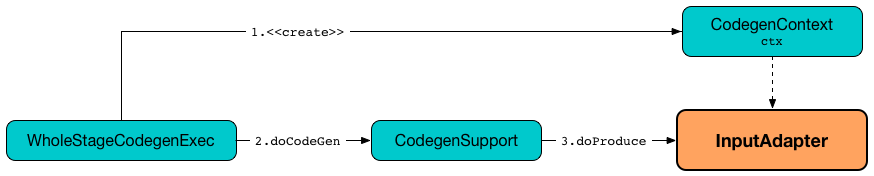
InputAdapter is a unary physical operator that is an adapter for the child physical operator that does not meet the requirements of whole-stage Java code generation (possibly due to supportCodegen flag turned off) but is between operators that participate in whole-stage Java code generation optimization.
InputAdapter takes a single child physical plan when created.
InputAdapter is created exclusively when CollapseCodegenStages physical optimization is executed (and requested to insert InputAdapters into a physical query plan with whole-stage Java code generation enabled).
InputAdapter makes sure that the prefix in the text representation of a physical plan tree is an empty string (and so it removes the star from the tree representation that WholeStageCodegenExec adds), e.g. for explain or TreeNode.numberedTreeString operators.
TIP: The number of InputAdapters is exactly the number of subtrees in a physical query plan that do not have stars.
scala> println(plan.numberedTreeString)
*(1) Project [id#117L]
+- *(1) BroadcastHashJoin [id#117L], [cast(id#115 as bigint)], Inner, BuildRight
:- *(1) Range (0, 1, step=1, splits=8)
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- Generate explode(ids#112), false, [id#115]
+- LocalTableScan [ids#112]
InputAdapter requires that...FIXME, i.e. needCopyResult flag is turned off.
InputAdapter executes the child physical operator to get the one and only one RDD[InternalRow] as its own input RDDs for whole-stage produce path code generation.
// explode expression (that uses Generate operator) does not support codegen
val ids = Seq(Seq(0,1,2,3)).toDF("ids").select(explode($"ids") as "id")
val q = spark.range(1).join(ids, "id")
// Use executedPlan
// This is after the whole-stage Java code generation optimization is applied to a physical plan
val plan = q.queryExecution.executedPlan
scala> println(plan.numberedTreeString)
00 *(1) Project [id#117L]
01 +- *(1) BroadcastHashJoin [id#117L], [cast(id#115 as bigint)], Inner, BuildRight
02 :- *(1) Range (0, 1, step=1, splits=8)
03 +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
04 +- Generate explode(ids#112), false, [id#115]
05 +- LocalTableScan [ids#112]
// Find all InputAdapters in the physical query plan
import org.apache.spark.sql.execution.InputAdapter
scala> plan.collect { case a: InputAdapter => a }.zipWithIndex.map { case (op, idx) => s"$idx) $op" }.foreach(println)
0) BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- Generate explode(ids#112), false, [id#115]
+- LocalTableScan [ids#112]
Generating Java Source Code for Produce Path in Whole-Stage Code Generation -- doProduce Method
doProduce(ctx: CodegenContext): String
doProduce generates a Java source code that consumes InternalRow of a single input RDD one at a time (in a while loop).
NOTE: doProduce supports one input RDD only (that the single <
Internally, doProduce generates two input and row "fresh" terms and registers input as a mutable state (in the generated class).
doProduce gives a plain Java source code that uses input and row terms as well as the code from consume code generator to iterate over the InternalRows from the first <
doProduce is part of the CodegenSupport abstraction.
val q = spark.range(1)
.select(explode(lit((0 to 1).toArray)) as "n") // <-- explode expression does not support codegen
.join(spark.range(2))
.where($"n" === $"id")
scala> q.explain
== Physical Plan ==
*BroadcastHashJoin [cast(n#4 as bigint)], [id#7L], Inner, BuildRight
:- *Filter isnotnull(n#4)
: +- Generate explode([0,1]), false, false, [n#4]
: +- *Project
: +- *Range (0, 1, step=1, splits=8)
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]))
+- *Range (0, 2, step=1, splits=8)
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.InputAdapter
// there are two InputAdapters (for Generate and BroadcastExchange operators) so get is safe
val adapter = plan.collectFirst { case a: InputAdapter => a }.get
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
import org.apache.spark.sql.execution.CodegenSupport
val code = adapter.produce(ctx, plan.asInstanceOf[CodegenSupport])
scala> println(code)
/*inputadapter_c5*/
while (inputadapter_input2.hasNext() && !stopEarly()) {
InternalRow inputadapter_row2 = (InternalRow) inputadapter_input2.next();
/*wholestagecodegen_c1*/
append(inputadapter_row2);
if (shouldStop()) return;
}
import org.apache.spark.sql.catalyst.plans.logical.Range
val r = Range(start = 0, end = 1, step = 1, numSlices = 1)
import org.apache.spark.sql.execution.RangeExec
val re = RangeExec(r)
import org.apache.spark.sql.execution.InputAdapter
val ia = InputAdapter(re)
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
// You cannot call doProduce directly
// CodegenSupport.parent is not set up
// and so consume will throw NPE (that's used in doProduce)
// That's why you're supposed to call produce final method that does this
import org.apache.spark.sql.execution.CodegenSupport
ia.produce(ctx, parent = ia.asInstanceOf[CodegenSupport])
// produce however will lead to java.lang.UnsupportedOperationException
// which is due to doConsume throwing it by default
// and InputAdapter does not override it!
// That's why InputAdapter has to be under a WholeStageCodegenExec-enabled physical operator
// which happens in CollapseCodegenStages.insertWholeStageCodegen
// when a physical operator is CodegenSupport and meets codegen requirements
// CollapseCodegenStages.supportCodegen
// Most importantly it is CodegenSupport with supportCodegen flag on
// The following physical operators turn supportCodegen flag off (and require InputAdapter wrapper)
// 1. GenerateExec
// 1. HashAggregateExec with a ImperativeAggregate aggregate function expression
// 1. SortMergeJoinExec with InnerLike joins, i.e. CROSS and INNER
// 1. InMemoryTableScanExec with output schema with primitive types only,
// i.e. BooleanType, ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType
FIXME Make the code working