ShuffleMapTask¶
ShuffleMapTask is a Task to produce a MapStatus (Task[MapStatus]).
ShuffleMapTask is one of the two types of Tasks. When executed, ShuffleMapTask writes the result of executing a serialized task code over the records (of a RDD partition) to the shuffle system and returns a MapStatus (with the BlockManager and estimated size of the result shuffle blocks).
Creating Instance¶
ShuffleMapTask takes the following to be created:
- Stage ID
- Stage Attempt ID
- Broadcast variable with a serialized task binary
- Partition
- TaskLocations
- Local Properties
- Serialized task metrics
- Job ID (default:
None) - Application ID (default:
None) - Application Attempt ID (default:
None) - isBarrier flag
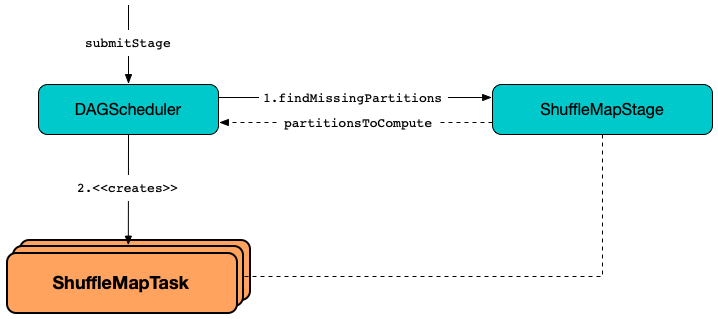
ShuffleMapTask is created when DAGScheduler is requested to submit tasks for all missing partitions of a ShuffleMapStage.
isBarrier Flag¶
ShuffleMapTask can be given isBarrier flag when created. Unless given, isBarrier is assumed disabled (false).
isBarrier flag is passed to the parent Task.
Serialized Task Binary¶
ShuffleMapTask is given a broadcast variable with a reference to a serialized task binary.
runTask expects that the serialized task binary is a tuple of an RDD and a ShuffleDependency.
Preferred Locations¶
preferredLocations returns preferredLocs internal property.
ShuffleMapTask tracks TaskLocations as unique entries in the given locs (with the only rule that when locs is not defined, it is empty, and no task location preferences are defined).
ShuffleMapTask initializes the preferredLocs internal property when created
Running Task¶
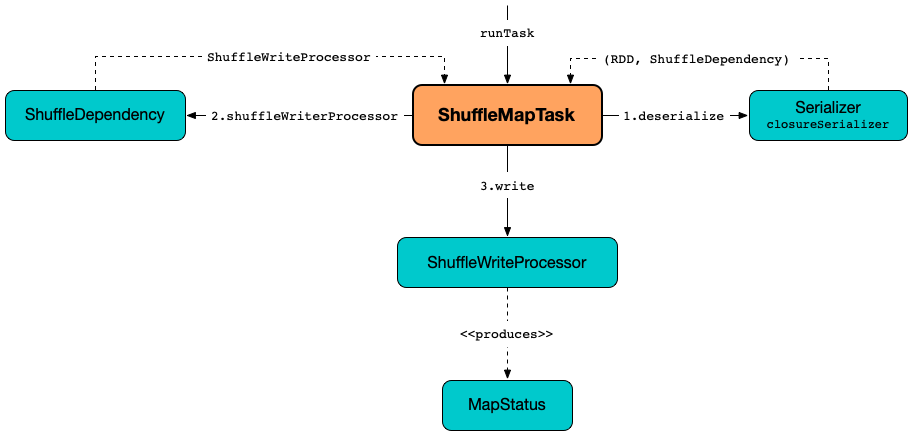
runTask writes the result (records) of executing the serialized task code over the records (in the RDD partition) to the shuffle system and returns a MapStatus (with the BlockManager and an estimated size of the result shuffle blocks).
Internally, runTask requests the SparkEnv for the new instance of closure serializer and requests it to deserialize the serialized task code (into a tuple of a RDD and a ShuffleDependency).
runTask measures the thread and CPU deserialization times.
runTask requests the SparkEnv for the ShuffleManager and requests it for a ShuffleWriter (for the ShuffleHandle and the partition).
runTask then requests the RDD for the records (of the partition) that the ShuffleWriter is requested to write out (to the shuffle system).
In the end, runTask requests the ShuffleWriter to stop (with the success flag on) and returns the shuffle map output status.
Note
This is the moment in Task's lifecycle (and its corresponding RDD) when a RDD partition is computed and in turn becomes a sequence of records (i.e. real data) on an executor.
In case of any exceptions, runTask requests the ShuffleWriter to stop (with the success flag off) and (re)throws the exception.
runTask may also print out the following DEBUG message to the logs when the ShuffleWriter could not be stopped.
Logging¶
Enable ALL logging level for org.apache.spark.scheduler.ShuffleMapTask logger to see what happens inside.
Add the following line to conf/log4j2.properties:
logger.ShuffleMapTask.name = org.apache.spark.scheduler.ShuffleMapTask
logger.ShuffleMapTask.level = all
Refer to Logging.