TaskScheduler¶
TaskScheduler is an abstraction of <
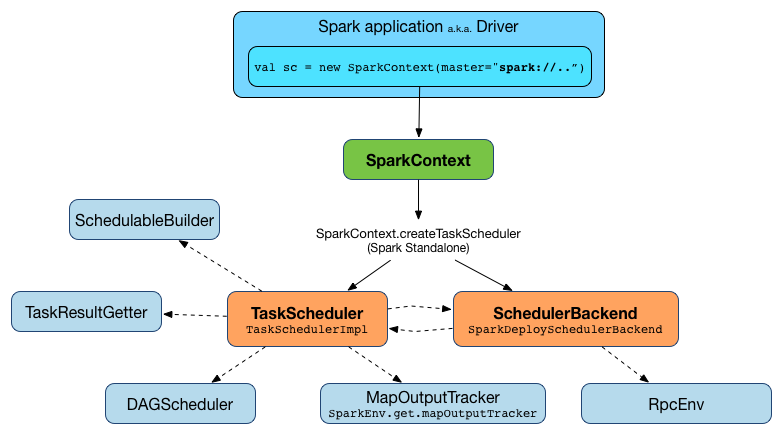
NOTE: TaskScheduler works closely with scheduler:DAGScheduler.md[DAGScheduler] that <
TaskScheduler can track the executors available in a Spark application using <
== [[submitTasks]] Submitting Tasks for Execution
[source, scala]¶
submitTasks( taskSet: TaskSet): Unit
Submits the tasks (of the given scheduler:TaskSet.md[TaskSet]) for execution.
Used when DAGScheduler is requested to scheduler:DAGScheduler.md#submitMissingTasks[submit missing tasks (of a stage)].
== [[executorHeartbeatReceived]] Handling Executor Heartbeat
[source, scala]¶
executorHeartbeatReceived( execId: String, accumUpdates: Array[(Long, Seq[AccumulatorV2[_, _]])], blockManagerId: BlockManagerId): Boolean
Handles a heartbeat from an executor
Returns true when the execId executor is managed by the TaskScheduler. false indicates that the executor:Executor.md#reportHeartBeat[block manager (on the executor) should re-register].
Used when HeartbeatReceiver RPC endpoint is requested to handle a Heartbeat (with task metrics) from an executor
== [[killTaskAttempt]] Killing Task
[source, scala]¶
killTaskAttempt( taskId: Long, interruptThread: Boolean, reason: String): Boolean
Kills a task (attempt)
Used when DAGScheduler is requested to scheduler:DAGScheduler.md#killTaskAttempt[kill a task]
== [[workerRemoved]] workerRemoved Notification
[source, scala]¶
workerRemoved( workerId: String, host: String, message: String): Unit
Used when DriverEndpoint is requested to handle a RemoveWorker event
== [[contract]] Contract
[cols="30m,70",options="header",width="100%"] |=== | Method | Description
| applicationAttemptId a| [[applicationAttemptId]]
[source, scala]¶
applicationAttemptId(): Option[String]¶
Unique identifier of an (execution) attempt of the Spark application
Used when SparkContext is created
| cancelTasks a| [[cancelTasks]]
[source, scala]¶
cancelTasks( stageId: Int, interruptThread: Boolean): Unit
Cancels all the tasks of a given Stage.md[stage]
Used when DAGScheduler is requested to DAGScheduler.md#failJobAndIndependentStages[failJobAndIndependentStages]
| defaultParallelism a| [[defaultParallelism]]
[source, scala]¶
defaultParallelism(): Int¶
Default level of parallelism
Used when SparkContext is requested for the default level of parallelism
| executorLost a| [[executorLost]]
[source, scala]¶
executorLost( executorId: String, reason: ExecutorLossReason): Unit
Handles an executor lost event
Used when:
-
HeartbeatReceiverRPC endpoint is requested to expireDeadHosts -
DriverEndpointRPC endpoint is requested to removes (forgets) and disables a malfunctioning executor (i.e. either lost or blacklisted for some reason)
| killAllTaskAttempts a| [[killAllTaskAttempts]]
[source, scala]¶
killAllTaskAttempts( stageId: Int, interruptThread: Boolean, reason: String): Unit
Used when:
-
DAGScheduler is requested to DAGScheduler.md#handleTaskCompletion[handleTaskCompletion]
-
TaskSchedulerImplis requested to TaskSchedulerImpl.md#cancelTasks[cancel all the tasks of a stage]
| rootPool a| [[rootPool]]
[source, scala]¶
rootPool: Pool¶
