BlockManager¶
BlockManager manages the storage for blocks (chunks of data) that can be stored in memory and on disk.
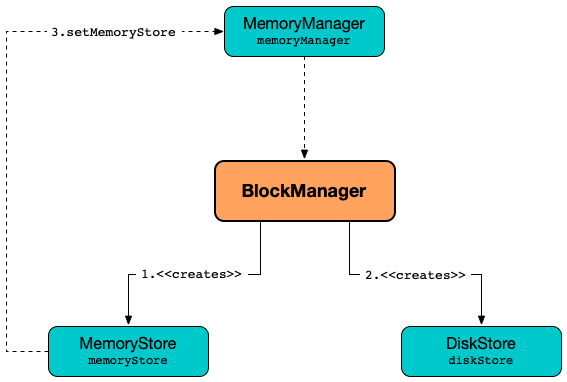
BlockManager runs as part of the driver and executor processes.
BlockManager provides interface for uploading and fetching blocks both locally and remotely using various stores (i.e. memory, disk, and off-heap).
Cached blocks are blocks with non-zero sum of memory and disk sizes.
Tip
Use spark-submit's command-line options (i.e. --driver-memory for the driver and --executor-memory for executors) or their equivalents as Spark properties (i.e. spark.executor.memory and spark.driver.memory) to control the memory for storage memory.
When External Shuffle Service is enabled, BlockManager uses ExternalShuffleClient to read shuffle files (of other executors).
Creating Instance¶
BlockManager takes the following to be created:
- Executor ID
- RpcEnv
- BlockManagerMaster
- SerializerManager
- SparkConf
- MemoryManager
- MapOutputTracker
- ShuffleManager
- BlockTransferService
-
SecurityManager - Optional ExternalBlockStoreClient
When created, BlockManager sets externalShuffleServiceEnabled internal flag based on spark.shuffle.service.enabled configuration property.
BlockManager then creates an instance of DiskBlockManager (requesting deleteFilesOnStop when an external shuffle service is not in use).
BlockManager creates block-manager-future daemon cached thread pool with 128 threads maximum (as futureExecutionContext).
BlockManager calculates the maximum memory to use (as maxMemory) by requesting the maximum on-heap and off-heap storage memory from the assigned MemoryManager.
BlockManager calculates the port used by the external shuffle service (as externalShuffleServicePort).
BlockManager creates a client to read other executors' shuffle files (as shuffleClient). If the external shuffle service is used...FIXME
BlockManager sets the maximum number of failures before this block manager refreshes the block locations from the driver (as maxFailuresBeforeLocationRefresh).
BlockManager registers a BlockManagerSlaveEndpoint with the input RpcEnv, itself, and MapOutputTracker (as slaveEndpoint).
BlockManager is created when SparkEnv is created (for the driver and executors) when a Spark application starts.
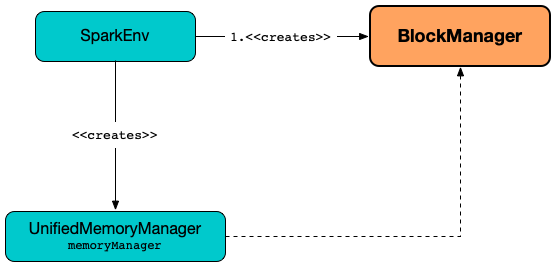
MemoryManager¶
BlockManager is given a MemoryManager when created.
BlockManager uses the MemoryManager for the following:
-
Create a MemoryStore (that is then assigned to MemoryManager as a "circular dependency")
-
Initialize maxOnHeapMemory and maxOffHeapMemory (for reporting)
DiskBlockManager¶
BlockManager creates a DiskBlockManager when created.

BlockManager uses the BlockManager for the following:
- Creating a DiskStore
- Registering an executor with a local external shuffle service (when initialized on an executor with externalShuffleServiceEnabled)
The DiskBlockManager is available as diskBlockManager reference to other Spark systems.
MigratableResolver¶
BlockManager creates a reference to a MigratableResolver by requesting the ShuffleManager for the ShuffleBlockResolver (that is assumed a MigratableResolver).
