Logical Query Plan Analyzer¶
Analyzer (Spark Analyzer or Query Analyzer) is the logical query plan analyzer that validates and transforms an unresolved logical plan to an analyzed logical plan.
Analyzer is a RuleExecutor to transform logical operators (RuleExecutor[LogicalPlan]).
Analyzer: Unresolved Logical Plan ==> Analyzed Logical Plan
Analyzer is used by QueryExecution to resolve the managed LogicalPlan (and, as a sort of follow-up, assert that a structured query has already been properly analyzed, i.e. no failed or unresolved or somehow broken logical plan operators and expressions exist).
extendedResolutionRules Extension Point¶
extendedResolutionRules: Seq[Rule[LogicalPlan]] = Nil
extendedResolutionRules is an extension point for additional logical evaluation rules for Resolution batch. The rules are added at the end of the Resolution batch.
Default: empty
Note
SessionState uses its own Analyzer with custom extendedResolutionRules, postHocResolutionRules, and extendedCheckRules extension methods.
postHocResolutionRules Extension Point¶
postHocResolutionRules: Seq[Rule[LogicalPlan]] = Nil
postHocResolutionRules is an extension point for rules in Post-Hoc Resolution batch if defined (that are executed in one pass, i.e. Once strategy).
Default: empty
Batches¶
Hints¶
Rules:
Strategy: fixedPoint
Simple Sanity Check¶
Rules:
Strategy: Once
Substitution¶
Rules:
OptimizeUpdateFields- CTESubstitution
- BindParameters
- WindowsSubstitution
EliminateUnionsSubstituteUnresolvedOrdinals
Strategy: fixedPoint
Resolution¶
Rules:
- ResolveTableValuedFunctions
- ResolveNamespace
- ResolveCatalogs
- ResolveInsertInto
- ResolveRelations
- ResolveGroupingAnalytics
- ResolveAggregateFunctions
- ResolveWithCTE
- extendedResolutionRules
- others
Strategy: fixedPoint
Post-Hoc Resolution¶
Rules:
Strategy: Once
Normalize Alter Table¶
Rules:
- ResolveAlterTableChanges
Strategy: Once
Remove Unresolved Hints¶
Rules:
- RemoveAllHints
Strategy: Once
Nondeterministic¶
Rules:
- PullOutNondeterministic
Strategy: Once
UDF¶
Rules:
HandleNullInputsForUDF
Strategy: Once
UpdateNullability¶
Rules:
- UpdateAttributeNullability
Strategy: Once
Subquery¶
Rules:
UpdateOuterReferences
Strategy: Once
Cleanup¶
Rules:
Strategy: fixedPoint
Creating Instance¶
Analyzer takes the following to be created:
- CatalogManager
- SQLConf
- Maximum number of iterations (of the FixedPoint rule batches)
Analyzer is created when SessionState is requested for the analyzer.
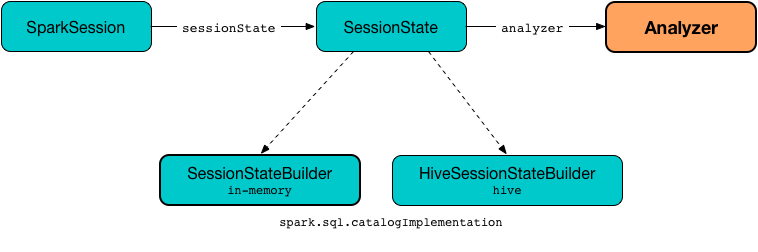
Accessing Analyzer¶
Analyzer is available as the analyzer property of SessionState.
scala> :type spark
org.apache.spark.sql.SparkSession
scala> :type spark.sessionState.analyzer
org.apache.spark.sql.catalyst.analysis.Analyzer
You can access the analyzed logical plan of a structured query using Dataset.explain basic action (with extended flag enabled) or SQL's EXPLAIN EXTENDED SQL command.
// sample structured query
val inventory = spark
.range(5)
.withColumn("new_column", 'id + 5 as "plus5")
// Using explain operator (with extended flag enabled)
scala> inventory.explain(extended = true)
== Parsed Logical Plan ==
'Project [id#0L, ('id + 5) AS plus5#2 AS new_column#3]
+- AnalysisBarrier
+- Range (0, 5, step=1, splits=Some(8))
== Analyzed Logical Plan ==
id: bigint, new_column: bigint
Project [id#0L, (id#0L + cast(5 as bigint)) AS new_column#3L]
+- Range (0, 5, step=1, splits=Some(8))
== Optimized Logical Plan ==
Project [id#0L, (id#0L + 5) AS new_column#3L]
+- Range (0, 5, step=1, splits=Some(8))
== Physical Plan ==
*(1) Project [id#0L, (id#0L + 5) AS new_column#3L]
+- *(1) Range (0, 5, step=1, splits=8)
Alternatively, you can access the analyzed logical plan using QueryExecution and its analyzed property (that together with numberedTreeString method is a very good "debugging" tool).
val analyzedPlan = inventory.queryExecution.analyzed
scala> println(analyzedPlan.numberedTreeString)
00 Project [id#0L, (id#0L + cast(5 as bigint)) AS new_column#3L]
01 +- Range (0, 5, step=1, splits=Some(8))
FixedPoint¶
FixedPoint with maxIterations for Hints, Substitution, Resolution and Cleanup batches.
expandRelationName¶
expandRelationName(
nameParts: Seq[String]): Seq[String]
expandRelationName...FIXME
expandRelationName is used when ResolveTables and ResolveRelations logical analysis rules are executed.
Logging¶
Enable ALL logging level for the respective session-specific loggers to see what happens inside Analyzer:
-
org.apache.spark.sql.internal.SessionState$$anon$1 -
org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1for Hive support
Add the following line to conf/log4j2.properties:
# with no Hive support
log4j.logger.org.apache.spark.sql.internal.SessionState$$anon$1=ALL
# with Hive support enabled
log4j.logger.org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1=ALL
Note
The reason for such weird-looking logger names is that analyzer attribute is created as an anonymous subclass of Analyzer class in the respective SessionStates.
Refer to Logging.