Top-level (root) scheduler:spark-scheduler-Pool.md[schedulable pool]
Used when:
-
TaskSchedulerImplis requested to scheduler:TaskSchedulerImpl.md#initialize[initialize] -
SparkContextis requested to SparkContext.md#getAllPools[getAllPools] and SparkContext.md#getPoolForName[getPoolForName] -
TaskSchedulerImplis requested to scheduler:TaskSchedulerImpl.md#resourceOffers[resourceOffers], scheduler:TaskSchedulerImpl.md#checkSpeculatableTasks[checkSpeculatableTasks], and scheduler:TaskSchedulerImpl.md#removeExecutor[removeExecutor]
| schedulingMode a| [[schedulingMode]]
[source, scala]¶
schedulingMode: SchedulingMode¶
scheduler:spark-scheduler-SchedulingMode.md[Scheduling mode]
Used when:
-
TaskSchedulerImplis scheduler:TaskSchedulerImpl.md#rootPool[created] and scheduler:TaskSchedulerImpl.md#initialize[initialized] -
SparkContextis requested to SparkContext.md#getSchedulingMode[getSchedulingMode]
| setDAGScheduler a| [[setDAGScheduler]]
[source, scala]¶
setDAGScheduler(dagScheduler: DAGScheduler): Unit¶
Associates a scheduler:DAGScheduler.md[DAGScheduler]
Used when DAGScheduler is scheduler:DAGScheduler.md#creating-instance[created]
| start a| [[start]]
[source, scala]¶
start(): Unit¶
Starts the TaskScheduler
Used when SparkContext is created
| stop a| [[stop]]
[source, scala]¶
stop(): Unit¶
Stops the TaskScheduler
Used when DAGScheduler is requested to scheduler:DAGScheduler.md#stop[stop]
|===
Lifecycle¶
A TaskScheduler is created while SparkContext is being created (by calling SparkContext.createTaskScheduler for a given master URL and deploy mode).
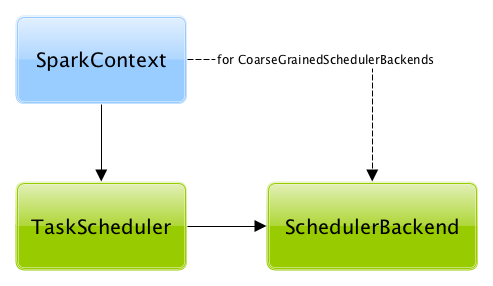
At this point in SparkContext's lifecycle, the internal _taskScheduler points at the TaskScheduler (and it is "announced" by sending a blocking TaskSchedulerIsSet message to HeartbeatReceiver RPC endpoint).
The <TaskSchedulerIsSet message receives a response.
The <SparkContext uses the application id to set SparkConf.md#spark.app.id[spark.app.id] Spark property, and configure webui:spark-webui-SparkUI.md[SparkUI], and storage:BlockManager.md[BlockManager]).
CAUTION: FIXME The application id is described as "associated with the job." in TaskScheduler, but I think it is "associated with the application" and you can have many jobs per application.
Right before SparkContext is fully initialized, <
The internal _taskScheduler is cleared (i.e. set to null) while SparkContext.md#stop[SparkContext is being stopped].
<
WARNING: FIXME If it is SparkContext to start a TaskScheduler, shouldn't SparkContext stop it too? Why is this the way it is now?
== [[postStartHook]] Post-Start Initialization
[source, scala]¶
postStartHook(): Unit¶
postStartHook does nothing by default, but allows <
postStartHook is used when:
-
SparkContext is created
-
Spark on YARN's
YarnClusterScheduleris requested to spark-on-yarn:spark-yarn-yarnclusterscheduler.md#postStartHook[postStartHook]
== [[applicationId]][[appId]] Unique Identifier of Spark Application
[source, scala]¶
applicationId(): String¶
applicationId is the unique identifier of the Spark application and defaults to spark-application-[currentTimeMillis].
applicationId is used when SparkContext is created.