Lazy Value
migratableResolver is a Scala lazy value to guarantee that the code to initialize it is executed once only (when accessed for the first time) and the computed value never changes afterwards.
private[storage]
migratableResolver is a private[storage] so it is available to others in the org.apache.spark.storage package.
migratableResolver is used when:
BlockManageris requested to putBlockDataAsStreamShuffleMigrationRunnableis requested to runBlockManagerDecommissioneris requested to refreshOffloadingShuffleBlocksFallbackStorageis requested to copy
Local Directories for Block Storage¶
getLocalDiskDirs requests the DiskBlockManager for the local directories for block storage.
getLocalDiskDirs is part of the BlockDataManager abstraction.
getLocalDiskDirs is also used by BlockManager when requested for the following:
Initializing BlockManager¶
initialize requests the BlockTransferService to initialize.
initialize requests the ExternalBlockStoreClient to initialize (if given).
initialize determines the BlockReplicationPolicy based on spark.storage.replication.policy configuration property and prints out the following INFO message to the logs:
initialize creates a BlockManagerId and requests the BlockManagerMaster to registerBlockManager (with the BlockManagerId, the local directories of the DiskBlockManager, the maxOnHeapMemory, the maxOffHeapMemory and the slaveEndpoint).
initialize sets the internal BlockManagerId to be the response from the BlockManagerMaster (if available) or the BlockManagerId just created.
initialize initializes the External Shuffle Server's Address when enabled and prints out the following INFO message to the logs (with the externalShuffleServicePort):
(only for executors and External Shuffle Service enabled) initialize registers with the External Shuffle Server.
initialize determines the hostLocalDirManager. With spark.shuffle.readHostLocalDisk configuration property enabled and spark.shuffle.useOldFetchProtocol disabled, initialize uses the ExternalBlockStoreClient to create a HostLocalDirManager (with spark.storage.localDiskByExecutors.cacheSize configuration property).
In the end, initialize prints out the following INFO message to the logs (with the blockManagerId):
initialize is used when:
Registering Executor's BlockManager with External Shuffle Server¶
registerWithExternalShuffleServer registers the BlockManager (for an executor) with External Shuffle Service.
registerWithExternalShuffleServer prints out the following INFO message to the logs:
registerWithExternalShuffleServer creates an ExecutorShuffleInfo (with the localDirs and subDirsPerLocalDir of the DiskBlockManager, and the class name of the ShuffleManager).
registerWithExternalShuffleServer uses spark.shuffle.registration.maxAttempts configuration property and 5 sleep time when requesting the ExternalBlockStoreClient to registerWithShuffleServer (using the BlockManagerId and the ExecutorShuffleInfo).
In case of any exception that happen below the maximum number of attempts, registerWithExternalShuffleServer prints out the following ERROR message to the logs and sleeps 5 seconds:
Failed to connect to external shuffle server, will retry [attempts] more times after waiting 5 seconds...
BlockManagerId¶
BlockManager uses a BlockManagerId for...FIXME
HostLocalDirManager¶
BlockManager can use a HostLocalDirManager.
Default: (undefined)
BlockReplicationPolicy¶
BlockManager uses a BlockReplicationPolicy for...FIXME
External Shuffle Service's Port¶
BlockManager determines the port of an external shuffle service when created.
The port is used to create the shuffleServerId and a HostLocalDirManager.
The port is also used for preferExecutors.
spark.diskStore.subDirectories Configuration Property¶
BlockManager uses spark.diskStore.subDirectories configuration property to initialize a subDirsPerLocalDir local value.
subDirsPerLocalDir is used when:
IndexShuffleBlockResolveris requested to getDataFile and getIndexFileBlockManageris requested to readDiskBlockFromSameHostExecutor
Fetching Block or Computing (and Storing) it¶
getOrElseUpdate[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[T],
makeIterator: () => Iterator[T]): Either[BlockResult, Iterator[T]]
Map.getOrElseUpdate
I think it is fair to say that getOrElseUpdate is like getOrElseUpdate of scala.collection.mutable.Map in Scala.
Quoting the official scaladoc:
If given key
Kis already in this map,getOrElseUpdatereturns the associated valueV.Otherwise,
getOrElseUpdatecomputes a valueVfrom given expressionop, stores with the keyKin the map and returns that value.
Since BlockManager is a key-value store of blocks of data identified by a block ID that seems to fit so well.
getOrElseUpdate first attempts to get the block by the BlockId (from the local block manager first and, if unavailable, requesting remote peers).
getOrElseUpdate gives the BlockResult of the block if found.
If however the block was not found (in any block manager in a Spark cluster), getOrElseUpdate doPutIterator (for the input BlockId, the makeIterator function and the StorageLevel).
getOrElseUpdate branches off per the result:
- For
None,getOrElseUpdategetLocalValues for theBlockIdand eventually returns theBlockResult(unless terminated by aSparkExceptiondue to some internal error) - For
Some(iter),getOrElseUpdatereturns an iterator ofTvalues
getOrElseUpdate is used when:
RDDis requested to get or compute an RDD partition (for anRDDBlockIdwith the RDD's id and partition index).
Fetching Block¶
get attempts to fetch the block (BlockId) from a local block manager first before requesting it from remote block managers. get returns a BlockResult or None (to denote "a block is not available").
Internally, get tries to fetch the block from the local BlockManager. If found, get prints out the following INFO message to the logs and returns a BlockResult.
