Task¶
Task is an abstraction of the smallest individual units of execution that can be executed (to compute an RDD partition).
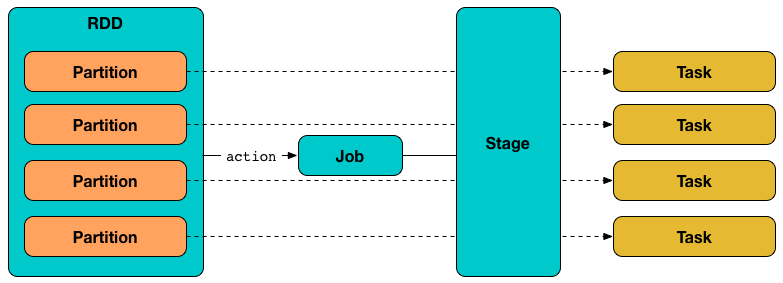
Contract¶
Running Task¶
Runs the task (in a TaskContext)
Used when Task is requested to run
Implementations¶
Creating Instance¶
Task takes the following to be created:
- Stage ID
- Stage (execution) Attempt ID
- Partition ID to compute
- Local Properties
- Serialized TaskMetrics (
Array[Byte]) - ActiveJob ID (default:
None) - Application ID (default:
None) - Application Attempt ID (default:
None) - isBarrier flag
Task is created when:
DAGScheduleris requested to submit missing tasks of a stage
Abstract Class
Task is an abstract class and cannot be created directly. It is created indirectly for the concrete Tasks.
isBarrier Flag¶
Task can be given isBarrier flag when created. Unless given, isBarrier is assumed disabled (false).
isBarrier flag indicates whether this Task belongs to a Barrier Stage in Barrier Execution Mode.
isBarrier flag is used when:
DAGScheduleris requested to handleTaskCompletion (of aFetchFailedtask) to fail the parent stage (and retry a barrier stage when one of the barrier tasks fails)Taskis requested to run (to create a BarrierTaskContext)TaskSetManageris requested to isBarrier and handleFailedTask
TaskMemoryManager¶
Task is given a TaskMemoryManager when TaskRunner is requested to run a task (right after deserializing the task for execution).
Task uses the TaskMemoryManager to create a TaskContextImpl (when requested to run).
Serializable¶
Task is a Serializable (Java) so it can be serialized (to bytes) and send over the wire for execution from the driver to executors.
Preferred Locations¶
TaskLocations that represent preferred locations (executors) to execute the task on.
Empty by default and so no task location preferences are defined that says the task could be launched on any executor.
Note
Defined by the concrete tasks (i.e. ShuffleMapTask and ResultTask).
preferredLocations is used when TaskSetManager is requested to register a task as pending execution and dequeueSpeculativeTask.
Running Task¶
run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem,
resources: Map[String, ResourceInformation],
plugins: Option[PluginContainer]): T
run registers the task (attempt) with the BlockManager.
run creates a TaskContextImpl (and perhaps a BarrierTaskContext too when the given isBarrier flag is enabled) that in turn becomes the task's TaskContext.
run checks _killed flag and, if enabled, kills the task (with interruptThread flag disabled).
run creates a Hadoop CallerContext and sets it.
run informs the given PluginContainer that the task is started.
run runs the task.
Note
This is the moment when the custom Task's runTask is executed.
In the end, run notifies TaskContextImpl that the task has completed (regardless of the final outcome -- a success or a failure).
In case of any exceptions, run notifies TaskContextImpl that the task has failed. run requests MemoryStore to release unroll memory for this task (for both ON_HEAP and OFF_HEAP memory modes).
Note
run uses SparkEnv to access the current BlockManager that it uses to access MemoryStore.
run unsets the task's TaskContext.
Note
run uses SparkEnv to access the current MemoryManager.
run is used when:
TaskRunneris requested to run (whenExecutoris requested to launch a task (on "Executor task launch worker" thread pool sometime in the future))
Task States¶
Task can be in one of the following states (as described by TaskState enumeration):
LAUNCHINGRUNNINGwhen the task is being started.FINISHEDwhen the task finished with the serialized result.FAILEDwhen the task fails, e.g. when FetchFailedException,CommitDeniedExceptionor anyThrowableoccursKILLEDwhen an executor kills a task.LOST
States are the values of org.apache.spark.TaskState.
Note
Task status updates are sent from executors to the driver through ExecutorBackend.
Task is finished when it is in one of FINISHED, FAILED, KILLED, LOST.
LOST and FAILED states are considered failures.
Collecting Latest Values of Accumulators¶
collectAccumulatorUpdates collects the latest values of internal and external accumulators from a task (and returns the values as a collection of AccumulableInfo).
Internally, collectAccumulatorUpdates takes TaskMetrics.
Note
collectAccumulatorUpdates uses TaskContextImpl to access the task's TaskMetrics.
collectAccumulatorUpdates collects the latest values of:
-
internal accumulators whose current value is not the zero value and the
RESULT_SIZEaccumulator (regardless whether the value is its zero or not). -
external accumulators when
taskFailedis disabled (false) or which should be included on failures.
collectAccumulatorUpdates returns an empty collection when TaskContextImpl is not initialized.
collectAccumulatorUpdates is used when TaskRunner runs a task (and sends a task's final results back to the driver).
Killing Task¶
kill marks the task to be killed, i.e. it sets the internal _killed flag to true.
kill calls TaskContextImpl.markInterrupted when context is set.
If interruptThread is enabled and the internal taskThread is available, kill interrupts it.
CAUTION: FIXME When could context and interruptThread not be set?