HashAggregateExec Physical Operator¶
HashAggregateExec is an AggregateCodegenSupport physical operator for Hash-Based Aggregation (with UnsafeRow keys and values) that uses TungstenAggregationIterator (to iterate over UnsafeRows in partitions) when executed.
HashAggregateExec is the preferred aggregate physical operator for Aggregate logical operator.
Falling Back To Sort-Based Aggregation
HashAggregateExec uses TungstenAggregationIterator that can (theoretically) switch to a sort-based aggregation when the hash-based processing mode is unable to acquire enough memory.
See testFallbackStartsAt internal property and spark.sql.TungstenAggregate.testFallbackStartsAt configuration property.
Search logs for the following INFO message to know whether the switch has happened.
falling back to sort based aggregation.
Creating Instance¶
HashAggregateExec takes the following to be created:
- Required child distribution expressions
-
isStreamingflag - Number of Shuffle Partitions (optional)
- Grouping Keys
- Aggregates (AggregateExpressions)
- Aggregate Attributes
- Initial Input Buffer Offset
- Result (NamedExpressions)
- Child Physical Operator
HashAggregateExec is created (indirectly through AggUtils.createAggregate) when:
- Aggregation execution planning strategy is executed (to select the aggregate physical operator for an Aggregate logical operator)
StatefulAggregationStrategy(Spark Structured Streaming) execution planning strategy creates plan for streamingEventTimeWatermarkor Aggregate logical operators
Grouping Keys¶
BaseAggregateExec
groupingExpressions: Seq[NamedExpression]
groupingExpressions is part of the BaseAggregateExec abstraction.
HashAggregateExec is given grouping keys (NamedExpressions) when created. There can be no grouping keys.
The grouping keys are the groupingExpressions of Aggregate, if any.
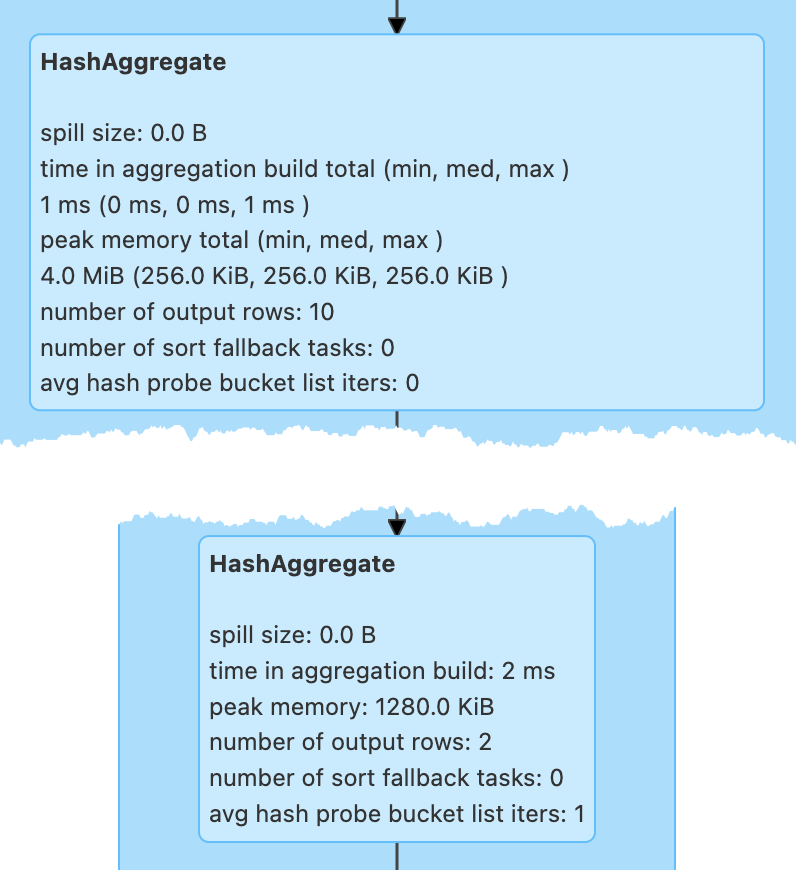
Performance Metrics¶
avg hash probes per key¶
Average hash map probe per lookup (i.e. numProbes / numKeyLookups)
numProbes and numKeyLookups are used in BytesToBytesMap (Spark Core) append-only hash map for the number of iteration to look up a single key and the number of all the lookups in total, respectively.