If however the block was not found locally, get tries to fetch the block from remote BlockManagers. If fetched, get prints out the following INFO message to the logs and returns a BlockResult.
getRemoteValues¶
getRemoteValues getRemoteBlock with the bufferTransformer function that takes a ManagedBuffer and does the following:
- Requests the SerializerManager to deserialize values from an input stream from the
ManagedBuffer - Creates a
BlockResultwith the values (and their total size, andNetworkread method)
Fetching Block Bytes From Remote Block Managers¶
getRemoteBytes getRemoteBlock with the bufferTransformer function that takes a ManagedBuffer and creates a ChunkedByteBuffer.
getRemoteBytes is used when:
TorrentBroadcastis requested to readBlocksTaskResultGetteris requested to enqueueSuccessfulTask
Fetching Remote Block¶
getRemoteBlock is used for getRemoteValues and getRemoteBytes.
getRemoteBlock prints out the following DEBUG message to the logs:
getRemoteBlock requests the BlockManagerMaster for locations and status of the input BlockId (with the host of BlockManagerId).
With some locations, getRemoteBlock determines the size of the block (max of diskSize and memSize). getRemoteBlock tries to read the block from the local directories of another executor on the same host. getRemoteBlock prints out the following INFO message to the logs:
When a data block could not be found in any of the local directories, getRemoteBlock fetchRemoteManagedBuffer.
For no locations from the BlockManagerMaster, getRemoteBlock prints out the following DEBUG message to the logs:
readDiskBlockFromSameHostExecutor¶
readDiskBlockFromSameHostExecutor(
blockId: BlockId,
localDirs: Array[String],
blockSize: Long): Option[ManagedBuffer]
readDiskBlockFromSameHostExecutor...FIXME
fetchRemoteManagedBuffer¶
fetchRemoteManagedBuffer(
blockId: BlockId,
blockSize: Long,
locationsAndStatus: BlockManagerMessages.BlockLocationsAndStatus): Option[ManagedBuffer]
fetchRemoteManagedBuffer...FIXME
sortLocations¶
sortLocations...FIXME
preferExecutors¶
preferExecutors...FIXME
readDiskBlockFromSameHostExecutor¶
readDiskBlockFromSameHostExecutor(
blockId: BlockId,
localDirs: Array[String],
blockSize: Long): Option[ManagedBuffer]
readDiskBlockFromSameHostExecutor...FIXME
ExecutionContextExecutorService¶
BlockManager uses a Scala ExecutionContextExecutorService to execute FIXME asynchronously (on a thread pool with block-manager-future prefix and maximum of 128 threads).
BlockEvictionHandler¶
BlockManager is a BlockEvictionHandler that can drop a block from memory (and store it on a disk when necessary).
ShuffleClient and External Shuffle Service¶
Danger
FIXME ShuffleClient and ExternalShuffleClient are dead. Long live BlockStoreClient and ExternalBlockStoreClient.
BlockManager manages the lifecycle of a ShuffleClient:
-
Creates when created
-
Inits (and possibly registers with an external shuffle server) when requested to initialize
-
Closes when requested to stop
The ShuffleClient can be an ExternalShuffleClient or the given BlockTransferService based on spark.shuffle.service.enabled configuration property. When enabled, BlockManager uses the ExternalShuffleClient.
The ShuffleClient is available to other Spark services (using shuffleClient value) and is used when BlockStoreShuffleReader is requested to read combined key-value records for a reduce task.
When requested for shuffle metrics, BlockManager simply requests them from the ShuffleClient.
BlockManager and RpcEnv¶
BlockManager is given a RpcEnv when created.
The RpcEnv is used to set up a BlockManagerSlaveEndpoint.
BlockInfoManager¶
BlockManager creates a BlockInfoManager when created.
BlockManager requests the BlockInfoManager to clear when requested to stop.
BlockManager uses the BlockInfoManager to create a MemoryStore.
BlockManager uses the BlockInfoManager when requested for the following:
-
removeRdd, removeBroadcast, removeBlock, removeBlockInternal
-
downgradeLock, releaseLock, registerTask, releaseAllLocksForTask
BlockManager and BlockManagerMaster¶
BlockManager is given a BlockManagerMaster when created.
BlockManager as BlockDataManager¶
BlockManager is a BlockDataManager.
BlockManager and MapOutputTracker¶
BlockManager is given a MapOutputTracker when created.
Executor ID¶
BlockManager is given an Executor ID when created.
The Executor ID is one of the following:
-
driver (
SparkContext.DRIVER_IDENTIFIER) for the driver -
Value of --executor-id command-line argument for CoarseGrainedExecutorBackend executors
BlockManagerEndpoint RPC Endpoint¶
BlockManager requests the RpcEnv to register a BlockManagerSlaveEndpoint under the name BlockManagerEndpoint[ID].
The RPC endpoint is used when BlockManager is requested to initialize and reregister (to register the BlockManager on an executor with the BlockManagerMaster on the driver).
