PoolPage¶
PoolPage is a WebUIPage of StagesTab.
Creating Instance¶
PoolPage takes the following to be created:
- Parent StagesTab
URL Prefix¶
PoolPage uses pool URL prefix.
Rendering Page¶
render is part of the WebUIPage abstraction.
render requires poolname and attempt request parameters.
render renders a Fair Scheduler Pool page with the PoolData (from the AppStatusStore of the parent StagesTab).
Introduction¶
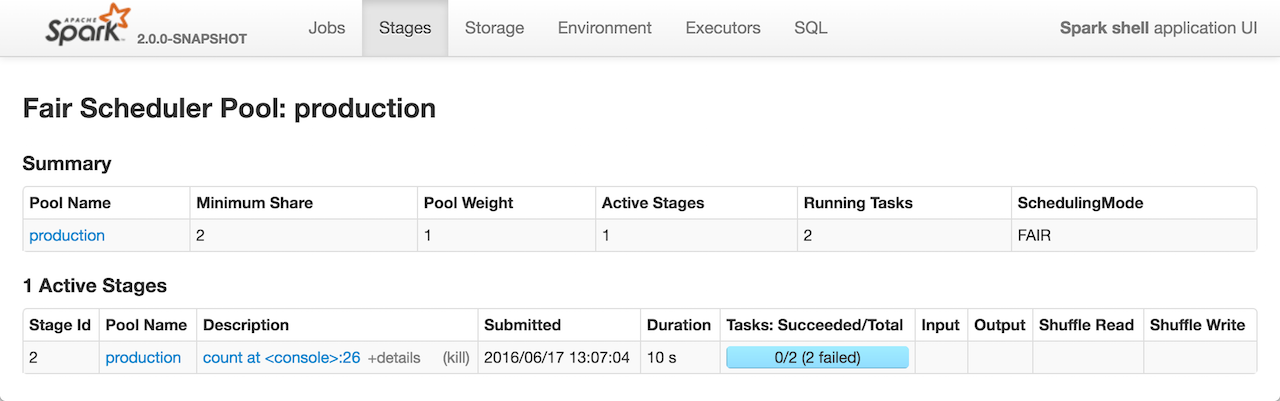
The Fair Scheduler Pool Details page shows information about a Schedulable pool and is only available when a Spark application uses the FAIR scheduling mode.
Summary Table¶
The Summary table shows the details of a Schedulable pool.

It uses the following columns:
- Pool Name
- Minimum Share
- Pool Weight
- Active Stages (the number of the active stages in a
Schedulablepool) - Running Tasks
- SchedulingMode
Active Stages Table¶
The Active Stages table shows the active stages in a pool.
