Dataset¶
Dataset[T] is a strongly-typed data structure that represents a structured query over rows of T type.
Dataset is created using SQL or Dataset high-level declarative "languages".
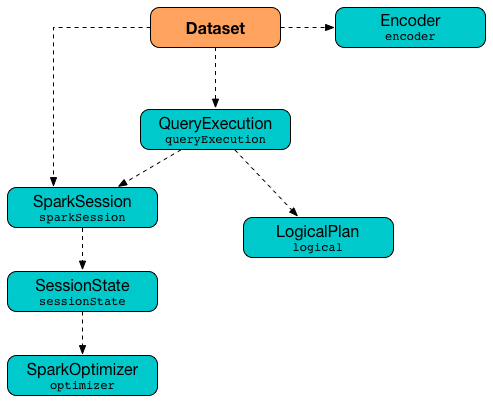
It is fair to say that Dataset is a Spark SQL developer-friendly layer over the following two low-level entities:
-
QueryExecution (with the parsed yet unanalyzed LogicalPlan of a structured query)
-
Encoder (of the type of the records for fast serialization and deserialization to and from InternalRow)
Creating Instance¶
Dataset takes the following when created:
Note
Dataset can be created using LogicalPlan when executed using SessionState.
When created, Dataset requests QueryExecution to assert analyzed phase is successful.
observe¶
observe(
observation: Observation,
expr: Column,
exprs: Column*): Dataset[T]
observe(
name: String,
expr: Column,
exprs: Column*): Dataset[T]
When executed with name argument, observe creates a typed Dataset with a CollectMetrics logical operator.
For an Observation argument, observe requests the Observation to observe this Dataset (that in turn uses the name-argument observe).
Requirements
- An
Observationcan be used with aDatasetonly once Observationdoes not support streamingDatasets.
repartition¶
repartition(
partitionExprs: Column*): Dataset[T] // (1)!
repartition(
numPartitions: Int): Dataset[T] // (2)!
repartition(
numPartitions: Int,
partitionExprs: Column*): Dataset[T] // (3)!
- An alias of repartitionByExpression with undefined
numPartitions - Creates a Repartition logical operator with
shuffleenabled - An alias of repartitionByExpression
repartitionByExpression¶
repartitionByExpression(
numPartitions: Option[Int],
partitionExprs: Seq[Column]): Dataset[T]
repartitionByExpression withTypedPlan with a new RepartitionByExpression (with the given numPartitions and partitionExprs, and the logicalPlan).
Example: Number of Partitions Only¶
val numsRepd = nums.repartition(numPartitions = 4)
assert(numsRepd.rdd.getNumPartitions == 4, "Number of partitions should be 4")
scala> numsRepd.explain(extended = true)
== Parsed Logical Plan ==
Repartition 4, true
+- RepartitionByExpression [id#4L ASC NULLS FIRST]
+- Range (0, 10, step=1, splits=Some(16))
== Analyzed Logical Plan ==
id: bigint
Repartition 4, true
+- RepartitionByExpression [id#4L ASC NULLS FIRST]
+- Range (0, 10, step=1, splits=Some(16))
== Optimized Logical Plan ==
Repartition 4, true
+- Range (0, 10, step=1, splits=Some(16))
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Exchange RoundRobinPartitioning(4), REPARTITION_BY_NUM, [id=#75]
+- Range (0, 10, step=1, splits=16)
repartitionByRange¶
repartitionByRange(
partitionExprs: Column*): Dataset[T]
repartitionByRange(
numPartitions: Int,
partitionExprs: Column*): Dataset[T]
repartitionByRange(
numPartitions: Option[Int],
partitionExprs: Seq[Column]): Dataset[T] // (1)!
- A private method
repartitionByRange creates a SortOrders with Ascending sorting direction (ascending nulls first) for the given partitionExprs with no sorting specified.
In the end, repartitionByRange creates a Dataset with a RepartitionByExpression (with the SortOrders, the logicalPlan and the given numPartitions).
Example: Partition Expressions Only¶
val nums = spark.range(10).repartitionByRange($"id".asc)
scala> println(nums.queryExecution.logical.numberedTreeString)
00 'RepartitionByExpression ['id ASC NULLS FIRST]
01 +- Range (0, 10, step=1, splits=Some(16))
Note
Adaptive Query Execution is enabled.