The endpoint is stopped (by requesting the RpcEnv to stop the reference) when BlockManager is requested to stop.
Accessing BlockManager¶
BlockManager is available using SparkEnv on the driver and executors.
import org.apache.spark.SparkEnv
val bm = SparkEnv.get.blockManager
scala> :type bm
org.apache.spark.storage.BlockManager
BlockStoreClient¶
BlockManager uses a BlockStoreClient to read other executors' blocks. This is an ExternalBlockStoreClient (when given and an external shuffle service is used) or a BlockTransferService (to directly connect to other executors).
This BlockStoreClient is used when:
BlockStoreShuffleReaderis requested to read combined key-values for a reduce task- Create the HostLocalDirManager (when
BlockManageris initialized) - As the shuffleMetricsSource
- registerWithExternalShuffleServer (when an external shuffle server is used and the ExternalBlockStoreClient defined)
BlockTransferService¶
BlockManager is given a BlockTransferService when created.
Note
There is only one concrete BlockTransferService that is NettyBlockTransferService and there seem to be no way to reconfigure Apache Spark to use a different implementation (if there were any).
BlockTransferService is used when BlockManager is requested to fetch a block from and replicate a block to remote block managers.
BlockTransferService is used as the BlockStoreClient (unless an ExternalBlockStoreClient is specified).
BlockTransferService is initialized with this BlockManager.
BlockTransferService is closed when BlockManager is requested to stop.
ShuffleManager¶
BlockManager is given a ShuffleManager when created.
BlockManager uses the ShuffleManager for the following:
-
Retrieving a block data (for shuffle blocks)
-
Retrieving a non-shuffle block data (for shuffle blocks anyway)
-
Registering an executor with a local external shuffle service (when initialized on an executor with externalShuffleServiceEnabled)
MemoryStore¶
BlockManager creates a MemoryStore when created (with the BlockInfoManager, the SerializerManager, the MemoryManager and itself as a BlockEvictionHandler).
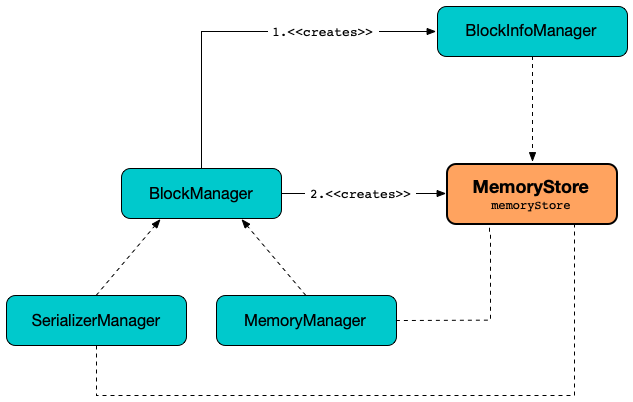
BlockManager requests the MemoryManager to use the MemoryStore.
BlockManager uses the MemoryStore for the following:
The MemoryStore is requested to clear when BlockManager is requested to stop.
The MemoryStore is available as memoryStore private reference to other Spark services.
The MemoryStore is used (via SparkEnv.get.blockManager.memoryStore reference) when Task is requested to run (that has just finished execution and requests the MemoryStore to release unroll memory).
DiskStore¶
BlockManager creates a DiskStore (with the DiskBlockManager) when created.
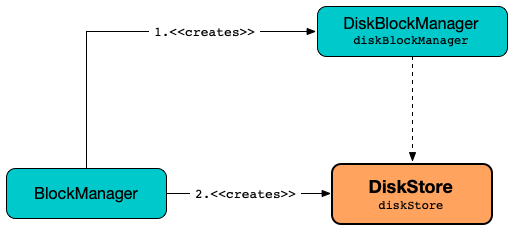
BlockManager uses the DiskStore when requested for the following:
- getStatus
- getCurrentBlockStatus
- getLocalValues
- doGetLocalBytes
- doPutIterator
- dropFromMemory
- removeBlockInternal
DiskStore is used when:
ByteBufferBlockStoreUpdateris requested to saveToDiskStoreTempFileBasedBlockStoreUpdateris requested to blockData and saveToDiskStore
Performance Metrics¶
BlockManager uses BlockManagerSource to report metrics under the name BlockManager.
getPeers¶
getPeers...FIXME
getPeers is used when BlockManager is requested to replicateBlock and replicate.
Releasing All Locks For Task¶
releaseAllLocksForTask...FIXME
releaseAllLocksForTask is used when TaskRunner is requested to run (at the end of a task).
Stopping BlockManager¶
stop...FIXME
stop is used when SparkEnv is requested to stop.
Getting IDs of Existing Blocks (For a Given Filter)¶
getMatchingBlockIds...FIXME
getMatchingBlockIds is used when BlockManagerSlaveEndpoint is requested to handle a GetMatchingBlockIds message.
