BypassMergeSortShuffleWriter¶
BypassMergeSortShuffleWriter<K, V> is a ShuffleWriter for ShuffleMapTasks to write records into one single shuffle block data file.
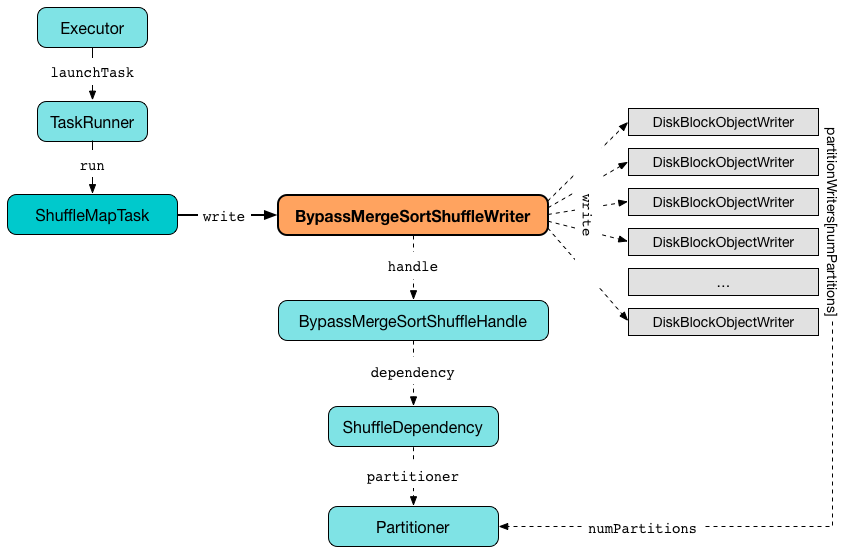
Creating Instance¶
BypassMergeSortShuffleWriter takes the following to be created:
- BlockManager
- BypassMergeSortShuffleHandle (of
Kkeys andVvalues) - Map ID
- SparkConf
- ShuffleWriteMetricsReporter
-
ShuffleExecutorComponents
BypassMergeSortShuffleWriter is created when:
SortShuffleManageris requested for a ShuffleWriter (for a BypassMergeSortShuffleHandle)
DiskBlockObjectWriters¶
BypassMergeSortShuffleWriter uses a DiskBlockObjectWriter per partition (based on the Partitioner).
BypassMergeSortShuffleWriter asserts that no partitionWriters are created while writing out records to a shuffle file.
While writing, BypassMergeSortShuffleWriter requests the BlockManager for as many DiskBlockObjectWriters as there are partitions (in the Partitioner).
While writing, BypassMergeSortShuffleWriter requests the Partitioner for a partition for records (using keys) and finds the per-partition DiskBlockObjectWriter that is requested to write out the partition records. After all records are written out to their shuffle files, the DiskBlockObjectWriters are requested to commitAndGet.
BypassMergeSortShuffleWriter uses the partition writers while writing out partition data and removes references to them (nullify them) in the end.
In other words, after writing out partition data partitionWriters internal registry is null.
partitionWriters internal registry becomes null after BypassMergeSortShuffleWriter has finished:
IndexShuffleBlockResolver¶
BypassMergeSortShuffleWriter is given a IndexShuffleBlockResolver when created.
BypassMergeSortShuffleWriter uses the IndexShuffleBlockResolver for writing out records (to writeIndexFileAndCommit and getDataFile).
Serializer¶
When created, BypassMergeSortShuffleWriter requests the ShuffleDependency (of the given BypassMergeSortShuffleHandle) for the Serializer.
BypassMergeSortShuffleWriter creates a new instance of the Serializer for writing out records.
Configuration Properties¶
spark.shuffle.file.buffer¶
BypassMergeSortShuffleWriter uses spark.shuffle.file.buffer configuration property for...FIXME
spark.file.transferTo¶
BypassMergeSortShuffleWriter uses spark.file.transferTo configuration property to control whether to use Java New I/O while writing to a partitioned file.
Writing Out Records to Shuffle File¶
write is part of the ShuffleWriter abstraction.
write creates a new instance of the Serializer.
write initializes the partitionWriters and partitionWriterSegments internal registries (for DiskBlockObjectWriters and FileSegments for every partition, respectively).
write requests the BlockManager for the DiskBlockManager and for every partition write requests it for a shuffle block ID and the file. write creates a DiskBlockObjectWriter for the shuffle block (using the BlockManager). write stores the reference to DiskBlockObjectWriters in the partitionWriters internal registry.
