SparkOptimizer — Logical Query Plan Optimizer¶
SparkOptimizer is a concrete logical query plan optimizer.
SparkOptimizer offers the following extension points for additional user-defined optimization rules:
Creating Instance¶
SparkOptimizer takes the following to be created:
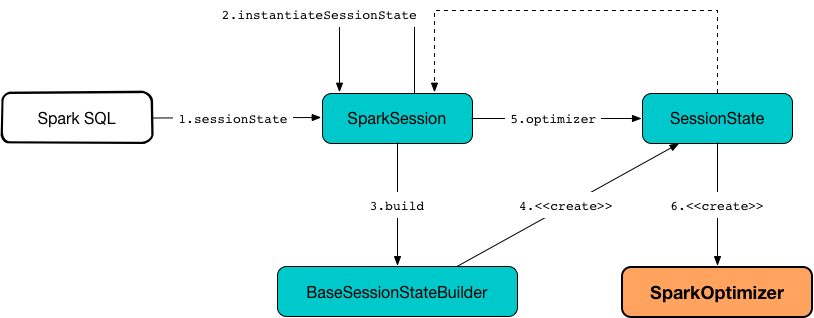
SparkOptimizer is created when SessionState is requested for a logical query plan optimizer (indirectly using BaseSessionStateBuilder is requested for an Optimizer).
earlyScanPushDownRules¶
Signature
earlyScanPushDownRules: Seq[Rule[LogicalPlan]]
earlyScanPushDownRules is part of the Optimizer abstraction.
earlyScanPushDownRules adds the following rules to the default nonExcludableRules:
ExtractPythonUDFFromJoinConditionExtractPythonUDFFromAggregateExtractGroupingPythonUDFFromAggregateExtractPythonUDFs- GroupBasedRowLevelOperationScanPlanning
- V2ScanRelationPushDown
V2ScanPartitioningAndOrdering- V2Writes
ReplaceCTERefWithRepartition
Default Rule Batches¶
SparkOptimizer overrides the optimization rules.
Pre-Optimization Batches (Extension Point)¶
preOptimizationBatches: Seq[Batch]
Extension point for Pre-Optimization Batches that are executed first (before the regular optimization batches and the defaultBatches).
Base Logical Optimization Batches¶
Optimization rules of the base Logical Optimizer
Optimize Metadata Only Query¶
Rules:
Strategy: Once
PartitionPruning¶
Rules:
Strategy: Once
Pushdown Filters from PartitionPruning¶
Rules:
Strategy: fixedPoint
Cleanup filters that cannot be pushed down¶
Rules:
- CleanupDynamicPruningFilters
BooleanSimplification- PruneFilters
Strategy: Once
Post-Hoc Optimization Batches (Extension Point)¶
postHocOptimizationBatches: Seq[Batch] = Nil
Extension point for Post-Hoc Optimization Batches
Extract Python UDFs¶
Rules:
ExtractPythonUDFFromJoinConditionCheckCartesianProducts- ExtractPythonUDFFromAggregate
ExtractGroupingPythonUDFFromAggregateExtractPythonUDFsColumnPruningPushPredicateThroughNonJoinRemoveNoopOperators
Strategy: Once
User Provided Optimizers (Extension Point)¶
Extension point for Extra Optimization Rules using the given ExperimentalMethods
Strategy: fixedPoint
Non-Excludable Rules¶
nonExcludableRules: Seq[String]
nonExcludableRules is part of the Optimizer abstraction.
nonExcludableRules adds the following optimization rules to the existing nonExcludableRules:
ExtractGroupingPythonUDFFromAggregateExtractPythonUDFFromAggregateExtractPythonUDFFromJoinConditionExtractPythonUDFsGroupBasedRowLevelOperationScanPlanningReplaceCTERefWithRepartitionV2ScanPartitioning- V2ScanRelationPushDown
- V2Writes
Accessing SparkOptimizer¶
SparkOptimizer is available as the optimizer property of a session-specific SessionState.
scala> :type spark
org.apache.spark.sql.SparkSession
scala> :type spark.sessionState.optimizer
org.apache.spark.sql.catalyst.optimizer.Optimizer
// It is a SparkOptimizer really.
// Let's check that out with a type cast
import org.apache.spark.sql.execution.SparkOptimizer
scala> spark.sessionState.optimizer.isInstanceOf[SparkOptimizer]
res1: Boolean = true
The optimized logical plan of a structured query is available as QueryExecution.optimizedPlan.
// Applying two filter in sequence on purpose
// We want to kick CombineTypedFilters optimizer in
val dataset = spark.range(10).filter(_ % 2 == 0).filter(_ == 0)
// optimizedPlan is a lazy value
// Only at the first time you call it you will trigger optimizations
// Next calls end up with the cached already-optimized result
// Use explain to trigger optimizations again
scala> dataset.queryExecution.optimizedPlan
res0: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], newInstance(class java.lang.Long)
+- Range (0, 10, step=1, splits=Some(8))
Logging¶
Enable ALL logging level for org.apache.spark.sql.execution.SparkOptimizer logger to see what happens inside.
Add the following line to conf/log4j2.properties:
log4j.logger.org.apache.spark.sql.execution.SparkOptimizer=ALL
Refer to Logging.