Getting Local Block¶
getLocalValues prints out the following DEBUG message to the logs:
getLocalValues obtains a read lock for blockId.
When no blockId block was found, you should see the following DEBUG message in the logs and getLocalValues returns "nothing" (i.e. NONE).
When the blockId block was found, you should see the following DEBUG message in the logs:
If blockId block has memory level and is registered in MemoryStore, getLocalValues returns a BlockResult as Memory read method and with a CompletionIterator for an interator:
- Values iterator from
MemoryStoreforblockIdfor "deserialized" persistence levels. - Iterator from
SerializerManagerafter the data stream has been deserialized for theblockIdblock and the bytes forblockIdblock for "serialized" persistence levels.
getLocalValues is used when:
-
TorrentBroadcastis requested to readBroadcastBlock -
BlockManageris requested to get and getOrElseUpdate
maybeCacheDiskValuesInMemory¶
maybeCacheDiskValuesInMemory[T](
blockInfo: BlockInfo,
blockId: BlockId,
level: StorageLevel,
diskIterator: Iterator[T]): Iterator[T]
maybeCacheDiskValuesInMemory...FIXME
Retrieving Block Data¶
getBlockData is part of the BlockDataManager abstraction.
For a BlockId.md[] of a shuffle (a ShuffleBlockId), getBlockData requests the <
Otherwise, getBlockData <
If found, getBlockData creates a new BlockManagerManagedBuffer (with the <
If not found, getBlockData <
NOTE: getBlockData is executed for shuffle blocks or local blocks that the BlockManagerMaster knows this executor really has (unless BlockManagerMaster is outdated).
Retrieving Non-Shuffle Local Block Data¶
getLocalBytes...FIXME
getLocalBytes is used when:
TorrentBroadcastis requested to readBlocksBlockManageris requested for the block data (of a non-shuffle block)
Storing Block Data Locally¶
putBlockData(
blockId: BlockId,
data: ManagedBuffer,
level: StorageLevel,
classTag: ClassTag[_]): Boolean
putBlockData is part of the BlockDataManager abstraction.
putBlockData putBytes with Java NIO's ByteBuffer of the given ManagedBuffer.
Storing Block (ByteBuffer) Locally¶
putBytes(
blockId: BlockId,
bytes: ChunkedByteBuffer,
level: StorageLevel,
tellMaster: Boolean = true): Boolean
putBytes creates a ByteBufferBlockStoreUpdater that is then requested to store the bytes.
putBytes is used when:
BlockManageris requested to puts a block data locallyTaskRunneris requested to run (and the result size is above maxDirectResultSize)TorrentBroadcastis requested to writeBlocks and readBlocks
doPutBytes¶
doPutBytes[T](
blockId: BlockId,
bytes: ChunkedByteBuffer,
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Boolean
doPutBytes calls the internal helper <BlockInfo and does the uploading.
Inside the function, if the StorageLevel.md[storage level]'s replication is greater than 1, it immediately starts <blockId block on a separate thread (from futureExecutionContext thread pool). The replication uses the input bytes and level storage level.
For a memory storage level, the function checks whether the storage level is deserialized or not. For a deserialized storage level, BlockManager's serializer:SerializerManager.md#dataDeserializeStream[SerializerManager deserializes bytes into an iterator of values] that MemoryStore.md#putIteratorAsValues[MemoryStore stores]. If however the storage level is not deserialized, the function requests MemoryStore.md#putBytes[MemoryStore to store the bytes]
If the put did not succeed and the storage level is to use disk, you should see the following WARN message in the logs:
And DiskStore.md#putBytes[DiskStore stores the bytes].
NOTE: DiskStore.md[DiskStore] is requested to store the bytes of a block with memory and disk storage level only when MemoryStore.md[MemoryStore] has failed.
If the storage level is to use disk only, DiskStore.md#putBytes[DiskStore stores the bytes].
doPutBytes requests <tellMaster), the function <TaskContext metrics are updated with the updated block status] (only when executed inside a task where TaskContext is available).
You should see the following DEBUG message in the logs:
The function waits till the earlier asynchronous replication finishes for a block with replication level greater than 1.
The final result of doPutBytes is the result of storing the block successful or not (as computed earlier).
NOTE: doPutBytes is used exclusively when BlockManager is requested to <
Putting New Block¶
doPut[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[_],
tellMaster: Boolean,
keepReadLock: Boolean)(putBody: BlockInfo => Option[T]): Option[T]
doPut requires that the given StorageLevel is valid.
doPut creates a new BlockInfo and requests the BlockInfoManager for a write lock for the block.
doPut executes the given putBody function (with the BlockInfo).
If the result of putBody function is None, the block is considered saved successfully.
For successful save, doPut requests the BlockInfoManager to downgradeLock or unlock based on the given keepReadLock flag (true and false, respectively).
