InMemoryTableScanExec Leaf Physical Operator¶
InMemoryTableScanExec is a leaf physical operator that represents an InMemoryRelation logical operator at execution time.
Performance Metrics¶
| Key | Name (in web UI) | Description |
|---|---|---|
| numOutputRows | number of output rows | Number of output rows |
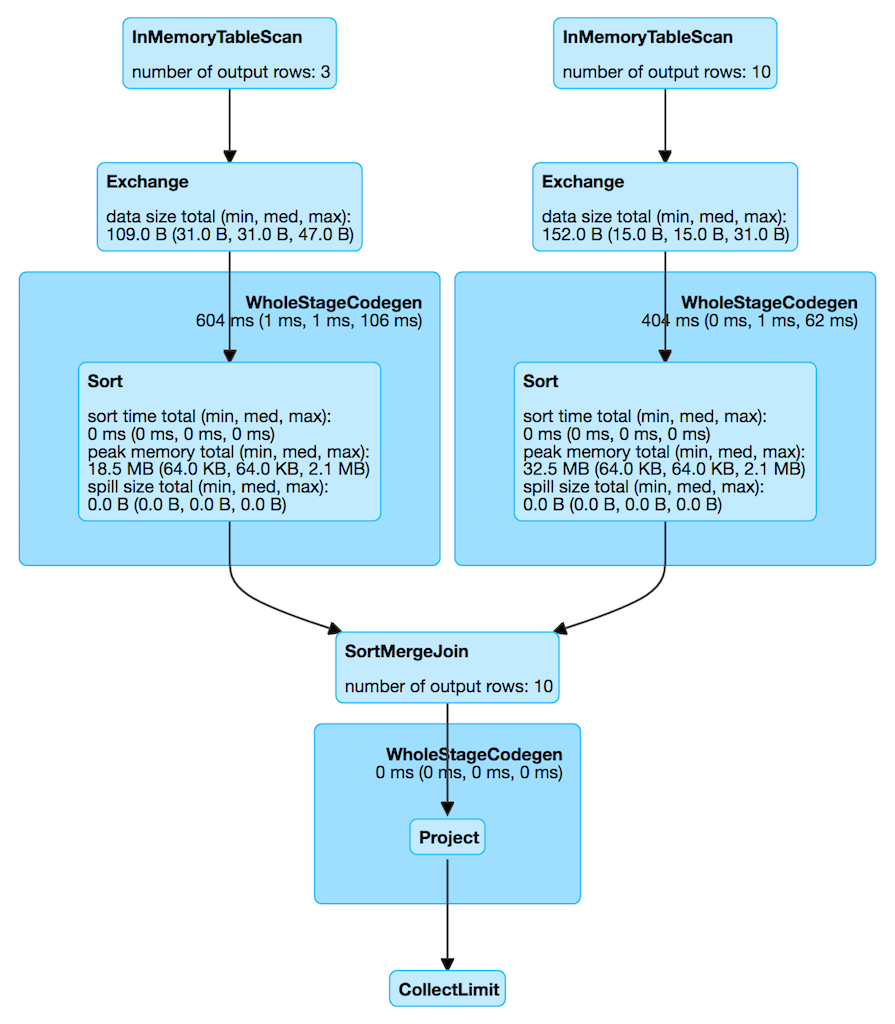
Demo¶
FIXME Do the below code blocks work still?
// Example to show produceBatches to generate a Java source code
// Create a DataFrame
val ids = spark.range(10)
// Cache it (and trigger the caching since it is lazy)
ids.cache.foreach(_ => ())
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
// we need executedPlan with WholeStageCodegenExec physical operator
// this will make sure the code generation starts at the right place
val plan = ids.queryExecution.executedPlan
val scan = plan.collectFirst { case e: InMemoryTableScanExec => e }.get
assert(scan.supportsBatch, "supportsBatch flag should be on to trigger produceBatches")
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
// produceBatches is private so we have to trigger it from "outside"
// It could be doProduce with supportsBatch flag on but it is protected
// (doProduce will also take care of the extra input `input` parameter)
// let's do this the only one right way
import org.apache.spark.sql.execution.CodegenSupport
val parent = plan.p(0).asInstanceOf[CodegenSupport]
val produceCode = scan.produce(ctx, parent)
scala> println(produceCode)
if (inmemorytablescan_mutableStateArray1[1] == null) {
inmemorytablescan_nextBatch1();
}
while (inmemorytablescan_mutableStateArray1[1] != null) {
int inmemorytablescan_numRows1 = inmemorytablescan_mutableStateArray1[1].numRows();
int inmemorytablescan_localEnd1 = inmemorytablescan_numRows1 - inmemorytablescan_batchIdx1;
for (int inmemorytablescan_localIdx1 = 0; inmemorytablescan_localIdx1 < inmemorytablescan_localEnd1; inmemorytablescan_localIdx1++) {
int inmemorytablescan_rowIdx1 = inmemorytablescan_batchIdx1 + inmemorytablescan_localIdx1;
long inmemorytablescan_value2 = inmemorytablescan_mutableStateArray2[1].getLong(inmemorytablescan_rowIdx1);
inmemorytablescan_mutableStateArray5[1].write(0, inmemorytablescan_value2);
append(inmemorytablescan_mutableStateArray3[1]);
if (shouldStop()) { inmemorytablescan_batchIdx1 = inmemorytablescan_rowIdx1 + 1; return; }
}
inmemorytablescan_batchIdx1 = inmemorytablescan_numRows1;
inmemorytablescan_mutableStateArray1[1] = null;
inmemorytablescan_nextBatch1();
}
((org.apache.spark.sql.execution.metric.SQLMetric) references[3] /* scanTime */).add(inmemorytablescan_scanTime1 / (1000 * 1000));
inmemorytablescan_scanTime1 = 0;
// the code does not look good and begs for some polishing
// (You can only imagine how the Polish me looks when I say "polishing" :))
import org.apache.spark.sql.execution.WholeStageCodegenExec
val wsce = plan.asInstanceOf[WholeStageCodegenExec]
// Trigger code generation of the entire query plan tree
val (ctx, code) = wsce.doCodeGen
// CodeFormatter can pretty-print the code
import org.apache.spark.sql.catalyst.expressions.codegen.CodeFormatter
println(CodeFormatter.format(code))
// Let's create a query with a InMemoryTableScanExec physical operator that supports batch decoding
val q = spark.range(4).cache
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
val inmemoryScan = plan.collectFirst { case exec: InMemoryTableScanExec => exec }.get
assert(inmemoryScan.supportsBatch)
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
import org.apache.spark.sql.execution.CodegenSupport
val parent = plan.asInstanceOf[CodegenSupport]
val code = inmemoryScan.produce(ctx, parent)
scala> println(code)
if (inmemorytablescan_mutableStateArray1[1] == null) {
inmemorytablescan_nextBatch1();
}