number of output rows¶
Average hash map probe per lookup (i.e. numProbes / numKeyLookups)
Number of groups (per partition) that (depending on the number of partitions and the side of ShuffleExchangeExec.md[ShuffleExchangeExec] operator) is the number of groups
-
0for no input with a grouping expression, e.g.spark.range(0).groupBy($"id").count.show -
1for no grouping expression and no input, e.g.spark.range(0).groupBy().count.show
Tip
Use different number of elements and partitions in range operator to observe the difference in numOutputRows metric, e.g.
spark.
range(0, 10, 1, numPartitions = 1).
groupBy($"id" % 5 as "gid").
count.
show
spark.
range(0, 10, 1, numPartitions = 5).
groupBy($"id" % 5 as "gid").
count.
show
number of sort fallback tasks¶
This metric is managed entirely by the TungstenAggregationIterator.
Indicates how many tasks (that used TungstenAggregationIterator to process input rows for aggregates) switched (fell back) to sort-based aggregation
Number of Input Rows in Partition Matters
Not every task will use TungstenAggregationIterator and may even have a chance to fall back to sort-based aggregation.
peak memory¶
This metric is managed entirely by the TungstenAggregationIterator.
spill size¶
Used to create a TungstenAggregationIterator when doExecute
time in aggregation build¶
Query Planning¶
HashAggregateExec is the preferred aggregate physical operator in Aggregation execution planning strategy (over ObjectHashAggregateExec and SortAggregateExec operators).
HashAggregateExec is selected as the aggregate physical operator for Aggregate logical operator when all the AggregateFunctions (of the AggregateExpressions) use aggBufferAttributes with mutable data types:
BooleanTypeByteTypeCalendarIntervalTypeDateTypeDayTimeIntervalTypeDecimalTypeDoubleTypeFloatTypeIntegerTypeLongTypeNullTypeShortTypeTimestampNTZTypeTimestampType- UserDefinedType with a mutable data type
YearMonthIntervalType
Required Child Distribution¶
SparkPlan
requiredChildDistribution: List[Distribution]
requiredChildDistribution is part of the SparkPlan abstraction.
requiredChildDistribution varies per the input required child distribution expressions:
- AllTuples when defined, but empty
- ClusteredDistribution for non-empty expressions
- UnspecifiedDistribution when undefined
Note
requiredChildDistributionExpressions is exactly requiredChildDistributionExpressions from AggUtils.createAggregate and is undefined by default.
(No distinct in aggregation) requiredChildDistributionExpressions is undefined when HashAggregateExec is created for partial aggregations (i.e. mode is Partial for aggregate expressions).
requiredChildDistributionExpressions is defined, but could possibly be empty, when HashAggregateExec is created for final aggregations (i.e. mode is Final for aggregate expressions).
(one distinct in aggregation) requiredChildDistributionExpressions is undefined when HashAggregateExec is created for partial aggregations (i.e. mode is Partial for aggregate expressions) with one distinct in aggregation.
requiredChildDistributionExpressions is defined, but could possibly be empty, when HashAggregateExec is created for partial merge aggregations (i.e. mode is PartialMerge for aggregate expressions).
FIXME for the following two cases in aggregation with one distinct.
Executing Physical Operator¶
doExecute requests the child physical operator to execute (that triggers physical query planning and generates an RDD[InternalRow]).
doExecute transforms the RDD[InternalRow] with the transformation f function for every partition (using RDD.mapPartitionsWithIndex transformation).
Transformation Function¶
doExecute uses RDD.mapPartitionsWithIndex to process partition InternalRows (with a partition ID).
f: (Int, Iterator[T]) => Iterator[U]
For every partition, mapPartitionsWithIndex records the start execution time (beforeAgg).
mapPartitionsWithIndex branches off based on whether there are input rows and grouping keys.
