IndexShuffleBlockResolver¶
IndexShuffleBlockResolver is a ShuffleBlockResolver that manages shuffle block data and uses shuffle index files for faster shuffle data access.
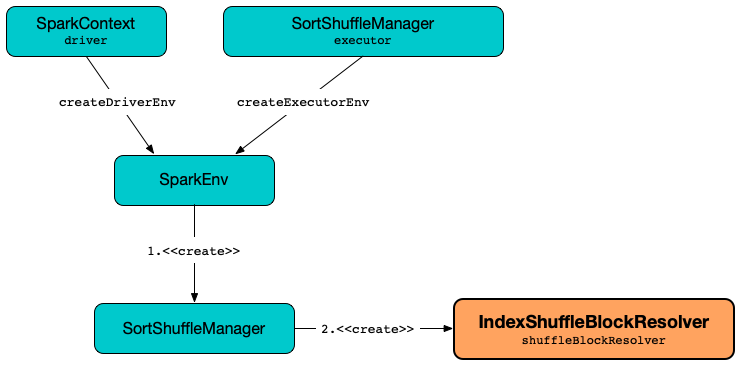
Creating Instance¶
IndexShuffleBlockResolver takes the following to be created:
IndexShuffleBlockResolver is created when:
SortShuffleManageris createdLocalDiskShuffleExecutorComponentsis requested to initializeExecutor
getStoredShuffles¶
getStoredShuffles is part of the MigratableResolver abstraction.
getStoredShuffles...FIXME
putShuffleBlockAsStream¶
putShuffleBlockAsStream(
blockId: BlockId,
serializerManager: SerializerManager): StreamCallbackWithID
putShuffleBlockAsStream is part of the MigratableResolver abstraction.
putShuffleBlockAsStream...FIXME
getMigrationBlocks¶
getMigrationBlocks is part of the MigratableResolver abstraction.
getMigrationBlocks...FIXME
Writing Shuffle Index and Data Files¶
writeIndexFileAndCommit finds the index and data files for the input shuffleId and mapId.
writeIndexFileAndCommit creates a temporary file for the index file (in the same directory) and writes offsets (as the moving sum of the input lengths starting from 0 to the final offset at the end for the end of the output file).
Note
The offsets are the sizes in the input lengths exactly.
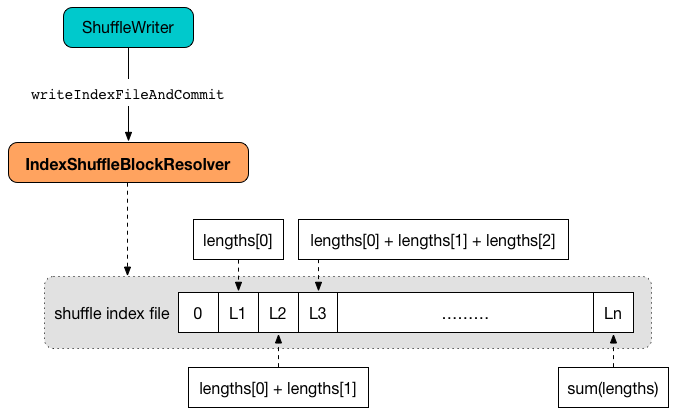
writeIndexFileAndCommit...FIXME (Review me)
writeIndexFileAndCommit <shuffleId and mapId.
writeIndexFileAndCommit <
If the consistency check fails, it means that another attempt for the same task has already written the map outputs successfully and so the input dataTmp and temporary index files are deleted (as no longer correct).
If the consistency check succeeds, the existing index and data files are deleted (if they exist) and the temporary index and data files become "official", i.e. renamed to their final names.
In case of any IO-related exception, writeIndexFileAndCommit throws a IOException with the messages:
or
writeIndexFileAndCommit is used when:
LocalDiskShuffleMapOutputWriteris requested to commitAllPartitionsLocalDiskSingleSpillMapOutputWriteris requested to transferMapSpillFile
Removing Shuffle Index and Data Files¶
removeDataByMap finds and deletes the shuffle data file (for the input shuffleId and mapId) followed by finding and deleting the shuffle data index file.
removeDataByMap is used when:
SortShuffleManageris requested to unregister a shuffle (and remove a shuffle from a shuffle system)
Creating Shuffle Block Index File¶
getIndexFile creates a ShuffleIndexBlockId.
With dirs local directories defined, getIndexFile places the index file of the ShuffleIndexBlockId (by the name) in the local directories (with the spark.diskStore.subDirectories).
Otherwise, with no local directories, getIndexFile requests the DiskBlockManager (of the BlockManager) to get the data file.
getIndexFile is used when:
IndexShuffleBlockResolveris requested to getBlockData, removeDataByMap, putShuffleBlockAsStream, getMigrationBlocks, writeIndexFileAndCommitFallbackStorageis requested to copy
Creating Shuffle Block Data File¶
getDataFile(
shuffleId: Int,
mapId: Long): File // (1)
getDataFile(
shuffleId: Int,
mapId: Long,
dirs: Option[Array[String]]): File
dirsisNone(undefined)
getDataFile creates a ShuffleDataBlockId.
With dirs local directories defined, getDataFile places the data file of the ShuffleDataBlockId (by the name) in the local directories (with the spark.diskStore.subDirectories).
Otherwise, with no local directories, getDataFile requests the DiskBlockManager (of the BlockManager) to get the data file.
getDataFile is used when:
IndexShuffleBlockResolveris requested to getBlockData, removeDataByMap, putShuffleBlockAsStream, getMigrationBlocks, writeIndexFileAndCommitLocalDiskShuffleMapOutputWriteris createdLocalDiskSingleSpillMapOutputWriteris requested to transferMapSpillFileFallbackStorageis requested to copy
Creating ManagedBuffer to Read Shuffle Block Data File¶
getBlockData is part of the ShuffleBlockResolver abstraction.
getBlockData...FIXME
Checking Consistency of Shuffle Index and Data Files¶
Danger
Review Me
checkIndexAndDataFile first checks if the size of the input index file is exactly the input blocks multiplied by 8.
checkIndexAndDataFile returns null when the numbers, and hence the shuffle index and data files, don't match.
checkIndexAndDataFile reads the shuffle index file and converts the offsets into lengths of each block.
checkIndexAndDataFile makes sure that the size of the input shuffle data file is exactly the sum of the block lengths.
checkIndexAndDataFile returns the block lengths if the numbers match, and null otherwise.
TransportConf¶
IndexShuffleBlockResolver creates a TransportConf (for shuffle module) when created.
transportConf is used in getMigrationBlocks and getBlockData.
Logging¶
Enable ALL logging level for org.apache.spark.shuffle.IndexShuffleBlockResolver logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.