After all DiskBlockObjectWriters are created, write requests the ShuffleWriteMetrics to increment shuffle write time metric.
For every record (a key-value pair), write requests the Partitioner for the partition ID for the key. The partition ID is then used as an index of the partition writer (among the DiskBlockObjectWriters) to write the current record out to a block file.
Once all records have been writted out to their respective block files, write does the following for every DiskBlockObjectWriter:
-
Requests the
DiskBlockObjectWriterto commit and return a corresponding FileSegment of the shuffle block -
Saves the (reference to)
FileSegmentsin the partitionWriterSegments internal registry -
Requests the
DiskBlockObjectWriterto close
Note
At this point, all the records are in shuffle block files on a local disk. The records are split across block files by key.
write requests the IndexShuffleBlockResolver for the shuffle file for the shuffle and the mapDs>>.
write creates a temporary file (based on the name of the shuffle file) and writes all the per-partition shuffle files to it. The size of every per-partition shuffle files is saved as the partitionLengths internal registry.
Note
At this point, all the per-partition shuffle block files are one single map shuffle data file.
write requests the IndexShuffleBlockResolver to write shuffle index and data files for the shuffle and the map IDs (with the partitionLengths and the temporary shuffle output file).
write returns a shuffle map output status (with the shuffle server ID and the partitionLengths).
No Records¶
When there is no records to write out, write initializes the partitionLengths internal array (of numPartitions size) with all elements being 0.
write requests the IndexShuffleBlockResolver to write shuffle index and data files, but the difference (compared to when there are records to write) is that the dataTmp argument is simply null.
write sets the internal mapStatus (with the address of BlockManager in use and partitionLengths).
Requirements¶
write requires that there are no DiskBlockObjectWriters.
Writing Out Partitioned Data¶
writePartitionedData makes sure that DiskBlockObjectWriters are available (partitionWriters != null).
For every partition, writePartitionedData takes the partition file (from the FileSegments). Only when the partition file exists, writePartitionedData requests the given ShuffleMapOutputWriter for a ShufflePartitionWriter and writes out the partitioned data. At the end, writePartitionedData deletes the file.
writePartitionedData requests the ShuffleWriteMetricsReporter to increment the write time.
In the end, writePartitionedData requests the ShuffleMapOutputWriter to commitAllPartitions and returns the size of each partition of the output map file.
Copying Raw Bytes Between Input Streams¶
copyStream(
in: InputStream,
out: OutputStream,
closeStreams: Boolean = false,
transferToEnabled: Boolean = false): Long
copyStream branches off depending on the type of in and out streams, i.e. whether they are both FileInputStream with transferToEnabled input flag is enabled.
If they are both FileInputStream with transferToEnabled enabled, copyStream gets their FileChannels and transfers bytes from the input file to the output file and counts the number of bytes, possibly zero, that were actually transferred.
NOTE: copyStream uses Java's {java-javadoc-url}/java/nio/channels/FileChannel.html[java.nio.channels.FileChannel] to manage file channels.
If either in and out input streams are not FileInputStream or transferToEnabled flag is disabled (default), copyStream reads data from in to write to out and counts the number of bytes written.
copyStream can optionally close in and out streams (depending on the input closeStreams -- disabled by default).
NOTE: Utils.copyStream is used when <
Tip
Visit the official web site of JSR 51: New I/O APIs for the Java Platform and read up on java.nio package.
Stopping ShuffleWriter¶
stop...FIXME
stop is part of the ShuffleWriter abstraction.
Temporary Array of Partition Lengths¶
Temporary array of partition lengths after records are written to a shuffle system.
Initialized every time BypassMergeSortShuffleWriter writes out records (before passing it in to IndexShuffleBlockResolver). After IndexShuffleBlockResolver finishes, it is used to initialize mapStatus internal property.
Logging¶
Enable ALL logging level for org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.
Internal Properties¶
numPartitions¶
partitionWriterSegments¶
mapStatus¶
MapStatus that BypassMergeSortShuffleWriter returns when stopped
Initialized every time BypassMergeSortShuffleWriter writes out records.
Used when BypassMergeSortShuffleWriter stops (with success enabled) as a marker if any records were written and returned if they did.