For a grouped aggregate (grouping keys defined) with no input rows (an empty partition), doExecute returns an empty iterator.
Otherwise, doExecute creates a TungstenAggregationIterator.
With no grouping keys defined and no input rows (an empty partition), doExecute increments the numOutputRows metric and returns a single-element Iterator[UnsafeRow] from the TungstenAggregationIterator.
With input rows available (and regardless of grouping keys), doExecute returns the TungstenAggregationIterator.
In the end, doExecute calculates the aggTime metric and returns an Iterator[UnsafeRow] that can be as follows:
- Empty
- A single-element one
- The TungstenAggregationIterator
RDD.mapPartitionsWithIndex¶
RDD.mapPartitionsWithIndex
mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
mapPartitionsWithIndex transformation adds a new MapPartitionsRDD to the RDD lineage.
FIXME Disable AQE
val ids = spark.range(1)
println(ids.queryExecution.toRdd.toDebugString)
(12) SQLExecutionRDD[3] at toRdd at <console>:1 []
| MapPartitionsRDD[2] at toRdd at <console>:1 []
| MapPartitionsRDD[1] at toRdd at <console>:1 []
| ParallelCollectionRDD[0] at toRdd at <console>:1 []
// Use groupBy that gives HashAggregateExec operator
val q = ids.groupBy('id).count
q.explain
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[id#2L], functions=[count(1)])
+- HashAggregate(keys=[id#2L], functions=[partial_count(1)])
+- Range (0, 1, step=1, splits=12)
val rdd = q.queryExecution.toRdd
println(rdd.toDebugString)
(12) SQLExecutionRDD[11] at toRdd at <console>:1 []
| MapPartitionsRDD[10] at toRdd at <console>:1 []
| MapPartitionsRDD[9] at toRdd at <console>:1 []
| ParallelCollectionRDD[8] at toRdd at <console>:1 []
Whole-Stage Code Generation¶
HashAggregateExec supports Whole-Stage Code Generation (as an AggregateCodegenSupport physical operator) only when supportCodegen flag is enabled.
HashAggregateExec is given hashAgg as the variable prefix.
doConsumeWithKeys¶
AggregateCodegenSupport
doConsumeWithKeys(
ctx: CodegenContext,
input: Seq[ExprCode]): String
doConsumeWithKeys is part of the AggregateCodegenSupport abstraction.
doConsumeWithKeys...FIXME
doProduceWithKeys¶
AggregateCodegenSupport
doProduceWithKeys(
ctx: CodegenContext): String
doProduceWithKeys is part of the AggregateCodegenSupport abstraction.
doProduceWithKeys uses the following configuration properties:
- spark.sql.codegen.aggregate.map.twolevel.enabled
- spark.sql.codegen.aggregate.map.vectorized.enable
- spark.sql.codegen.aggregate.fastHashMap.capacityBit
doProduceWithKeys...FIXME
In the end, doProduceWithKeys generates the following Java code (with the []-marked sections filled out):
if (![initAgg]) {
[initAgg] = true;
[createFastHashMap]
[addHookToCloseFastHashMap]
[hashMapTerm] = [thisPlan].createHashMap();
long [beforeAgg] = System.nanoTime();
[doAggFuncName]();
[aggTime].add((System.nanoTime() - [beforeAgg]) / [NANOS_PER_MILLIS]);
}
// output the result
[outputFromFastHashMap]
[outputFromRegularHashMap]
Creating HashMap¶
createHashMap(): UnsafeFixedWidthAggregationMap
Note
createHashMap is used in the Java code from doProduceWithKeys.
createHashMap requests all the DeclarativeAggregate functions for the Catalyst expressions to initialize aggregation buffers.
createHashMap creates an UnsafeProjection for the expressions and executes it (with an "empty" null row).
Note
Executing an UnsafeProjection produces an UnsafeRow that becomes an empty aggregation buffer of an UnsafeFixedWidthAggregationMap to be created.