For unsuccessful save (when putBody returned some value), doPut removeBlockInternal and prints out the following WARN message to the logs:
In the end, doPut prints out the following DEBUG message to the logs:
doPut is used when:
BlockStoreUpdateris requested to saveBlockManageris requested to doPutIterator
Removing Block¶
removeBlock prints out the following DEBUG message to the logs:
removeBlock requests the BlockInfoManager for write lock on the block.
With a write lock on the block, removeBlock removeBlockInternal (with the tellMaster flag turned on when the input tellMaster flag and the tellMaster of the block itself are both turned on).
In the end, removeBlock addUpdatedBlockStatusToTaskMetrics (with an empty BlockStatus).
In case the block is no longer available (None), removeBlock prints out the following WARN message to the logs:
removeBlock is used when:
BlockManageris requested to handleLocalReadFailure, removeRdd, removeBroadcastBlockManagerDecommissioneris requested to migrate a blockBlockManagerStorageEndpointis requested to handle a RemoveBlock message
Removing RDD Blocks¶
removeRdd removes all the blocks that belong to the rddId RDD.
It prints out the following INFO message to the logs:
It then requests RDD blocks from BlockInfoManager.md[] and <
The number of blocks removed is the final result.
NOTE: It is used by BlockManagerSlaveEndpoint.md#RemoveRdd[BlockManagerSlaveEndpoint while handling RemoveRdd messages].
Removing All Blocks of Broadcast Variable¶
removeBroadcast removes all the blocks of the input broadcastId broadcast.
Internally, it starts by printing out the following DEBUG message to the logs:
It then requests all the BlockId.md#BroadcastBlockId[BroadcastBlockId] objects that belong to the broadcastId broadcast from BlockInfoManager.md[] and <
The number of blocks removed is the final result.
NOTE: It is used by BlockManagerSlaveEndpoint.md#RemoveBroadcast[BlockManagerSlaveEndpoint while handling RemoveBroadcast messages].
External Shuffle Server's Address¶
When requested to initialize, BlockManager records the location (BlockManagerId) of External Shuffle Service if enabled or simply uses the non-external-shuffle-service BlockManagerId.
The BlockManagerId is used to register an executor with a local external shuffle service.
The BlockManagerId is used as the location of a shuffle map output when:
BypassMergeSortShuffleWriteris requested to write partition records to a shuffle fileUnsafeShuffleWriteris requested to close and write outputSortShuffleWriteris requested to write output
getStatus¶
getStatus...FIXME
getStatus is used when BlockManagerSlaveEndpoint is requested to handle GetBlockStatus message.
Re-registering BlockManager with Driver¶
reregister prints out the following INFO message to the logs:
reregister requests the BlockManagerMaster to register this BlockManager.
In the end, reregister reportAllBlocks.
reregister is used when:
Executoris requested to reportHeartBeat (and informed to re-register)BlockManageris requested to asyncReregister
Reporting All Blocks¶
reportAllBlocks prints out the following INFO message to the logs:
For all the blocks in the BlockInfoManager, reportAllBlocks getCurrentBlockStatus and tryToReportBlockStatus (for blocks tracked by the master).
reportAllBlocks prints out the following ERROR message to the logs and exits when block status reporting fails for any block:
Calculate Current Block Status¶
getCurrentBlockStatus gives the current BlockStatus of the BlockId block (with the block's current StorageLevel.md[StorageLevel], memory and disk sizes). It uses MemoryStore.md[MemoryStore] and DiskStore.md[DiskStore] for size and other information.
NOTE: Most of the information to build BlockStatus is already in BlockInfo except that it may not necessarily reflect the current state per MemoryStore.md[MemoryStore] and DiskStore.md[DiskStore].
Internally, it uses the input BlockInfo.md[] to know about the block's storage level. If the storage level is not set (i.e. null), the returned BlockStatus assumes the StorageLevel.md[default NONE storage level] and the memory and disk sizes being 0.
If however the storage level is set, getCurrentBlockStatus uses MemoryStore.md[MemoryStore] and DiskStore.md[DiskStore] to check whether the block is stored in the storages or not and request for their sizes in the storages respectively (using their getSize or assume 0).
NOTE: It is acceptable that the BlockInfo says to use memory or disk yet the block is not in the storages (yet or anymore). The method will give current status.
getCurrentBlockStatus is used when <
Reporting Current Storage Status of Block to Driver¶
reportBlockStatus tryToReportBlockStatus.
