Stage¶
Stage is an abstraction of steps in a physical execution plan.
Note
The logical DAG or logical execution plan is the RDD lineage.
Indirectly, a Stage is a set of parallel tasks - one task per partition (of an RDD that computes partial results of a function executed as part of a Spark job).
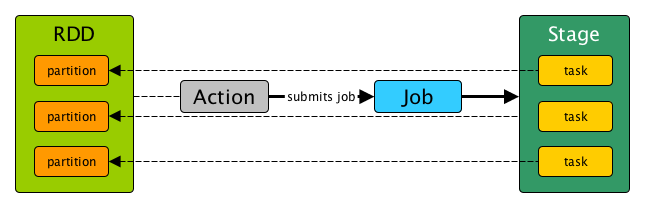
In other words, a Spark job is a computation "sliced" (not to use the reserved term partitioned) into stages.
Contract¶
Missing Partitions¶
Missing partitions (IDs of the partitions of the RDD that are missing and need to be computed)
Used when:
DAGScheduleris requested to submit missing tasks
Implementations¶
Creating Instance¶
Stage takes the following to be created:
Abstract Class
Stage is an abstract class and cannot be created directly. It is created indirectly for the concrete Stages.
RDD¶
Stage is given a RDD when created.
Stage ID¶
Stage is given an unique ID when created.
Note
DAGScheduler uses nextStageId internal counter to track the number of stage submissions.
Making New Stage Attempt¶
makeNewStageAttempt(
numPartitionsToCompute: Int,
taskLocalityPreferences: Seq[Seq[TaskLocation]] = Seq.empty): Unit
makeNewStageAttempt creates a new TaskMetrics and requests it to register itself with the SparkContext of the RDD.
makeNewStageAttempt creates a StageInfo from this Stage (and the nextAttemptId). This StageInfo is saved in the _latestInfo internal registry.
In the end, makeNewStageAttempt increments the nextAttemptId internal counter.
Note
makeNewStageAttempt returns Unit (nothing) and its purpose is to update the latest StageInfo internal registry.
makeNewStageAttempt is used when:
DAGScheduleris requested to submit the missing tasks of a stage