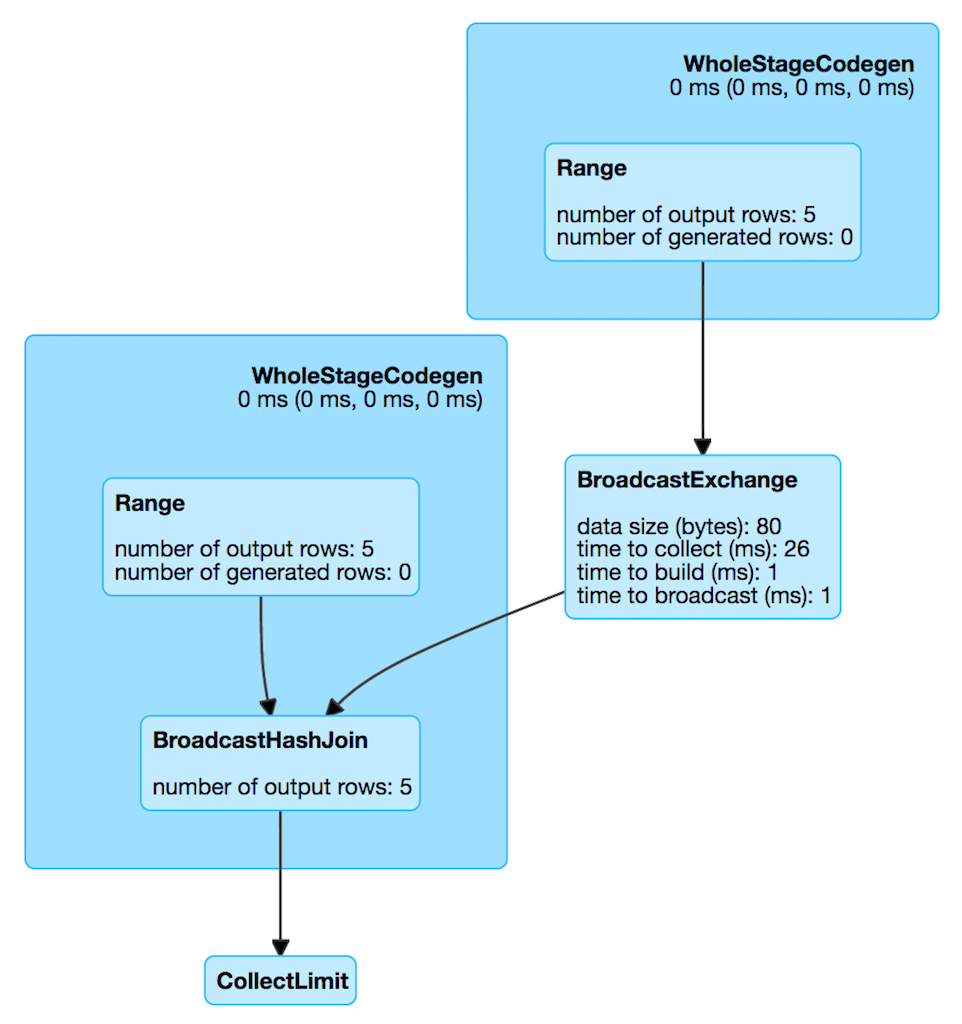
BroadcastExchangeExec Unary Physical Operator for Broadcast Joins¶
BroadcastExchangeExec is an BroadcastExchangeLike unary physical operator to collect and broadcast rows of a child relation (to worker nodes).
BroadcastExchangeExec is <
val t1 = spark.range(5)
val t2 = spark.range(5)
val q = t1.join(t2).where(t1("id") === t2("id"))
scala> q.explain
== Physical Plan ==
*BroadcastHashJoin [id#19L], [id#22L], Inner, BuildRight
:- *Range (0, 5, step=1, splits=Some(8))
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]))
+- *Range (0, 5, step=1, splits=Some(8))
[[outputPartitioning]] BroadcastExchangeExec uses BroadcastPartitioning partitioning scheme (with the input <
=== [[doExecuteBroadcast]] Waiting Until Relation Has Been Broadcast -- doExecuteBroadcast Method
[source, scala]¶
def doExecuteBroadcastT: broadcast.Broadcast[T]¶
doExecuteBroadcast waits until the <
NOTE: doExecuteBroadcast waits spark.sql.broadcastTimeout (defaults to 5 minutes).
NOTE: doExecuteBroadcast is part of SparkPlan.md#doExecuteBroadcast[SparkPlan Contract] to return the result of a structured query as a broadcast variable.
=== [[relationFuture]] Lazily-Once-Initialized Asynchronously-Broadcast relationFuture Internal Attribute
[source, scala]¶
relationFuture: Future[broadcast.Broadcast[Any]]¶
When "materialized" (aka executed), relationFuture finds the current execution id and sets it to the Future thread.
relationFuture requests <
relationFuture records the time for executeCollectIterator in <
NOTE: relationFuture accepts a relation with up to 512 millions rows and 8GB in size, and reports a SparkException if the conditions are violated.
relationFuture requests the input <transform the internal rows to create a relation, e.g. HashedRelation or a Array[InternalRow].
relationFuture calculates the data size:
-
For a
HashedRelation,relationFuturerequests it to estimatedSize -
For a
Array[InternalRow],relationFuturetransforms theInternalRowsto UnsafeRow.md[UnsafeRows] and requests each to UnsafeRow.md#getSizeInBytes[getSizeInBytes] that it sums all up.
relationFuture records the data size as the <
relationFuture records the <
relationFuture requests the SparkPlan.md#sparkContext[SparkContext] to broadcast the relation and records the time in <
In the end, relationFuture requests SQLMetrics to post a SparkListenerDriverAccumUpdates (with the execution id and the SQL metrics) and returns the broadcast internal rows.
NOTE: Since initialization of relationFuture happens on the driver, posting a SparkListenerDriverAccumUpdates is the only way how all the SQL metrics could be accessible to other subsystems using SparkListener listeners (incl. web UI).
In case of OutOfMemoryError, relationFuture reports another OutOfMemoryError with the following message:
[options="wrap"]¶
Not enough memory to build and broadcast the table to all worker nodes. As a workaround, you can either disable broadcast by setting spark.sql.autoBroadcastJoinThreshold to -1 or increase the spark driver memory by setting spark.driver.memory to a higher value¶
[[executionContext]] NOTE: relationFuture is executed on a separate thread from a custom https://www.scala-lang.org/api/2.11.8/index.html#scala.concurrent.ExecutionContext[scala.concurrent.ExecutionContext] (built from a cached https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ThreadPoolExecutor.html[java.util.concurrent.ThreadPoolExecutor] with the prefix broadcast-exchange and up to 128 threads).
NOTE: relationFuture is used when BroadcastExchangeExec is requested to <
=== [[doPrepare]] Broadcasting Relation (Rows) Asynchronously -- doPrepare Method
[source, scala]¶
doPrepare(): Unit¶
NOTE: doPrepare is part of SparkPlan.md#doPrepare[SparkPlan Contract] to prepare a physical operator for execution.
doPrepare simply "materializes" the internal lazily-once-initialized <
=== [[creating-instance]] Creating BroadcastExchangeExec Instance
BroadcastExchangeExec takes the following when created:
- [[mode]] BroadcastMode
- [[child]] Child logical plan
Performance Metrics¶
| Key | Name (in web UI) | Description |
|---|---|---|
| broadcastTime | time to broadcast (ms) | |
| buildTime | time to build (ms) | |
| collectTime | time to collect (ms) | |
| dataSize | data size (bytes) |