If told to re-register, reportBlockStatus prints out the following INFO message to the logs followed by asynchronous re-registration:
In the end, reportBlockStatus prints out the following DEBUG message to the logs:
reportBlockStatus is used when:
IndexShuffleBlockResolveris requested toBlockStoreUpdateris requested to saveBlockManageris requested to getLocalBlockData, doPutIterator, dropFromMemory, removeBlockInternal
Reporting Block Status Update to Driver¶
tryToReportBlockStatus(
blockId: BlockId,
status: BlockStatus,
droppedMemorySize: Long = 0L): Boolean
tryToReportBlockStatus reports block status update to the BlockManagerMaster and returns its response.
tryToReportBlockStatus is used when:
BlockManageris requested to reportAllBlocks, reportBlockStatus
Execution Context¶
block-manager-future is the execution context for...FIXME
ByteBuffer¶
The underlying abstraction for blocks in Spark is a ByteBuffer that limits the size of a block to 2GB (Integer.MAX_VALUE - see Why does FileChannel.map take up to Integer.MAX_VALUE of data? and SPARK-1476 2GB limit in spark for blocks). This has implication not just for managed blocks in use, but also for shuffle blocks (memory mapped blocks are limited to 2GB, even though the API allows for long), ser-deser via byte array-backed output streams.
BlockResult¶
BlockResult is a metadata of a fetched block:
- Data (
Iterator[Any]) - DataReadMethod
- Size (bytes)
BlockResult is created and returned when BlockManager is requested for the following:
DataReadMethod¶
DataReadMethod describes how block data was read.
| DataReadMethod | Source |
|---|---|
Disk | DiskStore (while getLocalValues) |
Hadoop | seems unused |
Memory | MemoryStore (while getLocalValues) |
Network | Remote BlockManagers (aka network) |
Registering Task¶
registerTask requests the BlockInfoManager to register a given task.
registerTask is used when Task is requested to run (at the start of a task).
Creating DiskBlockObjectWriter¶
getDiskWriter(
blockId: BlockId,
file: File,
serializerInstance: SerializerInstance,
bufferSize: Int,
writeMetrics: ShuffleWriteMetrics): DiskBlockObjectWriter
getDiskWriter creates a DiskBlockObjectWriter (with spark.shuffle.sync configuration property for syncWrites argument).
getDiskWriter uses the SerializerManager.
getDiskWriter is used when:
-
BypassMergeSortShuffleWriteris requested to write records (of a partition) -
ShuffleExternalSorteris requested to writeSortedFile -
ExternalAppendOnlyMapis requested to spillMemoryIteratorToDisk -
ExternalSorteris requested to spillMemoryIteratorToDisk and writePartitionedFile -
UnsafeSorterSpillWriter is created
Recording Updated BlockStatus in TaskMetrics (of Current Task)¶
addUpdatedBlockStatusToTaskMetrics takes an active TaskContext (if available) and records updated BlockStatus for Block (in the task's TaskMetrics).
addUpdatedBlockStatusToTaskMetrics is used when BlockManager doPutBytes (for a block that was successfully stored), doPut, doPutIterator, removes blocks from memory (possibly spilling it to disk) and removes block from memory and disk.
Shuffle Metrics Source¶
shuffleMetricsSource creates a ShuffleMetricsSource with the shuffleMetrics (of the BlockStoreClient) and the source name as follows:
- ExternalShuffle when ExternalBlockStoreClient is specified
- NettyBlockTransfer otherwise
shuffleMetricsSource is available using SparkEnv:
shuffleMetricsSource is used when:
- Executor is created (for non-local / cluster modes)
Replicating Block To Peers¶
replicate(
blockId: BlockId,
data: BlockData,
level: StorageLevel,
classTag: ClassTag[_],
existingReplicas: Set[BlockManagerId] = Set.empty): Unit
replicate...FIXME
replicate is used when BlockManager is requested to doPutBytes, doPutIterator and replicateBlock.
replicateBlock¶
replicateBlock...FIXME
replicateBlock is used when BlockManagerSlaveEndpoint is requested to handle a ReplicateBlock message.
putIterator¶
putIterator[T: ClassTag](
blockId: BlockId,
values: Iterator[T],
level: StorageLevel,
tellMaster: Boolean = true): Boolean
putIterator...FIXME
putIterator is used when:
BlockManageris requested to putSingle
putSingle¶
putSingle[T: ClassTag](
blockId: BlockId,
value: T,
level: StorageLevel,
tellMaster: Boolean = true): Boolean
putSingle...FIXME
putSingle is used when TorrentBroadcast is requested to write the blocks and readBroadcastBlock.
doPutIterator¶
doPutIterator[T](
blockId: BlockId,
iterator: () => Iterator[T],
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Option[PartiallyUnrolledIterator[T]]
doPutIterator doPut with the putBody function.
doPutIterator is used when:
BlockManageris requested to getOrElseUpdate and putIterator
putBody¶
For the given StorageLevel that indicates to use memory for storage, putBody requests the MemoryStore to putIteratorAsValues or putIteratorAsBytes based on the StorageLevel (that indicates to use deserialized format or not, respectively).
