QueryExecution — Structured Query Execution Pipeline¶
QueryExecution is the execution pipeline (workflow) of a structured query.
QueryExecution is made up of execution stages (phases).
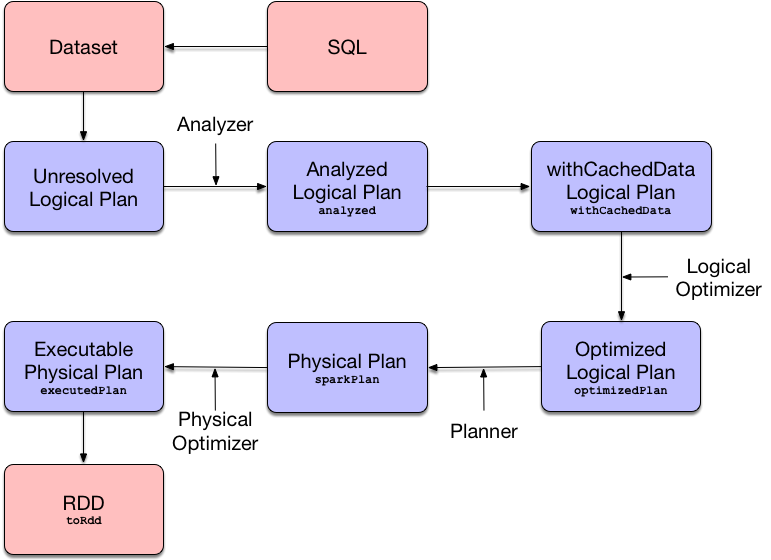
QueryExecution is the result of executing a LogicalPlan in a SparkSession (and so you could create a Dataset from a logical operator or use the QueryExecution after executing a logical operator).
val plan: LogicalPlan = ...
val qe = new QueryExecution(sparkSession, plan)
Creating Instance¶
QueryExecution takes the following to be created:
QueryExecution is created when:
- Dataset.ofRows and Dataset.selectUntyped are executed
KeyValueGroupedDatasetis requested to aggUntypedCommandUtilsutility is requested to computeColumnStats and computePercentilesBaseSessionStateBuilderis requested to create a QueryExecution for a LogicalPlan
QueryPlanningTracker¶
QueryExecution can be given a QueryPlanningTracker when created.
Accessing QueryExecution¶
QueryExecution is part of Dataset using queryExecution attribute.
ds.queryExecution
Execution Pipeline Phases¶
Analyzed Logical Plan¶
Analyzed logical plan that has passed Logical Analyzer.
Tip
Beside analyzed, you can use Dataset.explain basic action (with extended flag enabled) or SQL's EXPLAIN EXTENDED to see the analyzed logical plan of a structured query.
Analyzed Logical Plan with Cached Data¶
Analyzed logical plan after CacheManager was requested to replace logical query segments with cached query plans.
withCachedData makes sure that the logical plan was analyzed and uses supported operations only.
Optimized Logical Plan¶
Logical plan after executing the logical query plan optimizer on the withCachedData logical plan.
Physical Plan¶
Physical plan (after SparkPlanner has planned the optimized logical plan).
sparkPlan is the first physical plan from the collection of all possible physical plans.
Note
It is guaranteed that Catalyst's QueryPlanner (which SparkPlanner extends) will always generate at least one physical plan.
Optimized Physical Plan¶
Optimized physical plan that is in the final optimized "shape" and therefore ready for execution, i.e. the physical sparkPlan with physical preparation rules applied.
RDD¶
toRdd: RDD[InternalRow]
Spark Core's execution graph of a distributed computation (RDD of internal binary rows) from the executedPlan after execution.
The RDD is the top-level RDD of the DAG of RDDs (that represent physical operators).
Note
toRdd is a "boundary" between two Spark modules: Spark SQL and Spark Core.