In the end, createHashMap creates an UnsafeFixedWidthAggregationMap with the following:
| UnsafeFixedWidthAggregationMap | Value |
|---|---|
| emptyAggregationBuffer | The UnsafeRow after executing the UnsafeProjection to initialize aggregation buffers |
| aggregationBufferSchema | bufferSchema |
| groupingKeySchema | groupingKeySchema |
finishAggregate¶
finishAggregate(
hashMap: UnsafeFixedWidthAggregationMap,
sorter: UnsafeKVExternalSorter,
peakMemory: SQLMetric,
spillSize: SQLMetric,
avgHashProbe: SQLMetric,
numTasksFallBacked: SQLMetric): KVIterator[UnsafeRow, UnsafeRow]
finishAggregate...FIXME
DeclarativeAggregate Functions¶
declFunctions: Seq[DeclarativeAggregate]
declFunctions is the DeclarativeAggregate expressions among the AggregateFunctions of this AggregateExpressions.
Demo¶
Aggregation Query¶
val data = spark.range(10)
val q = data
.groupBy('id % 2 as "group")
.agg(sum("id") as "sum")
HashAggregateExec operator should be selected due to:
sumuses mutable types for aggregate expression- just a single
idcolumn reference ofLongTypedata type
scala> println(q.queryExecution.executedPlan.numberedTreeString)
00 AdaptiveSparkPlan isFinalPlan=false
01 +- HashAggregate(keys=[_groupingexpression#8L], functions=[sum(id#0L)], output=[group#2L, sum#5L])
02 +- Exchange hashpartitioning(_groupingexpression#8L, 200), ENSURE_REQUIREMENTS, [plan_id=15]
03 +- HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
04 +- Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
05 +- Range (0, 10, step=1, splits=16)
Generate Final Plan¶
isFinalPlan flag is false. Let's execute it and access the final plan.
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec
val op = q
.queryExecution
.executedPlan
.collect { case op: AdaptiveSparkPlanExec => op }
.head
Execute the adaptive operator to generate the final execution plan.
op.executeTake(1)
isFinalPlan flag should now be true.
scala> println(op.treeString)
AdaptiveSparkPlan isFinalPlan=true
+- == Final Plan ==
*(2) HashAggregate(keys=[_groupingexpression#8L], functions=[sum(id#0L)], output=[group#2L, sum#5L])
+- AQEShuffleRead coalesced
+- ShuffleQueryStage 0
+- Exchange hashpartitioning(_groupingexpression#8L, 200), ENSURE_REQUIREMENTS, [plan_id=25]
+- *(1) HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
+- *(1) Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
+- *(1) Range (0, 10, step=1, splits=16)
+- == Initial Plan ==
HashAggregate(keys=[_groupingexpression#8L], functions=[sum(id#0L)], output=[group#2L, sum#5L])
+- Exchange hashpartitioning(_groupingexpression#8L, 200), ENSURE_REQUIREMENTS, [plan_id=15]
+- HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
+- Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
+- Range (0, 10, step=1, splits=16)
With the isFinalPlan flag true, it is possible to print out the WholeStageCodegen subtrees.
scala> q.queryExecution.debug.codegen
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 (maxMethodCodeSize:284; maxConstantPoolSize:337(0.51% used); numInnerClasses:2) ==
*(1) HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
+- *(1) Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
+- *(1) Range (0, 10, step=1, splits=16)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean hashAgg_initAgg_0;
/* 010 */ private org.apache.spark.unsafe.KVIterator hashAgg_mapIter_0;
/* 011 */ private org.apache.spark.sql.execution.UnsafeFixedWidthAggregationMap hashAgg_hashMap_0;
/* 012 */ private org.apache.spark.sql.execution.UnsafeKVExternalSorter hashAgg_sorter_0;
/* 013 */ private scala.collection.Iterator inputadapter_input_0;
/* 014 */ private boolean hashAgg_hashAgg_isNull_2_0;
...