scala> println(nums.queryExecution.toRdd.getNumPartitions)
1
scala> println(nums.queryExecution.toRdd.toDebugString)
(1) SQLExecutionRDD[17] at toRdd at <console>:24 []
| ShuffledRowRDD[16] at toRdd at <console>:24 []
+-(16) MapPartitionsRDD[15] at toRdd at <console>:24 []
| MapPartitionsRDD[11] at toRdd at <console>:24 []
| MapPartitionsRDD[10] at toRdd at <console>:24 []
| ParallelCollectionRDD[9] at toRdd at <console>:24 []
Example: Number of Partitions and Partition Expressions¶
val q = spark.range(10).repartitionByRange(numPartitions = 5, $"id")
scala> println(q.queryExecution.logical.numberedTreeString)
00 'RepartitionByExpression ['id ASC NULLS FIRST], 5
01 +- Range (0, 10, step=1, splits=Some(16))
scala> println(q.queryExecution.toRdd.getNumPartitions)
5
scala> println(q.queryExecution.toRdd.toDebugString)
(5) SQLExecutionRDD[8] at toRdd at <console>:24 []
| ShuffledRowRDD[7] at toRdd at <console>:24 []
+-(16) MapPartitionsRDD[6] at toRdd at <console>:24 []
| MapPartitionsRDD[2] at toRdd at <console>:24 []
| MapPartitionsRDD[1] at toRdd at <console>:24 []
| ParallelCollectionRDD[0] at toRdd at <console>:24 []
LogicalPlan¶
logicalPlan: LogicalPlan
Dataset initializes an internal LogicalPlan when created.
logicalPlan requests the QueryExecution for a LogicalPlan (with commands executed per the command execution mode).
With SQLConf.FAIL_AMBIGUOUS_SELF_JOIN_ENABLED enabled, logicalPlan...FIXME. Otherwise, logicalPlan returns the LogicalPlan intact.
Lazy Values¶
The following are Scala lazy values of Dataset. Using lazy values guarantees that the code to initialize them is executed once only (when accessed for the first time) and the computed value never changes afterwards.
Learn more in the Scala Language Specification.
RDD¶
rdd: RDD[T]
rdd ...FIXME
rdd is used when:
Datasetis requested for an RDD and withNewRDDExecutionId
QueryExecution¶
rddQueryExecution: QueryExecution
rddQueryExecution creates a deserializer for the T type and the logical query plan of this Dataset.
In other words, rddQueryExecution simply adds a new DeserializeToObject unary logical operator as the parent of the current logical query plan (that in turn becomes a child operator).
In the end, rddQueryExecution requests the SparkSession for the SessionState to create a QueryExecution for the query plan with the top-most DeserializeToObject.
rddQueryExecution is used when:
Datasetis requested for an RDD and withNewRDDExecutionId
withNewRDDExecutionId¶
withNewRDDExecutionId[U](
body: => U): U
withNewRDDExecutionId executes the input body action (that produces the result of type U) under a new execution id (with the QueryExecution).
withNewRDDExecutionId requests the QueryExecution for the SparkPlan to resetMetrics.
withNewRDDExecutionId is used when the following Dataset operators are used:
writeTo¶
writeTo(
table: String): DataFrameWriterV2[T]
writeTo creates a DataFrameWriterV2 for the input table and this Dataset.
write¶
write: DataFrameWriter[T]
write creates a DataFrameWriter for this Dataset.
withTypedPlan¶
withTypedPlan[U : Encoder](
logicalPlan: LogicalPlan): Dataset[U]
Final Method
withTypedPlan is annotated with @inline annotation that requests the Scala compiler to try especially hard to inline it
withTypedPlan...FIXME
withSetOperator¶
withSetOperator[U: Encoder](
logicalPlan: LogicalPlan): Dataset[U]
Final Method
withSetOperator is annotated with @inline annotation that requests the Scala compiler to try especially hard to inline it
withSetOperator...FIXME
apply¶
apply[T: Encoder](
sparkSession: SparkSession,
logicalPlan: LogicalPlan): Dataset[T]
apply...FIXME
apply is used when:
Datasetis requested to withTypedPlan and withSetOperator
Executing Action Under New Execution ID¶
withAction[U](
name: String,
qe: QueryExecution)(
action: SparkPlan => U)
withAction creates a new execution ID to execute the given action with the optimized physical query plan (of the given QueryExecution).
withAction resets the performance metrics.
withAction is used to execute the following Dataset actions:
| Action | Name |
|---|---|
| isEmpty | isEmpty |
| checkpoint | checkpoint or localCheckpoint |
| head | head |
| tail | tail |
| collect | collect |
| collectAsList | collectAsList |
| toLocalIterator | toLocalIterator |
| count | count |
| collectToPython | collectToPython |
| tailToPython | tailToPython |
| collectAsArrowToR | collectAsArrowToR |
| collectAsArrowToPython | collectAsArrowToPython |
collectAsArrowToPython¶
collectAsArrowToPython: Array[Any]
collectAsArrowToPython...FIXME
collectAsArrowToPython is used when:
PandasConversionMixin(PySpark) is requested to_collect_as_arrow
collectToPython¶
collectToPython(): Array[Any]
collectToPython...FIXME
collectToPython is used when:
DataFrame(PySpark) is requested tocollect
unionAll¶
unionAll(
other: Dataset[T]): Dataset[T]
unionAll is a synonym of union.
union¶
union(
other: Dataset[T]): Dataset[T]
union combineUnions with a Union logical operator with this logicalPlan and the other's logicalPlan.
combineUnions¶
combineUnions(
plan: LogicalPlan): LogicalPlan
combineUnions...FIXME
combineUnions is used when:
- Dataset.union operator is used
- Dataset.unionByName operator is used
flattenUnion¶
flattenUnion(
u: Union,
isUnionDistinct: Boolean): Union
flattenUnion...FIXME