In case storing the block in memory was not possible (due to lack of available memory), putBody prints out the following WARN message to the logs and falls back on the DiskStore to store the block.
For the given StorageLevel that indicates to use disk storage only (useMemory flag is disabled), putBody requests the DiskStore to store the block.
putBody gets the current block status and checks whether the StorageLevel is valid (that indicates that the block was stored successfully).
If the block was stored successfully, putBody reports the block status (only if indicated by the the given tellMaster flag and the tellMaster flag of the associated BlockInfo) and addUpdatedBlockStatusToTaskMetrics.
putBody prints out the following DEBUG message to the logs:
For the given StorageLevel with replication enabled (above 1), putBody doGetLocalBytes and replicates the block (to other BlockManagers). putBody prints out the following DEBUG message to the logs:
doGetLocalBytes¶
doGetLocalBytes...FIXME
doGetLocalBytes is used when:
BlockManageris requested to getLocalBytes, doPutIterator and replicateBlock
Dropping Block from Memory¶
dropFromMemory prints out the following INFO message to the logs:
dropFromMemory requests the BlockInfoManager to assert that the block is locked for writing (that gives a BlockInfo or throws a SparkException).
dropFromMemory drops to disk if the current storage level requires so (based on the given BlockInfo) and the block is not in the DiskStore already. dropFromMemory prints out the following INFO message to the logs:
dropFromMemory uses the given data to determine whether the DiskStore is requested to put or putBytes (Array[T] or ChunkedByteBuffer, respectively).
dropFromMemory requests the MemoryStore to remove the block. dropFromMemory prints out the following WARN message to the logs if the block was not found in the MemoryStore:
dropFromMemory gets the current block status and reportBlockStatus when requested (when the tellMaster flag of the BlockInfo is turned on).
dropFromMemory addUpdatedBlockStatusToTaskMetrics when the block has been updated (dropped to disk or removed from the MemoryStore).
In the end, dropFromMemory returns the current StorageLevel of the block (off the BlockStatus).
dropFromMemory is part of the BlockEvictionHandler abstraction.
releaseLock Method¶
releaseLock requests the BlockInfoManager to unlock the given block.
releaseLock is part of the BlockDataManager abstraction.
putBlockDataAsStream¶
putBlockDataAsStream(
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[_]): StreamCallbackWithID
putBlockDataAsStream is part of the BlockDataManager abstraction.
putBlockDataAsStream...FIXME
Maximum Memory¶
Total maximum value that BlockManager can ever possibly use (that depends on MemoryManager and may vary over time).
Total available on-heap and off-heap memory for storage (in bytes)
Maximum Off-Heap Memory¶
Maximum On-Heap Memory¶
decommissionSelf¶
decommissionSelf...FIXME
decommissionSelf is used when:
BlockManagerStorageEndpointis requested to handle a DecommissionBlockManager message
decommissionBlockManager¶
decommissionBlockManager sends a DecommissionBlockManager message to the BlockManagerStorageEndpoint.
decommissionBlockManager is used when:
CoarseGrainedExecutorBackendis requested to decommissionSelf
BlockManagerStorageEndpoint¶
BlockManager sets up a RpcEndpointRef (within the RpcEnv) under the name BlockManagerEndpoint[ID] with a BlockManagerStorageEndpoint message handler.
BlockManagerDecommissioner¶
BlockManager defines decommissioner internal registry for a BlockManagerDecommissioner.
decommissioner is undefined (None) by default.
BlockManager creates and starts a BlockManagerDecommissioner when requested to decommissionSelf.
decommissioner is used for isDecommissioning and lastMigrationInfo.
BlockManager requests the BlockManagerDecommissioner to stop when stopped.
Removing Block from Memory and Disk¶
For tellMaster turned on, removeBlockInternal requests the BlockInfoManager to assert that the block is locked for writing and remembers the current block status. Otherwise, removeBlockInternal leaves the block status undetermined.
removeBlockInternal requests the MemoryStore to remove the block.
removeBlockInternal requests the DiskStore to remove the block.
removeBlockInternal requests the BlockInfoManager to remove the block metadata.
In the end, removeBlockInternal reports the block status (to the master) with the storage level changed to NONE.
removeBlockInternal prints out the following WARN message when the block was not stored in the MemoryStore and the DiskStore:
removeBlockInternal is used when:
BlockManageris requested to put a new block and remove a block
maybeCacheDiskBytesInMemory¶
maybeCacheDiskBytesInMemory(
blockInfo: BlockInfo,
blockId: BlockId,
level: StorageLevel,
diskData: BlockData): Option[ChunkedByteBuffer]
maybeCacheDiskBytesInMemory...FIXME
maybeCacheDiskBytesInMemory is used when:
BlockManageris requested to getLocalValues and doGetLocalBytes
Logging¶
Enable ALL logging level for org.apache.spark.storage.BlockManager logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.