After you have executed toRdd (directly or not), you basically "leave" Spark SQL's Dataset world and "enter" Spark Core's RDD space.
toRdd triggers a structured query execution (i.e. physical planning, but not execution of the plan) using SparkPlan.execute that recursively triggers execution of every child physical operator in the physical plan tree.
Note
SparkSession.internalCreateDataFrame applies a schema to an RDD[InternalRow].
Note
Dataset.rdd gives the RDD[InternalRow] with internal binary rows deserialized to a concrete Scala type.
You can access the lazy attributes as follows:
val dataset: Dataset[Long] = ...
dataset.queryExecution.executedPlan
QueryExecution uses the Logical Query Optimizer and Tungsten for better structured query performance.
QueryExecution uses the input SparkSession to access the current SparkPlanner (through SessionState) when <PhysicalPlan exactly) using the planner. It is available as the <
Note
A variant of QueryExecution that Spark Structured Streaming uses for query planning is IncrementalExecution.
Refer to IncrementalExecution — QueryExecution of Streaming Datasets in the Spark Structured Streaming online gitbook.
SparkPlanner¶
Text Representation With Statistics¶
stringWithStats: String
stringWithStats...FIXME
stringWithStats is used when ExplainCommand logical command is executed (with cost flag enabled).
Physical Query Optimizations¶
Physical Query Optimizations are Catalyst Rules for transforming physical operators (to be more efficient and optimized for execution). They are executed in the following order:
- InsertAdaptiveSparkPlan (if defined)
- CoalesceBucketsInJoin
- PlanDynamicPruningFilters
- PlanSubqueries
- RemoveRedundantProjects
- EnsureRequirements
- RemoveRedundantSorts
- DisableUnnecessaryBucketedScan
- ApplyColumnarRulesAndInsertTransitions
- CollapseCodegenStages
- ReuseExchange
- ReuseSubquery
preparations¶
preparations: Seq[Rule[SparkPlan]]
preparations creates an InsertAdaptiveSparkPlan (with a new AdaptiveExecutionContext) that is added to the other preparations rules.
preparations is used when:
QueryExecutionis requested for an optimized physical query plan
preparations Internal Utility¶
preparations(
sparkSession: SparkSession,
adaptiveExecutionRule: Option[InsertAdaptiveSparkPlan] = None): Seq[Rule[SparkPlan]]
preparations is the Physical Query Optimizations.
preparations is used when:
QueryExecutionis requested for the physical optimization rules (preparations) (with theInsertAdaptiveSparkPlandefined)QueryExecutionutility is requested to prepareExecutedPlan (with noInsertAdaptiveSparkPlan)
prepareExecutedPlan¶
prepareExecutedPlan for Physical Operators¶
prepareExecutedPlan(
spark: SparkSession,
plan: SparkPlan): SparkPlan
prepareExecutedPlan applies the preparations physical query optimization rules (with no InsertAdaptiveSparkPlan optimization) to the physical plan.
prepareExecutedPlan is used when:
-
QueryExecutionutility is requested to prepareExecutedPlan for a logical operator -
PlanDynamicPruningFilters physical optimization is executed
prepareExecutedPlan for Logical Operators¶
prepareExecutedPlan(
spark: SparkSession,
plan: LogicalPlan): SparkPlan
prepareExecutedPlan is...FIXME
prepareExecutedPlan is used when PlanSubqueries physical optimization is executed.
Applying preparations Physical Query Optimization Rules to Physical Plan¶
prepareForExecution(
preparations: Seq[Rule[SparkPlan]],
plan: SparkPlan): SparkPlan
prepareForExecution takes physical preparation rules and executes them one by one with the given SparkPlan.
prepareForExecution is used when:
QueryExecutionis requested to prepare the physical plan for execution and prepareExecutedPlan
assertSupported¶
assertSupported(): Unit
assertSupported requests UnsupportedOperationChecker to checkForBatch.
assertSupported is used when:
QueryExecutionis requested for the withCachedData logical plan.
