TaskSetManager¶
TaskSetManager is a Schedulable that manages scheduling the tasks of a TaskSet.
Creating Instance¶
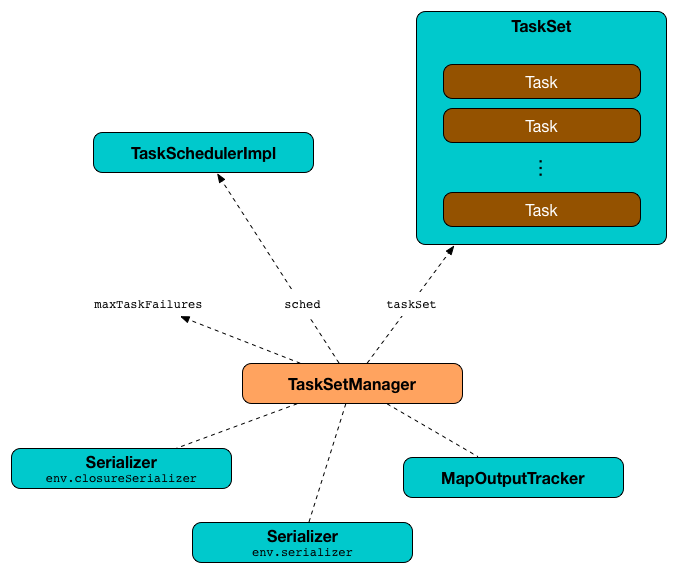
TaskSetManager takes the following to be created:
- TaskSchedulerImpl
- TaskSet
- Number of Task Failures
-
HealthTracker -
Clock
TaskSetManager is created when:
TaskSchedulerImplis requested to create a TaskSetManager
While being created, TaskSetManager requests the current epoch from MapOutputTracker and sets it on all tasks in the taskset.
Note
TaskSetManager uses TaskSchedulerImpl to access the current MapOutputTracker.
TaskSetManager prints out the following DEBUG to the logs:
TaskSetManager adds the tasks as pending execution (in reverse order from the highest partition to the lowest).
Number of Task Failures¶
TaskSetManager is given maxTaskFailures value that is how many times a single task can fail before the whole TaskSet is aborted.
| Master URL | Number of Task Failures |
|---|---|
local | 1 |
| local-with-retries | maxFailures |
local-cluster | spark.task.maxFailures |
| Cluster Manager | spark.task.maxFailures |
isBarrier¶
isBarrier is enabled (true) when this TaskSetManager is created for a TaskSet with barrier tasks.
isBarrier is used when:
TaskSchedulerImplis requested to resourceOfferSingleTaskSet, resourceOffersTaskSetManageris requested to resourceOffer, checkSpeculatableTasks, getLocalityWait
resourceOffer¶
resourceOffer(
execId: String,
host: String,
maxLocality: TaskLocality.TaskLocality,
taskCpus: Int = sched.CPUS_PER_TASK,
taskResourceAssignments: Map[String, ResourceInformation] = Map.empty): (Option[TaskDescription], Boolean, Int)
resourceOffer determines allowed locality level for the given TaskLocality being anything but NO_PREF.
resourceOffer dequeueTask for the given execId and host, and the allowed locality level. This may or may not give a TaskDescription.
In the end, resourceOffer returns the TaskDescription, hasScheduleDelayReject, and the index of the dequeued task (if any).
resourceOffer returns a (None, false, -1) tuple when this TaskSetManager is isZombie or the offer (by the given host or execId) should be ignored (excluded).
resourceOffer is used when:
TaskSchedulerImplis requested to resourceOfferSingleTaskSet
Locality Wait¶
getLocalityWait is 0 for legacyLocalityWaitReset and isBarrier flags enabled.
getLocalityWait determines the value of locality wait based on the given TaskLocality.TaskLocality.
| TaskLocality | Configuration Property |
|---|---|
PROCESS_LOCAL | spark.locality.wait.process |
NODE_LOCAL | spark.locality.wait.node |
RACK_LOCAL | spark.locality.wait.rack |
Unless the value has been determined, getLocalityWait defaults to 0.