while (inmemorytablescan_mutableStateArray1[1] != null) {
int inmemorytablescan_numRows1 = inmemorytablescan_mutableStateArray1[1].numRows();
int inmemorytablescan_localEnd1 = inmemorytablescan_numRows1 - inmemorytablescan_batchIdx1;
for (int inmemorytablescan_localIdx1 = 0; inmemorytablescan_localIdx1 < inmemorytablescan_localEnd1; inmemorytablescan_localIdx1++) {
int inmemorytablescan_rowIdx1 = inmemorytablescan_batchIdx1 + inmemorytablescan_localIdx1;
long inmemorytablescan_value2 = inmemorytablescan_mutableStateArray2[1].getLong(inmemorytablescan_rowIdx1);
inmemorytablescan_mutableStateArray5[1].write(0, inmemorytablescan_value2);
append(inmemorytablescan_mutableStateArray3[1]);
if (shouldStop()) { inmemorytablescan_batchIdx1 = inmemorytablescan_rowIdx1 + 1; return; }
}
inmemorytablescan_batchIdx1 = inmemorytablescan_numRows1;
inmemorytablescan_mutableStateArray1[1] = null;
inmemorytablescan_nextBatch1();
}
((org.apache.spark.sql.execution.metric.SQLMetric) references[3] /* scanTime */).add(inmemorytablescan_scanTime1 / (1000 * 1000));
inmemorytablescan_scanTime1 = 0;
val q = Seq(Seq(1,2,3)).toDF("ids").cache
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
val inmemoryScan = plan.collectFirst { case exec: InMemoryTableScanExec => exec }.get
assert(inmemoryScan.supportsBatch == false)
// NOTE: The following codegen won't work since supportsBatch is off and so is codegen
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
import org.apache.spark.sql.execution.CodegenSupport
val parent = plan.asInstanceOf[CodegenSupport]
scala> val code = inmemoryScan.produce(ctx, parent)
java.lang.UnsupportedOperationException
at org.apache.spark.sql.execution.CodegenSupport$class.doConsume(WholeStageCodegenExec.scala:315)
at org.apache.spark.sql.execution.columnar.InMemoryTableScanExec.doConsume(InMemoryTableScanExec.scala:33)
at org.apache.spark.sql.execution.CodegenSupport$class.constructDoConsumeFunction(WholeStageCodegenExec.scala:208)
at org.apache.spark.sql.execution.CodegenSupport$class.consume(WholeStageCodegenExec.scala:179)
at org.apache.spark.sql.execution.columnar.InMemoryTableScanExec.consume(InMemoryTableScanExec.scala:33)
at org.apache.spark.sql.execution.ColumnarBatchScan$class.produceRows(ColumnarBatchScan.scala:166)
at org.apache.spark.sql.execution.ColumnarBatchScan$class.doProduce(ColumnarBatchScan.scala:80)
at org.apache.spark.sql.execution.columnar.InMemoryTableScanExec.doProduce(InMemoryTableScanExec.scala:33)
at org.apache.spark.sql.execution.CodegenSupport$$anonfun$produce$1.apply(WholeStageCodegenExec.scala:88)
at org.apache.spark.sql.execution.CodegenSupport$$anonfun$produce$1.apply(WholeStageCodegenExec.scala:83)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.CodegenSupport$class.produce(WholeStageCodegenExec.scala:83)
at org.apache.spark.sql.execution.columnar.InMemoryTableScanExec.produce(InMemoryTableScanExec.scala:33)
... 49 elided
val q = spark.read.text("README.md")
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.FileSourceScanExec
val scan = plan.collectFirst { case exec: FileSourceScanExec => exec }.get
// 2. supportsBatch is off
assert(scan.supportsBatch == false)
// 3. InMemoryTableScanExec.produce
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
import org.apache.spark.sql.execution.CodegenSupport
import org.apache.spark.sql.execution.WholeStageCodegenExec
val wsce = plan.collectFirst { case exec: WholeStageCodegenExec => exec }.get
val code = scan.produce(ctx, parent = wsce)
scala> println(code)
// blank lines removed
while (scan_mutableStateArray[2].hasNext()) {
InternalRow scan_row2 = (InternalRow) scan_mutableStateArray[2].next();
((org.apache.spark.sql.execution.metric.SQLMetric) references[2] /* numOutputRows */).add(1);
append(scan_row2);
if (shouldStop()) return;
}