BlockManagerMaster¶
BlockManagerMaster runs on the driver and executors to exchange block metadata (status and locations) in a Spark application.
BlockManagerMaster uses BlockManagerMasterEndpoint (registered as BlockManagerMaster RPC endpoint on the driver with the endpoint references on executors) for executors to send block status updates and so let the driver keep track of block status and locations.
Creating Instance¶
BlockManagerMaster takes the following to be created:
- Driver Endpoint
- Heartbeat Endpoint
- SparkConf
-
isDriverflag (whether it is created for the driver or executors)
BlockManagerMaster is created when:
SparkEnvutility is used to create a SparkEnv (and create a BlockManager)
Driver Endpoint¶
BlockManagerMaster is given a RpcEndpointRef of the BlockManagerMaster RPC Endpoint (on the driver) when created.
Heartbeat Endpoint¶
BlockManagerMaster is given a RpcEndpointRef of the BlockManagerMasterHeartbeat RPC Endpoint (on the driver) when created.
The endpoint is used (mainly) when:
DAGScheduleris requested to executorHeartbeatReceived
Registering BlockManager (on Executor) with Driver¶
registerBlockManager(
id: BlockManagerId,
localDirs: Array[String],
maxOnHeapMemSize: Long,
maxOffHeapMemSize: Long,
storageEndpoint: RpcEndpointRef): BlockManagerId
registerBlockManager prints out the following INFO message to the logs (with the given BlockManagerId):
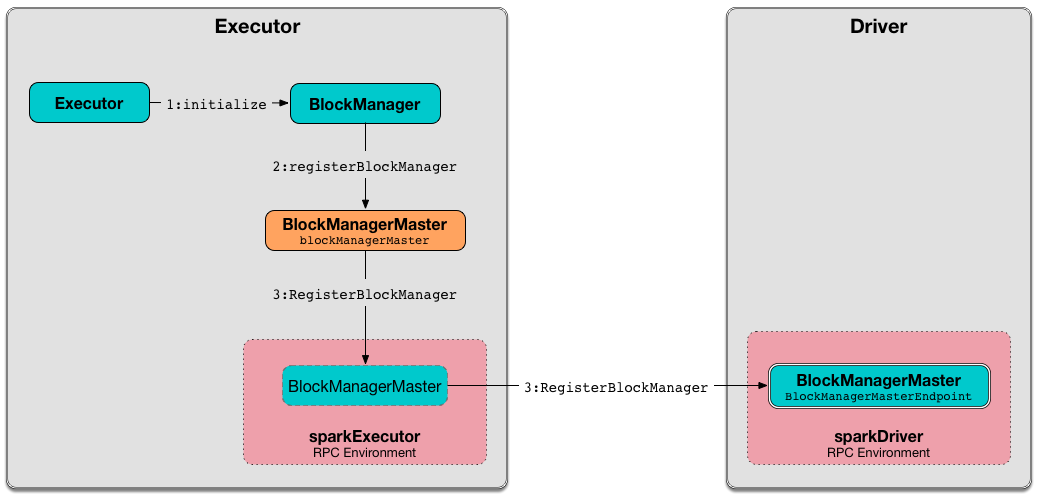
registerBlockManager notifies the driver (using the BlockManagerMaster RPC endpoint) that the BlockManagerId wants to register (and sends a blocking RegisterBlockManager message).
Note
The input maxMemSize is the total available on-heap and off-heap memory for storage on the BlockManager.
registerBlockManager waits until a confirmation comes (as a possibly-updated BlockManagerId).
In the end, registerBlockManager prints out the following INFO message to the logs and returns the BlockManagerId received.
registerBlockManager is used when:
BlockManageris requested to initialize and reregisterFallbackStorageutility is used to registerBlockManagerIfNeeded
Finding Block Locations for Single Block¶
getLocations requests the driver (using the BlockManagerMaster RPC endpoint) for BlockManagerIds of the given BlockId (and sends a blocking GetLocations message).
getLocations is used when:
BlockManageris requested to fetchRemoteManagedBufferBlockManagerMasteris requested to contains a BlockId
Finding Block Locations for Multiple Blocks¶
getLocations requests the driver (using the BlockManagerMaster RPC endpoint) for BlockManagerIds of the given BlockIds (and sends a blocking GetLocationsMultipleBlockIds message).
getLocations is used when:
DAGScheduleris requested for BlockManagers (executors) for cached RDD partitionsBlockManageris requested to getLocationBlockIdsBlockManagerutility is used to blockIdsToLocations
contains¶
contains is positive (true) when there is at least one executor with the given BlockId.
contains is used when:
LocalRDDCheckpointDatais requested to doCheckpoint
Logging¶
Enable ALL logging level for org.apache.spark.storage.BlockManagerMaster logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.