Let's access the generated source code via WholeStageCodegenExec physical operator.
val aqe = op
import org.apache.spark.sql.execution.WholeStageCodegenExec
val wsce = aqe.executedPlan
.collect { case op: WholeStageCodegenExec => op }
.head
val (_, source) = wsce.doCodeGen
import org.apache.spark.sql.catalyst.expressions.codegen.CodeFormatter
val formattedCode = CodeFormatter.format(source)
scala> println(formattedCode)
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage2(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean hashAgg_initAgg_0;
/* 010 */ private org.apache.spark.unsafe.KVIterator hashAgg_mapIter_0;
/* 011 */ private org.apache.spark.sql.execution.UnsafeFixedWidthAggregationMap hashAgg_hashMap_0;
/* 012 */ private org.apache.spark.sql.execution.UnsafeKVExternalSorter hashAgg_sorter_0;
/* 013 */ private scala.collection.Iterator inputadapter_input_0;
/* 014 */ private boolean hashAgg_hashAgg_isNull_2_0;
...
val execPlan = q.queryExecution.sparkPlan
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[_groupingexpression#8L], functions=[sum(id#0L)], output=[group#2L, sum#5L])
01 +- HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
02 +- Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
03 +- Range (0, 10, step=1, splits=16)
Going low level. Mind your steps! 😊
import org.apache.spark.sql.catalyst.plans.logical.Aggregate
val aggLog = q.queryExecution.optimizedPlan.asInstanceOf[Aggregate]
import org.apache.spark.sql.catalyst.planning.PhysicalAggregation
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression
val (_, aggregateExpressions: Seq[AggregateExpression], _, _) = PhysicalAggregation.unapply(aggLog).get
val aggregateBufferAttributes =
aggregateExpressions.flatMap(_.aggregateFunction.aggBufferAttributes)
Here comes the very reason why HashAggregateExec was selected. Aggregation execution planning strategy prefers HashAggregateExec when aggregateBufferAttributes are supported.
import org.apache.spark.sql.catalyst.plans.logical.Aggregate
assert(Aggregate.supportsHashAggregate(aggregateBufferAttributes))
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
val hashAggExec = execPlan.asInstanceOf[HashAggregateExec]
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[_groupingexpression#8L], functions=[sum(id#0L)], output=[group#2L, sum#5L])
01 +- HashAggregate(keys=[_groupingexpression#8L], functions=[partial_sum(id#0L)], output=[_groupingexpression#8L, sum#10L])
02 +- Project [id#0L, (id#0L % 2) AS _groupingexpression#8L]
03 +- Range (0, 10, step=1, splits=16)
Execute HashAggregateExec¶
val hashAggExecRDD = hashAggExec.execute
println(hashAggExecRDD.toDebugString)
(16) MapPartitionsRDD[4] at execute at <console>:1 []
| MapPartitionsRDD[3] at execute at <console>:1 []
| MapPartitionsRDD[2] at execute at <console>:1 []
| MapPartitionsRDD[1] at execute at <console>:1 []
| ParallelCollectionRDD[0] at execute at <console>:1 []
Java Code for Produce Execution Path¶
import org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext
val ctx = new CodegenContext
val parent = hashAggExec
val doProduceWithKeysCode = hashAggExec.produce(ctx, parent)
scala> println(doProduceWithKeysCode)
if (!hashAgg_initAgg_0) {
hashAgg_initAgg_0 = true;
hashAgg_hashMap_0 = ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).createHashMap();
long hashAgg_beforeAgg_1 = System.nanoTime();
hashAgg_doAggregateWithKeys_0();
((org.apache.spark.sql.execution.metric.SQLMetric) references[16] /* aggTime */).add((System.nanoTime() - hashAgg_beforeAgg_1) / 1000000);
}
// output the result
while ( hashAgg_mapIter_0.next()) {
UnsafeRow hashAgg_aggKey_1 = (UnsafeRow) hashAgg_mapIter_0.getKey();
UnsafeRow hashAgg_aggBuffer_1 = (UnsafeRow) hashAgg_mapIter_0.getValue();
hashAgg_doAggregateWithKeysOutput_1(hashAgg_aggKey_1, hashAgg_aggBuffer_1);
if (shouldStop()) return;
}
hashAgg_mapIter_0.close();
if (hashAgg_sorter_0 == null) {
hashAgg_hashMap_0.free();
}