Creating Analyzed Logical Plan and Checking Correctness¶
assertAnalyzed(): Unit
assertAnalyzed triggers initialization of analyzed (which is almost like executing it).
assertAnalyzed executes analyzed by accessing it and throwing the result away. Since analyzed is a lazy value in Scala, it will then get initialized for the first time and stays so forever.
assertAnalyzed then requests Analyzer to validate analysis of the logical plan (i.e. analyzed).
Note
assertAnalyzed uses SparkSession to access the current SessionState that it then uses to access the Analyzer.
In case of any AnalysisException, assertAnalyzed creates a new AnalysisException to make sure that it holds analyzed and reports it.
Building Text Representation with Cost Stats¶
toStringWithStats: String
toStringWithStats is a mere alias for completeString with appendStats flag enabled.
toStringWithStats is a custom toString with cost statistics.
val dataset = spark.range(20).limit(2)
// toStringWithStats in action - note Optimized Logical Plan section with Statistics
scala> dataset.queryExecution.toStringWithStats
res6: String =
== Parsed Logical Plan ==
GlobalLimit 2
+- LocalLimit 2
+- Range (0, 20, step=1, splits=Some(8))
== Analyzed Logical Plan ==
id: bigint
GlobalLimit 2
+- LocalLimit 2
+- Range (0, 20, step=1, splits=Some(8))
== Optimized Logical Plan ==
GlobalLimit 2, Statistics(sizeInBytes=32.0 B, rowCount=2, isBroadcastable=false)
+- LocalLimit 2, Statistics(sizeInBytes=160.0 B, isBroadcastable=false)
+- Range (0, 20, step=1, splits=Some(8)), Statistics(sizeInBytes=160.0 B, isBroadcastable=false)
== Physical Plan ==
CollectLimit 2
+- *Range (0, 20, step=1, splits=Some(8))
toStringWithStats is used when ExplainCommand logical command is executed (with cost attribute enabled).
Extended Text Representation with Logical and Physical Plans¶
toString: String
toString is a mere alias for completeString with appendStats flag disabled.
Note
toString is on the "other" side of toStringWithStats which has appendStats flag enabled.
toString is part of Java's Object abstraction.
Simple (Basic) Text Representation¶
simpleString: String // (1)
simpleString(
formatted: Boolean): String
formattedisfalse
simpleString requests the optimized physical plan for the text representation (of all nodes in the query tree) with verbose flag turned off.
In the end, simpleString adds == Physical Plan == header to the text representation and redacts sensitive information.
simpleString is used when:
QueryExecutionis requested to explainString- others
Demo¶
import org.apache.spark.sql.{functions => f}
val q = spark.range(10).withColumn("rand", f.rand())
val output = q.queryExecution.simpleString
scala> println(output)
== Physical Plan ==
*(1) Project [id#53L, rand(-5226178239369056152) AS rand#55]
+- *(1) Range (0, 10, step=1, splits=16)
explainString¶
explainString(
mode: ExplainMode): String
explainString(
mode: ExplainMode,
maxFields: Int,
append: String => Unit): Unit
explainString...FIXME
explainString is used when:
Datasetis requested to explainSQLExecutionutility is used to withNewExecutionIdAdaptiveSparkPlanExecleaf physical operator is requested to onUpdatePlanExplainCommandlogical command is executeddebugutility is used totoFile
Redacting Sensitive Information¶
withRedaction(
message: String): String
withRedaction takes the value of spark.sql.redaction.string.regex configuration property (as the regular expression to point at sensitive information) and requests Spark Core's Utils to redact sensitive information in the input message.
NOTE: Internally, Spark Core's Utils.redact uses Java's Regex.replaceAllIn to replace all matches of a pattern with a string.
NOTE: withRedaction is used when QueryExecution is requested for the <
writePlans¶
writePlans(
append: String => Unit,
maxFields: Int): Unit
writePlans...FIXME
writePlans is used when...FIXME