Note
NO_PREF and ANY task localities have no locality wait.
getLocalityWait is used when:
TaskSetManageris created and recomputes locality preferences
spark.driver.maxResultSize¶
TaskSetManager uses spark.driver.maxResultSize configuration property to check available memory for more task results.
Recomputing Task Locality Preferences¶
If zombie, recomputeLocality does nothing.
recomputeLocality recomputes myLocalityLevels, localityWaits and currentLocalityIndex internal registries.
recomputeLocality computes locality levels (for scheduled tasks) and saves the result in myLocalityLevels internal registry.
recomputeLocality computes localityWaits by determining the locality wait for every locality level in myLocalityLevels.
recomputeLocality computes currentLocalityIndex by getLocalityIndex with the previous locality level. If the current locality index is higher than the previous, recomputeLocality recalculates currentLocalityIndex.
recomputeLocality is used when:
TaskSetManageris notified about status change in executors (i.e., lost, decommissioned, added)
Zombie¶
A TaskSetManager is a zombie when all tasks in a taskset have completed successfully (regardless of the number of task attempts), or if the taskset has been aborted.
While in zombie state, a TaskSetManager can launch no new tasks and responds with no TaskDescriptions to resourceOffers.
A TaskSetManager remains in the zombie state until all tasks have finished running, i.e. to continue to track and account for the running tasks.
Computing Locality Levels (for Scheduled Tasks)¶
computeValidLocalityLevels computes valid locality levels for tasks that were registered in corresponding registries per locality level.
Note
TaskLocality is a locality preference of a task and can be the most localized PROCESS_LOCAL, NODE_LOCAL through NO_PREF and RACK_LOCAL to ANY.
For every pending task (in pendingTasks registry), computeValidLocalityLevels requests the TaskSchedulerImpl for acceptable TaskLocalityies:
- For every executor,
computeValidLocalityLevelsrequests the TaskSchedulerImpl to isExecutorAlive and addsPROCESS_LOCAL - For every host,
computeValidLocalityLevelsrequests the TaskSchedulerImpl to hasExecutorsAliveOnHost and addsNODE_LOCAL - For any pending tasks with no locality preference,
computeValidLocalityLevelsaddsNO_PREF - For every rack,
computeValidLocalityLevelsrequests the TaskSchedulerImpl to hasHostAliveOnRack and addsRACK_LOCAL
computeValidLocalityLevels always registers ANY task locality level.
In the end, computeValidLocalityLevels prints out the following DEBUG message to the logs:
computeValidLocalityLevels is used when:
TaskSetManageris created and to recomputeLocality
executorAdded¶
executorAdded recomputeLocality.
executorAdded is used when:
TaskSchedulerImplis requested to handle resource offers
prepareLaunchingTask¶
prepareLaunchingTask(
execId: String,
host: String,
index: Int,
taskLocality: TaskLocality.Value,
speculative: Boolean,
taskCpus: Int,
taskResourceAssignments: Map[String, ResourceInformation],
launchTime: Long): TaskDescription
taskResourceAssignments
taskResourceAssignments are the resources that are passed in to resourceOffer.
prepareLaunchingTask...FIXME
prepareLaunchingTask is used when:
TaskSchedulerImplis requested to resourceOffersTaskSetManageris requested to resourceOffers
Serialized Task Size Threshold¶
TaskSetManager object defines TASK_SIZE_TO_WARN_KIB value as the threshold to warn a user if any stages contain a task that has a serialized size greater than 1000 kB.
DAGScheduler¶
DAGScheduler can print out the following WARN message to the logs when requested to submitMissingTasks:
TaskSetManager¶
TaskSetManager can print out the following WARN message to the logs when requested to prepareLaunchingTask:
Stage [stageId] contains a task of very large size ([serializedTask] KiB).
The maximum recommended task size is 1000 KiB.
Demo¶
Enable DEBUG logging level for org.apache.spark.scheduler.TaskSchedulerImpl (or org.apache.spark.scheduler.cluster.YarnScheduler for YARN) and org.apache.spark.scheduler.TaskSetManager and execute the following two-stage job to see their low-level innerworkings.
A cluster manager is recommended since it gives more task localization choices (with YARN additionally supporting rack localization).
$ ./bin/spark-shell \
--master yarn \
--conf spark.ui.showConsoleProgress=false
// Keep # partitions low to keep # messages low
scala> sc.parallelize(0 to 9, 3).groupBy(_ % 3).count
INFO YarnScheduler: Adding task set 0.0 with 3 tasks
DEBUG TaskSetManager: Epoch for TaskSet 0.0: 0
DEBUG TaskSetManager: Valid locality levels for TaskSet 0.0: NO_PREF, ANY
DEBUG YarnScheduler: parentName: , name: TaskSet_0.0, runningTasks: 0
INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 10.0.2.87, executor 1, partition 0, PROCESS_LOCAL, 7541 bytes)
INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 10.0.2.87, executor 2, partition 1, PROCESS_LOCAL, 7541 bytes)
DEBUG YarnScheduler: parentName: , name: TaskSet_0.0, runningTasks: 1
INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, 10.0.2.87, executor 1, partition 2, PROCESS_LOCAL, 7598 bytes)
DEBUG YarnScheduler: parentName: , name: TaskSet_0.0, runningTasks: 1
DEBUG TaskSetManager: No tasks for locality level NO_PREF, so moving to locality level ANY
INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 518 ms on 10.0.2.87 (executor 1) (1/3)
INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 512 ms on 10.0.2.87 (executor 2) (2/3)
DEBUG YarnScheduler: parentName: , name: TaskSet_0.0, runningTasks: 0
INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 51 ms on 10.0.2.87 (executor 1) (3/3)
INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
INFO YarnScheduler: Adding task set 1.0 with 3 tasks
DEBUG TaskSetManager: Epoch for TaskSet 1.0: 1
DEBUG TaskSetManager: Valid locality levels for TaskSet 1.0: NODE_LOCAL, RACK_LOCAL, ANY
DEBUG YarnScheduler: parentName: , name: TaskSet_1.0, runningTasks: 0
INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 3, 10.0.2.87, executor 2, partition 0, NODE_LOCAL, 7348 bytes)
INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 4, 10.0.2.87, executor 1, partition 1, NODE_LOCAL, 7348 bytes)
DEBUG YarnScheduler: parentName: , name: TaskSet_1.0, runningTasks: 1
INFO TaskSetManager: Starting task 2.0 in stage 1.0 (TID 5, 10.0.2.87, executor 1, partition 2, NODE_LOCAL, 7348 bytes)
INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 4) in 130 ms on 10.0.2.87 (executor 1) (1/3)
DEBUG YarnScheduler: parentName: , name: TaskSet_1.0, runningTasks: 1
DEBUG TaskSetManager: No tasks for locality level NODE_LOCAL, so moving to locality level RACK_LOCAL
DEBUG TaskSetManager: No tasks for locality level RACK_LOCAL, so moving to locality level ANY
INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 3) in 133 ms on 10.0.2.87 (executor 2) (2/3)
DEBUG YarnScheduler: parentName: , name: TaskSet_1.0, runningTasks: 0
INFO TaskSetManager: Finished task 2.0 in stage 1.0 (TID 5) in 21 ms on 10.0.2.87 (executor 1) (3/3)
INFO YarnScheduler: Removed TaskSet 1.0, whose tasks have all completed, from pool
res0: Long = 3
Logging¶
Enable ALL logging level for org.apache.spark.scheduler.TaskSetManager logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging