DAGScheduler¶
Note
The introduction that follows was highly influenced by the scaladoc of org.apache.spark.scheduler.DAGScheduler. As DAGScheduler is a private class it does not appear in the official API documentation. You are strongly encouraged to read the sources and only then read this and the related pages afterwards.
Introduction¶
DAGScheduler is the scheduling layer of Apache Spark that implements stage-oriented scheduling using Jobs and Stages.
DAGScheduler transforms a logical execution plan (RDD lineage of dependencies built using RDD transformations) to a physical execution plan (using stages).
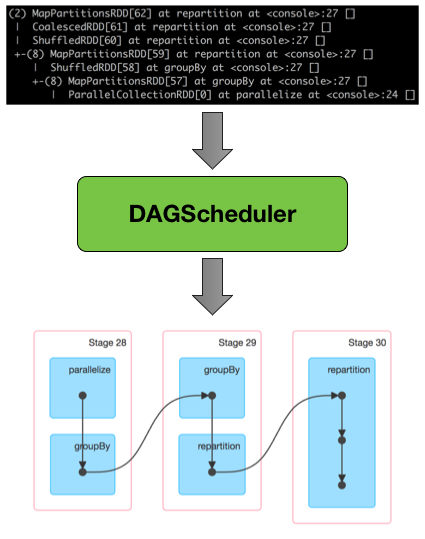
After an action has been called on an RDD, SparkContext hands over a logical plan to DAGScheduler that it in turn translates to a set of stages that are submitted as TaskSets for execution.
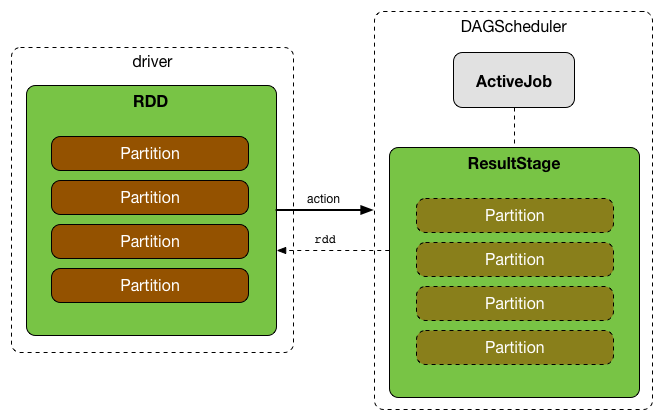
DAGScheduler works solely on the driver and is created as part of SparkContext's initialization (right after TaskScheduler and SchedulerBackend are ready).
DAGScheduler does three things in Spark:
- Computes an execution DAG (DAG of stages) for a job
- Determines the preferred locations to run each task on
- Handles failures due to shuffle output files being lost
DAGScheduler computes a directed acyclic graph (DAG) of stages for each job, keeps track of which RDDs and stage outputs are materialized, and finds a minimal schedule to run jobs. It then submits stages to TaskScheduler.
In addition to coming up with the execution DAG, DAGScheduler also determines the preferred locations to run each task on, based on the current cache status, and passes the information to TaskScheduler.
DAGScheduler tracks which RDDs are cached (or persisted) to avoid "recomputing" them (re-doing the map side of a shuffle). DAGScheduler remembers what ShuffleMapStages have already produced output files (that are stored in BlockManagers).
DAGScheduler is only interested in cache location coordinates (i.e. host and executor id, per partition of a RDD).
Furthermore, DAGScheduler handles failures due to shuffle output files being lost, in which case old stages may need to be resubmitted. Failures within a stage that are not caused by shuffle file loss are handled by the TaskScheduler itself, which will retry each task a small number of times before cancelling the whole stage.
DAGScheduler uses an event queue architecture in which a thread can post DAGSchedulerEvent events, e.g. a new job or stage being submitted, that DAGScheduler reads and executes sequentially. See the section Event Bus.
DAGScheduler runs stages in topological order.
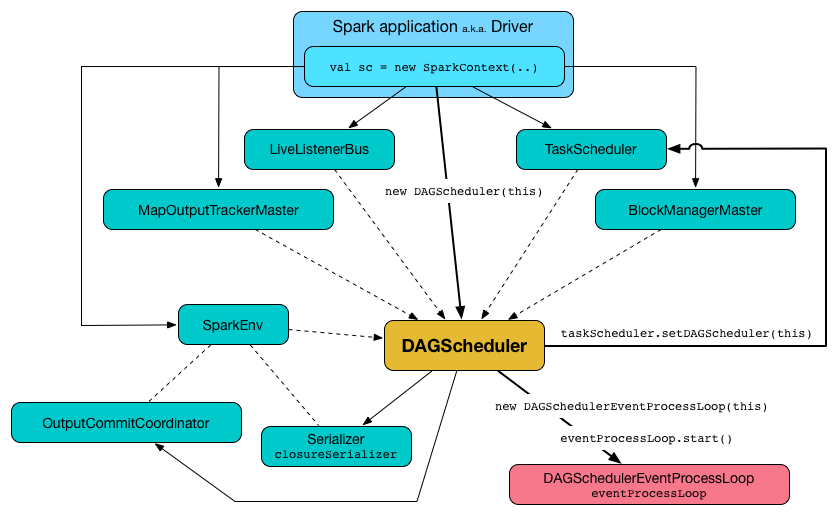
DAGScheduler uses SparkContext, TaskScheduler, LiveListenerBus, MapOutputTracker and BlockManager for its services. However, at the very minimum, DAGScheduler takes a SparkContext only (and requests SparkContext for the other services).
When DAGScheduler schedules a job as a result of executing an action on a RDD or calling SparkContext.runJob directly, it spawns parallel tasks to compute (partial) results per partition.
Creating Instance¶
DAGScheduler takes the following to be created:
DAGScheduler is created when SparkContext is created.
While being created, DAGScheduler requests the TaskScheduler to associate itself with and requests DAGScheduler Event Bus to start accepting events.
Submitting MapStage for Execution (Posting MapStageSubmitted)¶
submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C],
callback: MapOutputStatistics => Unit,
callSite: CallSite,
properties: Properties): JobWaiter[MapOutputStatistics]
submitMapStage requests the given ShuffleDependency for the RDD.
submitMapStage gets the job ID and increments it (for future submissions).
submitMapStage creates a JobWaiter to wait for a MapOutputStatistics. The JobWaiter waits for 1 task and, when completed successfully, executes the given callback function with the computed MapOutputStatistics.
In the end, submitMapStage posts a MapStageSubmitted and returns the JobWaiter.
Used when:
SparkContextis requested to submit a MapStage for execution
DAGSchedulerSource¶
DAGScheduler uses DAGSchedulerSource for performance metrics.
DAGScheduler Event Bus¶
DAGScheduler uses an event bus to process scheduling events on a separate thread (one by one and asynchronously).
DAGScheduler requests the event bus to start right when created and stops it when requested to stop.
DAGScheduler defines event-posting methods for posting DAGSchedulerEvent events to the event bus.
TaskScheduler¶
DAGScheduler is given a TaskScheduler when created.
TaskScheduler is used for the following:
- Submitting missing tasks of a stage
- Handling task completion (CompletionEvent)
- Killing a task
- Failing a job and all other independent single-job stages
- Stopping itself
Running Job¶
runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit
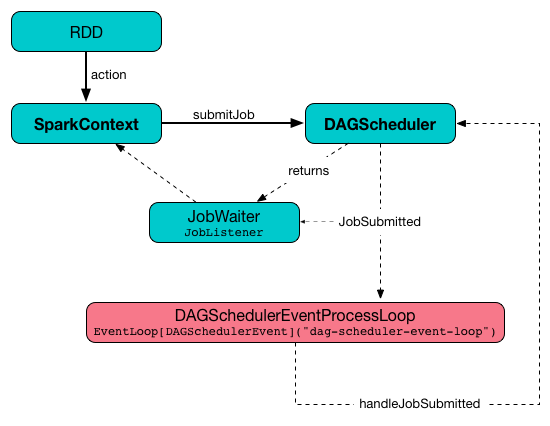
runJob submits a job and waits until a result is available.
runJob prints out the following INFO message to the logs when the job has finished successfully:
runJob prints out the following INFO message to the logs when the job has failed:
runJob is used when:
SparkContextis requested to run a job
Submitting Job¶
submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U]
submitJob increments the nextJobId internal counter.
submitJob creates a JobWaiter for the (number of) partitions and the given resultHandler function.
submitJob requests the DAGSchedulerEventProcessLoop to post a JobSubmitted.
In the end, submitJob returns the JobWaiter.
For empty partitions (no partitions to compute), submitJob requests the LiveListenerBus to post a SparkListenerJobStart and SparkListenerJobEnd (with JobSucceeded result marker) events and returns a JobWaiter with no tasks to wait for.
submitJob throws an IllegalArgumentException when the partitions indices are not among the partitions of the given RDD:
submitJob is used when:
SparkContextis requested to submit a jobDAGScheduleris requested to run a job
Partition Placement Preferences¶
DAGScheduler keeps track of block locations per RDD and partition.
DAGScheduler uses TaskLocation that includes a host name and an executor id on that host (as ExecutorCacheTaskLocation).
The keys are RDDs (their ids) and the values are arrays indexed by partition numbers.
Each entry is a set of block locations where a RDD partition is cached, i.e. the BlockManagers of the blocks.
Initialized empty when DAGScheduler is created.
Used when DAGScheduler is requested for the locations of the cache blocks of a RDD.
ActiveJobs¶
DAGScheduler tracks ActiveJobs:
-
Adds a new
ActiveJobwhen requested to handle JobSubmitted or MapStageSubmitted events -
Removes an
ActiveJobwhen requested to clean up after an ActiveJob and independent stages. -
Removes all
ActiveJobswhen requested to doCancelAllJobs.
DAGScheduler uses ActiveJobs registry when requested to handle JobGroupCancelled or TaskCompletion events, to cleanUpAfterSchedulerStop and to abort a stage.
The number of ActiveJobs is available using job.activeJobs performance metric.
Creating ResultStage for RDD¶
createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage
createResultStage creates a new ResultStage for the ShuffleDependencies and ResourceProfiles of the given RDD.
createResultStage finds the ShuffleDependencies and ResourceProfiles for the given RDD.
createResultStage merges the ResourceProfiles for the Stage (if enabled or reports an exception).
createResultStage does the following checks (that may report violations and break the execution):
- checkBarrierStageWithDynamicAllocation
- checkBarrierStageWithNumSlots
- checkBarrierStageWithRDDChainPattern
createResultStage getOrCreateParentStages (with the ShuffleDependencyies and the given jobId).
createResultStage uses the nextStageId counter for a stage ID.
createResultStage creates a new ResultStage (with the unique id of a ResourceProfile among others).
createResultStage registers the ResultStage with the stage ID in stageIdToStage.
createResultStage updateJobIdStageIdMaps and returns the ResultStage.
createResultStage is used when:
DAGScheduleris requested to handle a JobSubmitted event
Creating ShuffleMapStage for ShuffleDependency¶
createShuffleMapStage creates a ShuffleMapStage for the given ShuffleDependency as follows:
-
Stage ID is generated based on nextStageId internal counter
-
RDD is taken from the given ShuffleDependency
-
Number of tasks is the number of partitions of the RDD
createShuffleMapStage registers the ShuffleMapStage in the stageIdToStage and shuffleIdToMapStage internal registries.
createShuffleMapStage updateJobIdStageIdMaps.
createShuffleMapStage requests the MapOutputTrackerMaster to check whether it contains the shuffle ID or not.
If not, createShuffleMapStage prints out the following INFO message to the logs and requests the MapOutputTrackerMaster to register the shuffle.
![]()
createShuffleMapStage is used when:
DAGScheduleris requested to find or create a ShuffleMapStage for a given ShuffleDependency
Cleaning Up After Job and Independent Stages¶
cleanupStateForJobAndIndependentStages cleans up the state for job and any stages that are not part of any other job.
cleanupStateForJobAndIndependentStages looks the job up in the internal jobIdToStageIds registry.
If no stages are found, the following ERROR is printed out to the logs:
Oterwise, cleanupStateForJobAndIndependentStages uses stageIdToStage registry to find the stages (the real objects not ids!).
For each stage, cleanupStateForJobAndIndependentStages reads the jobs the stage belongs to.
If the job does not belong to the jobs of the stage, the following ERROR is printed out to the logs:
If the job was the only job for the stage, the stage (and the stage id) gets cleaned up from the registries, i.e. runningStages, shuffleIdToMapStage, waitingStages, failedStages and stageIdToStage.
While removing from runningStages, you should see the following DEBUG message in the logs:
While removing from waitingStages, you should see the following DEBUG message in the logs:
While removing from failedStages, you should see the following DEBUG message in the logs:
After all cleaning (using stageIdToStage as the source registry), if the stage belonged to the one and only job, you should see the following DEBUG message in the logs:
The job is removed from jobIdToStageIds, jobIdToActiveJob, activeJobs registries.
The final stage of the job is removed, i.e. ResultStage or ShuffleMapStage.
cleanupStateForJobAndIndependentStages is used in handleTaskCompletion when a ResultTask has completed successfully, failJobAndIndependentStages and markMapStageJobAsFinished.
Marking ShuffleMapStage Job Finished¶
markMapStageJobAsFinished marks the given ActiveJob finished and posts a SparkListenerJobEnd.
markMapStageJobAsFinished requests the given ActiveJob to turn on (true) the 0th bit in the finished partitions registry and increase the number of tasks finished.
markMapStageJobAsFinished requests the given ActiveJob for the JobListener that is requested to taskSucceeded (with the 0th index and the given MapOutputStatistics).
markMapStageJobAsFinished cleanupStateForJobAndIndependentStages.
In the end, markMapStageJobAsFinished requests the LiveListenerBus to post a SparkListenerJobEnd.
markMapStageJobAsFinished is used when:
DAGScheduleris requested to handleMapStageSubmitted and markMapStageJobsAsFinished
Finding Or Creating Missing Direct Parent ShuffleMapStages (For ShuffleDependencies) of RDD¶
getOrCreateParentStages finds all direct parent ShuffleDependencies of the input rdd and then finds ShuffleMapStages for each ShuffleDependency.
getOrCreateParentStages is used when DAGScheduler is requested to create a ShuffleMapStage or a ResultStage.
Marking Stage Finished¶
markStageAsFinished(
stage: Stage,
errorMessage: Option[String] = None,
willRetry: Boolean = false): Unit
markStageAsFinished...FIXME
markStageAsFinished is used when...FIXME
Looking Up ShuffleMapStage for ShuffleDependency¶
getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage
getOrCreateShuffleMapStage finds a ShuffleMapStage by the shuffleId of the given ShuffleDependency in the shuffleIdToMapStage internal registry and returns it if available.
If not found, getOrCreateShuffleMapStage finds all the missing ancestor shuffle dependencies and creates the missing ShuffleMapStage stages (including one for the input ShuffleDependency).
getOrCreateShuffleMapStage is used when:
DAGScheduleris requested to find or create missing direct parent ShuffleMapStages of an RDD, find missing parent ShuffleMapStages for a stage, handle a MapStageSubmitted event, and check out stage dependency on a stage
Missing ShuffleDependencies of RDD¶
getMissingAncestorShuffleDependencies finds all the missing ShuffleDependencies for the given RDD (traversing its RDD lineage).
Note
A ShuffleDependency (of an RDD) is considered missing when not registered in the shuffleIdToMapStage internal registry.
Internally, getMissingAncestorShuffleDependencies finds direct parent shuffle dependencies of the input RDD and collects the ones that are not registered in the shuffleIdToMapStage internal registry. It repeats the process for the RDDs of the parent shuffle dependencies.
Finding Direct Parent Shuffle Dependencies of RDD¶
getShuffleDependencies finds direct parent shuffle dependencies for the given RDD.
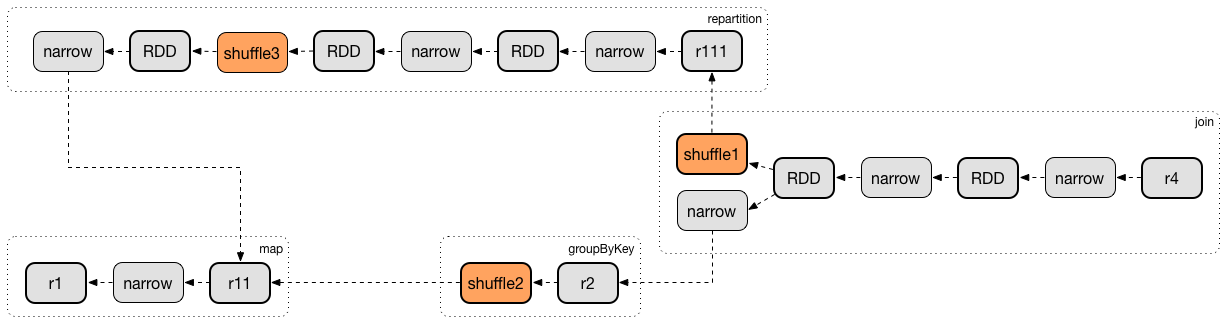
Internally, getShuffleDependencies takes the direct rdd/index.md#dependencies[shuffle dependencies of the input RDD] and direct shuffle dependencies of all the parent non-ShuffleDependencies in the RDD lineage.
getShuffleDependencies is used when DAGScheduler is requested to find or create missing direct parent ShuffleMapStages (for ShuffleDependencies of a RDD) and find all missing shuffle dependencies for a given RDD.
Failing Job and Independent Single-Job Stages¶
failJobAndIndependentStages(
job: ActiveJob,
failureReason: String,
exception: Option[Throwable] = None): Unit
failJobAndIndependentStages fails the input job and all the stages that are only used by the job.
Internally, failJobAndIndependentStages uses jobIdToStageIds internal registry to look up the stages registered for the job.
If no stages could be found, you should see the following ERROR message in the logs:
Otherwise, for every stage, failJobAndIndependentStages finds the job ids the stage belongs to.
If no stages could be found or the job is not referenced by the stages, you should see the following ERROR message in the logs:
Only when there is exactly one job registered for the stage and the stage is in RUNNING state (in runningStages internal registry), TaskScheduler.md#contract[TaskScheduler is requested to cancel the stage's tasks] and marks the stage finished.
NOTE: failJobAndIndependentStages uses jobIdToStageIds, stageIdToStage, and runningStages internal registries.
failJobAndIndependentStages is used when...FIXME
Aborting Stage¶
abortStage is an internal method that finds all the active jobs that depend on the failedStage stage and fails them.
Internally, abortStage looks the failedStage stage up in the internal stageIdToStage registry and exits if there the stage was not registered earlier.
If it was, abortStage finds all the active jobs (in the internal activeJobs registry) with the final stage depending on the failedStage stage.
At this time, the completionTime property (of the failed stage's StageInfo) is assigned to the current time (millis).
All the active jobs that depend on the failed stage (as calculated above) and the stages that do not belong to other jobs (aka independent stages) are failed (with the failure reason being "Job aborted due to stage failure: [reason]" and the input exception).
If there are no jobs depending on the failed stage, you should see the following INFO message in the logs:
abortStage is used when DAGScheduler is requested to handle a TaskSetFailed event, submit a stage, submit missing tasks of a stage, handle a TaskCompletion event.
Checking Out Stage Dependency on Given Stage¶
stageDependsOn compares two stages and returns whether the stage depends on target stage (i.e. true) or not (i.e. false).
NOTE: A stage A depends on stage B if B is among the ancestors of A.
Internally, stageDependsOn walks through the graph of RDDs of the input stage. For every RDD in the RDD's dependencies (using RDD.dependencies) stageDependsOn adds the RDD of a NarrowDependency to a stack of RDDs to visit while for a ShuffleDependency it finds ShuffleMapStage stages for a ShuffleDependency for the dependency and the stage's first job id that it later adds to a stack of RDDs to visit if the map stage is ready, i.e. all the partitions have shuffle outputs.
After all the RDDs of the input stage are visited, stageDependsOn checks if the target's RDD is among the RDDs of the stage, i.e. whether the stage depends on target stage.
stageDependsOn is used when DAGScheduler is requested to abort a stage.
Submitting Waiting Child Stages for Execution¶
submitWaitingChildStages submits for execution all waiting stages for which the input parent Stage.md[Stage] is the direct parent.
NOTE: Waiting stages are the stages registered in waitingStages internal registry.
When executed, you should see the following TRACE messages in the logs:
Checking if any dependencies of [parent] are now runnable
running: [runningStages]
waiting: [waitingStages]
failed: [failedStages]
submitWaitingChildStages finds child stages of the input parent stage, removes them from waitingStages internal registry, and submits one by one sorted by their job ids.
submitWaitingChildStages is used when DAGScheduler is requested to submits missing tasks for a stage and handles a successful ShuffleMapTask completion.
Submitting Stage (with Missing Parents) for Execution¶
submitStage submits the input stage or its missing parents (if there any stages not computed yet before the input stage could).
NOTE: submitStage is also used to DAGSchedulerEventProcessLoop.md#resubmitFailedStages[resubmit failed stages].
submitStage recursively submits any missing parents of the stage.
Internally, submitStage first finds the earliest-created job id that needs the stage.
NOTE: A stage itself tracks the jobs (their ids) it belongs to (using the internal jobIds registry).
The following steps depend on whether there is a job or not.
If there are no jobs that require the stage, submitStage aborts it with the reason:
If however there is a job for the stage, you should see the following DEBUG message in the logs:
submitStage checks the status of the stage and continues when it was not recorded in waiting, running or failed internal registries. It simply exits otherwise.
With the stage ready for submission, submitStage calculates the list of missing parent stages of the stage (sorted by their job ids). You should see the following DEBUG message in the logs:
When the stage has no parent stages missing, you should see the following INFO message in the logs:
submitStage submits the stage (with the earliest-created job id) and finishes.
If however there are missing parent stages for the stage, submitStage submits all the parent stages, and the stage is recorded in the internal waitingStages registry.
submitStage is used recursively for missing parents of the given stage and when DAGScheduler is requested for the following:
-
resubmitFailedStages (ResubmitFailedStages event)
-
submitWaitingChildStages (CompletionEvent event)
-
Handle JobSubmitted, MapStageSubmitted and TaskCompletion events
Stage Attempts¶
A single stage can be re-executed in multiple attempts due to fault recovery. The number of attempts is configured (FIXME).
If TaskScheduler reports that a task failed because a map output file from a previous stage was lost, the DAGScheduler resubmits the lost stage. This is detected through a DAGSchedulerEventProcessLoop.md#handleTaskCompletion-FetchFailed[CompletionEvent with FetchFailed], or an ExecutorLost event. DAGScheduler will wait a small amount of time to see whether other nodes or tasks fail, then resubmit TaskSets for any lost stage(s) that compute the missing tasks.
Please note that tasks from the old attempts of a stage could still be running.
A stage object tracks multiple StageInfo objects to pass to Spark listeners or the web UI.
The latest StageInfo for the most recent attempt for a stage is accessible through latestInfo.
Preferred Locations¶
DAGScheduler computes where to run each task in a stage based on the rdd/index.md#getPreferredLocations[preferred locations of its underlying RDDs], or the location of cached or shuffle data.
Adaptive Query Planning / Adaptive Scheduling¶
See SPARK-9850 Adaptive execution in Spark for the design document. The work is currently in progress.
DAGScheduler.submitMapStage method is used for adaptive query planning, to run map stages and look at statistics about their outputs before submitting downstream stages.
ScheduledExecutorService daemon services¶
DAGScheduler uses the following ScheduledThreadPoolExecutors (with the policy of removing cancelled tasks from a work queue at time of cancellation):
dag-scheduler-message- a daemon thread pool usingj.u.c.ScheduledThreadPoolExecutorwith core pool size1. It is used to post a DAGSchedulerEventProcessLoop.md#ResubmitFailedStages[ResubmitFailedStages] event when DAGSchedulerEventProcessLoop.md#handleTaskCompletion-FetchFailed[FetchFailedis reported].
They are created using ThreadUtils.newDaemonSingleThreadScheduledExecutor method that uses Guava DSL to instantiate a ThreadFactory.
Finding Missing Parent ShuffleMapStages For Stage¶
getMissingParentStages finds missing parent ShuffleMapStages in the dependency graph of the input stage (using the breadth-first search algorithm).
Internally, getMissingParentStages starts with the stage's RDD and walks up the tree of all parent RDDs to find uncached partitions.
NOTE: A Stage tracks the associated RDD using Stage.md#rdd[rdd property].
NOTE: An uncached partition of a RDD is a partition that has Nil in the internal registry of partition locations per RDD (which results in no RDD blocks in any of the active storage:BlockManager.md[BlockManager]s on executors).
getMissingParentStages traverses the rdd/index.md#dependencies[parent dependencies of the RDD] and acts according to their type, i.e. ShuffleDependency or NarrowDependency.
NOTE: ShuffleDependency and NarrowDependency are the main top-level Dependencies.
For each NarrowDependency, getMissingParentStages simply marks the corresponding RDD to visit and moves on to a next dependency of a RDD or works on another unvisited parent RDD.
NOTE: NarrowDependency is a RDD dependency that allows for pipelined execution.
getMissingParentStages focuses on ShuffleDependency dependencies.
NOTE: ShuffleDependency is a RDD dependency that represents a dependency on the output of a ShuffleMapStage, i.e. shuffle map stage.
For each ShuffleDependency, getMissingParentStages finds ShuffleMapStage stages. If the ShuffleMapStage is not available, it is added to the set of missing (map) stages.
NOTE: A ShuffleMapStage is available when all its partitions are computed, i.e. results are available (as blocks).
CAUTION: FIXME...IMAGE with ShuffleDependencies queried
getMissingParentStages is used when DAGScheduler is requested to submit a stage and handle JobSubmitted and MapStageSubmitted events.
Submitting Missing Tasks of Stage¶
submitMissingTasks prints out the following DEBUG message to the logs:
submitMissingTasks requests the given Stage for the missing partitions (partitions that need to be computed).
submitMissingTasks adds the stage to the runningStages internal registry.
submitMissingTasks notifies the OutputCommitCoordinator that stage execution started.
submitMissingTasks determines preferred locations (task locality preferences) of the missing partitions.
submitMissingTasks requests the stage for a new stage attempt.
submitMissingTasks requests the LiveListenerBus to post a SparkListenerStageSubmitted event.
submitMissingTasks uses the closure Serializer to serialize the stage and create a so-called task binary. submitMissingTasks serializes the RDD (of the stage) and either the ShuffleDependency or the compute function based on the type of the stage (ShuffleMapStage or ResultStage, respectively).
submitMissingTasks creates a broadcast variable for the task binary.
Note
That shows how important broadcast variables are for Spark itself to distribute data among executors in a Spark application in the most efficient way.
submitMissingTasks creates tasks for every missing partition:
-
ResultTasks for a ResultStage
If there are tasks to submit for execution (i.e. there are missing partitions in the stage), submitMissingTasks prints out the following INFO message to the logs:
Submitting [size] missing tasks from [stage] ([rdd]) (first 15 tasks are for partitions [partitionIds])
submitMissingTasks requests the TaskScheduler to TaskScheduler.md#submitTasks[submit the tasks for execution] (as a new TaskSet.md[TaskSet]).
With no tasks to submit for execution, submitMissingTasks marks the stage as finished successfully.
submitMissingTasks prints out the following DEBUG messages based on the type of the stage:
Stage [stage] is actually done; (available: [isAvailable],available outputs: [numAvailableOutputs],partitions: [numPartitions])
or
for ShuffleMapStage and ResultStage, respectively.
In the end, with no tasks to submit for execution, submitMissingTasks submits waiting child stages for execution and exits.
submitMissingTasks is used when DAGScheduler is requested to submit a stage for execution.
Finding Preferred Locations for Missing Partitions¶
getPreferredLocs is simply an alias for the internal (recursive) getPreferredLocsInternal.
getPreferredLocs is used when:
SparkContextis requested to getPreferredLocsDAGScheduleris requested to submit the missing tasks of a stage
Finding BlockManagers (Executors) for Cached RDD Partitions (aka Block Location Discovery)¶
getCacheLocs gives TaskLocations (block locations) for the partitions of the input rdd. getCacheLocs caches lookup results in cacheLocs internal registry.
NOTE: The size of the collection from getCacheLocs is exactly the number of partitions in rdd RDD.
NOTE: The size of every TaskLocation collection (i.e. every entry in the result of getCacheLocs) is exactly the number of blocks managed using storage:BlockManager.md[BlockManagers] on executors.
Internally, getCacheLocs finds rdd in the cacheLocs internal registry (of partition locations per RDD).
If rdd is not in cacheLocs internal registry, getCacheLocs branches per its storage:StorageLevel.md[storage level].
For NONE storage level (i.e. no caching), the result is an empty locations (i.e. no location preference).
For other non-NONE storage levels, getCacheLocs storage:BlockManagerMaster.md#getLocations-block-array[requests BlockManagerMaster for block locations] that are then mapped to TaskLocations with the hostname of the owning BlockManager for a block (of a partition) and the executor id.
getCacheLocs records the computed block locations per partition (as TaskLocation) in cacheLocs internal registry.
NOTE: getCacheLocs requests locations from BlockManagerMaster using storage:BlockId.md#RDDBlockId[RDDBlockId] with the RDD id and the partition indices (which implies that the order of the partitions matters to request proper blocks).
NOTE: DAGScheduler uses TaskLocation.md[TaskLocations] (with host and executor) while storage:BlockManagerMaster.md[BlockManagerMaster] uses storage:BlockManagerId.md[] (to track similar information, i.e. block locations).
getCacheLocs is used when DAGScheduler is requested to find missing parent MapStages and getPreferredLocsInternal.
Finding Placement Preferences for RDD Partition (recursively)¶
getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation]
getPreferredLocsInternal first finds the TaskLocations for the partition of the rdd (using cacheLocs internal cache) and returns them.
Otherwise, if not found, getPreferredLocsInternal rdd/index.md#preferredLocations[requests rdd for the preferred locations of partition] and returns them.
NOTE: Preferred locations of the partitions of a RDD are also called placement preferences or locality preferences.
Otherwise, if not found, getPreferredLocsInternal finds the first parent NarrowDependency and (recursively) finds TaskLocations.
If all the attempts fail to yield any non-empty result, getPreferredLocsInternal returns an empty collection of TaskLocation.md[TaskLocations].
getPreferredLocsInternal is used when DAGScheduler is requested for the preferred locations for missing partitions.
Stopping DAGScheduler¶
stop stops the internal dag-scheduler-message thread pool, dag-scheduler-event-loop, and TaskScheduler.
stop is used when SparkContext is requested to stop.
Killing Task¶
killTaskAttempt requests the TaskScheduler to kill a task.
killTaskAttempt is used when SparkContext is requested to kill a task.
cleanUpAfterSchedulerStop¶
cleanUpAfterSchedulerStop...FIXME
cleanUpAfterSchedulerStop is used when DAGSchedulerEventProcessLoop is requested to onStop.
removeExecutorAndUnregisterOutputs¶
removeExecutorAndUnregisterOutputs(
execId: String,
fileLost: Boolean,
hostToUnregisterOutputs: Option[String],
maybeEpoch: Option[Long] = None): Unit
removeExecutorAndUnregisterOutputs...FIXME
removeExecutorAndUnregisterOutputs is used when DAGScheduler is requested to handle task completion (due to a fetch failure) and executor lost events.
markMapStageJobsAsFinished¶
markMapStageJobsAsFinished checks out whether the given ShuffleMapStage is fully-available yet there are still map-stage jobs running.
If so, markMapStageJobsAsFinished requests the MapOutputTrackerMaster for the statistics (for the ShuffleDependency of the given ShuffleMapStage).
For every map-stage job, markMapStageJobsAsFinished marks the map-stage job as finished (with the statistics).
markMapStageJobsAsFinished is used when:
DAGScheduleris requested to submit missing tasks (of aShuffleMapStagethat has just been computed) and processShuffleMapStageCompletion
processShuffleMapStageCompletion¶
processShuffleMapStageCompletion...FIXME
processShuffleMapStageCompletion is used when:
DAGScheduleris requested to handleTaskCompletion and handleShuffleMergeFinalized
handleShuffleMergeFinalized¶
handleShuffleMergeFinalized...FIXME
handleShuffleMergeFinalized is used when:
DAGSchedulerEventProcessLoopis requested to handle a ShuffleMergeFinalized event
scheduleShuffleMergeFinalize¶
scheduleShuffleMergeFinalize...FIXME
scheduleShuffleMergeFinalize is used when:
DAGScheduleris requested to handle a task completion
finalizeShuffleMerge¶
finalizeShuffleMerge...FIXME
updateJobIdStageIdMaps¶
updateJobIdStageIdMaps...FIXME
updateJobIdStageIdMaps is used when DAGScheduler is requested to create ShuffleMapStage and ResultStage stages.
executorHeartbeatReceived¶
executorHeartbeatReceived(
execId: String,
// (taskId, stageId, stageAttemptId, accumUpdates)
accumUpdates: Array[(Long, Int, Int, Seq[AccumulableInfo])],
blockManagerId: BlockManagerId,
// (stageId, stageAttemptId) -> metrics
executorUpdates: mutable.Map[(Int, Int), ExecutorMetrics]): Boolean
executorHeartbeatReceived posts a SparkListenerExecutorMetricsUpdate (to listenerBus) and informs BlockManagerMaster that blockManagerId block manager is alive (by posting BlockManagerHeartbeat).
executorHeartbeatReceived is used when TaskSchedulerImpl is requested to handle an executor heartbeat.
Event Handlers¶
AllJobsCancelled Event Handler¶
doCancelAllJobs...FIXME
doCancelAllJobs is used when DAGSchedulerEventProcessLoop is requested to handle an AllJobsCancelled event and onError.
BeginEvent Event Handler¶
handleBeginEvent...FIXME
handleBeginEvent is used when DAGSchedulerEventProcessLoop is requested to handle a BeginEvent event.
Handling Task Completion Event¶
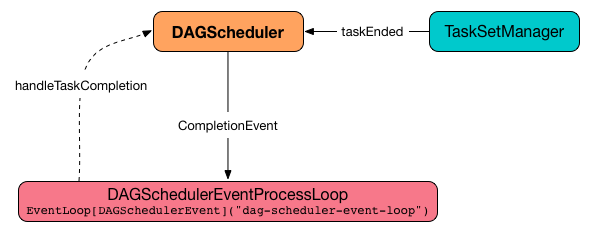
handleTaskCompletion handles a CompletionEvent.
handleTaskCompletion notifies the OutputCommitCoordinator that a task completed.
handleTaskCompletion finds the stage in the stageIdToStage registry. If not found, handleTaskCompletion postTaskEnd and quits.
handleTaskCompletion updateAccumulators.
handleTaskCompletion announces task completion application-wide.
handleTaskCompletion branches off per TaskEndReason (as event.reason).
| TaskEndReason | Description |
|---|---|
| Success | Acts according to the type of the task that completed, i.e. ShuffleMapTask and ResultTask |
| Resubmitted | |
| others |
Handling Successful Task Completion¶
When a task has finished successfully (i.e. Success end reason), handleTaskCompletion marks the partition as no longer pending (i.e. the partition the task worked on is removed from pendingPartitions of the stage).
NOTE: A Stage tracks its own pending partitions using scheduler:Stage.md#pendingPartitions[pendingPartitions property].
handleTaskCompletion branches off given the type of the task that completed, i.e. ShuffleMapTask and ResultTask.
Handling Successful ResultTask Completion¶
For scheduler:ResultTask.md[ResultTask], the stage is assumed a scheduler:ResultStage.md[ResultStage].
handleTaskCompletion finds the ActiveJob associated with the ResultStage.
NOTE: scheduler:ResultStage.md[ResultStage] tracks the optional ActiveJob as scheduler:ResultStage.md#activeJob[activeJob property]. There could only be one active job for a ResultStage.
If there is no job for the ResultStage, you should see the following INFO message in the logs:
Otherwise, when the ResultStage has a ActiveJob, handleTaskCompletion checks the status of the partition output for the partition the ResultTask ran for.
NOTE: ActiveJob tracks task completions in finished property with flags for every partition in a stage. When the flag for a partition is enabled (i.e. true), it is assumed that the partition has been computed (and no results from any ResultTask are expected and hence simply ignored).
CAUTION: FIXME Describe why could a partition has more ResultTask running.
handleTaskCompletion ignores the CompletionEvent when the partition has already been marked as completed for the stage and simply exits.
handleTaskCompletion scheduler:DAGScheduler.md#updateAccumulators[updates accumulators].
The partition for the ActiveJob (of the ResultStage) is marked as computed and the number of partitions calculated increased.
NOTE: ActiveJob tracks what partitions have already been computed and their number.
If the ActiveJob has finished (when the number of partitions computed is exactly the number of partitions in a stage) handleTaskCompletion does the following (in order):
- scheduler:DAGScheduler.md#markStageAsFinished[Marks
ResultStagecomputed]. - scheduler:DAGScheduler.md#cleanupStateForJobAndIndependentStages[Cleans up after
ActiveJoband independent stages]. - Announces the job completion application-wide (by posting a SparkListener.md#SparkListenerJobEnd[SparkListenerJobEnd] to scheduler:LiveListenerBus.md[]).
In the end, handleTaskCompletion notifies JobListener of the ActiveJob that the task succeeded.
NOTE: A task succeeded notification holds the output index and the result.
When the notification throws an exception (because it runs user code), handleTaskCompletion notifies JobListener about the failure (wrapping it inside a SparkDriverExecutionException exception).
Handling Successful ShuffleMapTask Completion¶
For scheduler:ShuffleMapTask.md[ShuffleMapTask], the stage is assumed a scheduler:ShuffleMapStage.md[ShuffleMapStage].
handleTaskCompletion scheduler:DAGScheduler.md#updateAccumulators[updates accumulators].
The task's result is assumed scheduler:MapStatus.md[MapStatus] that knows the executor where the task has finished.
You should see the following DEBUG message in the logs:
If the executor is registered in scheduler:DAGScheduler.md#failedEpoch[failedEpoch internal registry] and the epoch of the completed task is not greater than that of the executor (as in failedEpoch registry), you should see the following INFO message in the logs:
Otherwise, handleTaskCompletion scheduler:ShuffleMapStage.md#addOutputLoc[registers the MapStatus result for the partition with the stage] (of the completed task).
handleTaskCompletion does more processing only if the ShuffleMapStage is registered as still running (in scheduler:DAGScheduler.md#runningStages[runningStages internal registry]) and the scheduler:Stage.md#pendingPartitions[ShuffleMapStage stage has no pending partitions to compute].
The ShuffleMapStage is marked as finished.
You should see the following INFO messages in the logs:
looking for newly runnable stages
running: [runningStages]
waiting: [waitingStages]
failed: [failedStages]
handleTaskCompletion scheduler:MapOutputTrackerMaster.md#registerMapOutputs[registers the shuffle map outputs of the ShuffleDependency with MapOutputTrackerMaster] (with the epoch incremented) and scheduler:DAGScheduler.md#clearCacheLocs[clears internal cache of the stage's RDD block locations].
NOTE: scheduler:MapOutputTrackerMaster.md[MapOutputTrackerMaster] is given when scheduler:DAGScheduler.md#creating-instance[DAGScheduler is created].
If the scheduler:ShuffleMapStage.md#isAvailable[ShuffleMapStage stage is ready], all scheduler:ShuffleMapStage.md#mapStageJobs[active jobs of the stage] (aka map-stage jobs) are scheduler:DAGScheduler.md#markMapStageJobAsFinished[marked as finished] (with scheduler:MapOutputTrackerMaster.md#getStatistics[MapOutputStatistics from MapOutputTrackerMaster for the ShuffleDependency]).
NOTE: A ShuffleMapStage stage is ready (aka available) when all partitions have shuffle outputs, i.e. when their tasks have completed.
Eventually, handleTaskCompletion scheduler:DAGScheduler.md#submitWaitingChildStages[submits waiting child stages (of the ready ShuffleMapStage)].
If however the ShuffleMapStage is not ready, you should see the following INFO message in the logs:
Resubmitting [shuffleStage] ([shuffleStage.name]) because some of its tasks had failed: [missingPartitions]
In the end, handleTaskCompletion scheduler:DAGScheduler.md#submitStage[submits the ShuffleMapStage for execution].
TaskEndReason: Resubmitted¶
For Resubmitted case, you should see the following INFO message in the logs:
The task (by task.partitionId) is added to the collection of pending partitions of the stage (using stage.pendingPartitions).
TIP: A stage knows how many partitions are yet to be calculated. A task knows about the partition id for which it was launched.
Task Failed with FetchFailed Exception¶
FetchFailed(
bmAddress: BlockManagerId,
shuffleId: Int,
mapId: Int,
reduceId: Int,
message: String)
extends TaskFailedReason
When FetchFailed happens, stageIdToStage is used to access the failed stage (using task.stageId and the task is available in event in handleTaskCompletion(event: CompletionEvent)). shuffleToMapStage is used to access the map stage (using shuffleId).
If failedStage.latestInfo.attemptId != task.stageAttemptId, you should see the following INFO in the logs:
Ignoring fetch failure from [task] as it's from [failedStage] attempt [task.stageAttemptId] and there is a more recent attempt for that stage (attempt ID [failedStage.latestInfo.attemptId]) running
CAUTION: FIXME What does failedStage.latestInfo.attemptId != task.stageAttemptId mean?
And the case finishes. Otherwise, the case continues.
If the failed stage is in runningStages, the following INFO message shows in the logs:
Marking [failedStage] ([failedStage.name]) as failed due to a fetch failure from [mapStage] ([mapStage.name])
markStageAsFinished(failedStage, Some(failureMessage)) is called.
CAUTION: FIXME What does markStageAsFinished do?
If the failed stage is not in runningStages, the following DEBUG message shows in the logs:
When disallowStageRetryForTest is set, abortStage(failedStage, "Fetch failure will not retry stage due to testing config", None) is called.
CAUTION: FIXME Describe disallowStageRetryForTest and abortStage.
If the scheduler:Stage.md#failedOnFetchAndShouldAbort[number of fetch failed attempts for the stage exceeds the allowed number], the scheduler:DAGScheduler.md#abortStage[failed stage is aborted] with the reason:
[failedStage] ([name]) has failed the maximum allowable number of times: 4. Most recent failure reason: [failureMessage]
If there are no failed stages reported (scheduler:DAGScheduler.md#failedStages[DAGScheduler.failedStages] is empty), the following INFO shows in the logs:
Resubmitting [mapStage] ([mapStage.name]) and [failedStage] ([failedStage.name]) due to fetch failure
And the following code is executed:
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(ResubmitFailedStages)
}, DAGScheduler.RESUBMIT_TIMEOUT, TimeUnit.MILLISECONDS)
CAUTION: FIXME What does the above code do?
For all the cases, the failed stage and map stages are both added to the internal scheduler:DAGScheduler.md#failedStages[registry of failed stages].
If mapId (in the FetchFailed object for the case) is provided, the map stage output is cleaned up (as it is broken) using mapStage.removeOutputLoc(mapId, bmAddress) and scheduler:MapOutputTracker.md#unregisterMapOutput[MapOutputTrackerMaster.unregisterMapOutput(shuffleId, mapId, bmAddress)] methods.
CAUTION: FIXME What does mapStage.removeOutputLoc do?
If BlockManagerId (as bmAddress in the FetchFailed object) is defined, handleTaskCompletion notifies DAGScheduler that an executor was lost (with filesLost enabled and maybeEpoch from the scheduler:Task.md#epoch[Task] that completed).
handleTaskCompletion is used when:
- DAGSchedulerEventProcessLoop is requested to handle a CompletionEvent event.
ExecutorAdded Event Handler¶
handleExecutorAdded...FIXME
handleExecutorAdded is used when DAGSchedulerEventProcessLoop is requested to handle an ExecutorAdded event.
ExecutorLost Event Handler¶
handleExecutorLost checks whether the input optional maybeEpoch is defined and if not requests the scheduler:MapOutputTracker.md#getEpoch[current epoch from MapOutputTrackerMaster].
NOTE: MapOutputTrackerMaster is passed in (as mapOutputTracker) when scheduler:DAGScheduler.md#creating-instance[DAGScheduler is created].
CAUTION: FIXME When is maybeEpoch passed in?
.DAGScheduler.handleExecutorLost image::dagscheduler-handleExecutorLost.png[align="center"]
Recurring ExecutorLost events lead to the following repeating DEBUG message in the logs:
NOTE: handleExecutorLost handler uses DAGScheduler's failedEpoch and FIXME internal registries.
Otherwise, when the executor execId is not in the scheduler:DAGScheduler.md#failedEpoch[list of executor lost] or the executor failure's epoch is smaller than the input maybeEpoch, the executor's lost event is recorded in scheduler:DAGScheduler.md#failedEpoch[failedEpoch internal registry].
CAUTION: FIXME Describe the case above in simpler non-technical words. Perhaps change the order, too.
You should see the following INFO message in the logs:
storage:BlockManagerMaster.md#removeExecutor[BlockManagerMaster is requested to remove the lost executor execId].
CAUTION: FIXME Review what's filesLost.
handleExecutorLost exits unless the ExecutorLost event was for a map output fetch operation (and the input filesLost is true) or external shuffle service is not used.
In such a case, you should see the following INFO message in the logs:
handleExecutorLost walks over all scheduler:ShuffleMapStage.md[ShuffleMapStage]s in scheduler:DAGScheduler.md#shuffleToMapStage[DAGScheduler's shuffleToMapStage internal registry] and do the following (in order):
ShuffleMapStage.removeOutputsOnExecutor(execId)is called- scheduler:MapOutputTrackerMaster.md#registerMapOutputs[MapOutputTrackerMaster.registerMapOutputs(shuffleId, stage.outputLocInMapOutputTrackerFormat(), changeEpoch = true)] is called.
In case scheduler:DAGScheduler.md#shuffleToMapStage[DAGScheduler's shuffleToMapStage internal registry] has no shuffles registered, scheduler:MapOutputTrackerMaster.md#incrementEpoch[MapOutputTrackerMaster is requested to increment epoch].
Ultimatelly, DAGScheduler scheduler:DAGScheduler.md#clearCacheLocs[clears the internal cache of RDD partition locations].
handleExecutorLost is used when DAGSchedulerEventProcessLoop is requested to handle an ExecutorLost event.
GettingResultEvent Event Handler¶
handleGetTaskResult...FIXME
handleGetTaskResult is used when DAGSchedulerEventProcessLoop is requested to handle a GettingResultEvent event.
JobCancelled Event Handler¶
handleJobCancellation looks up the active job for the input job ID (in jobIdToActiveJob internal registry) and fails it and all associated independent stages with failure reason:
When the input job ID is not found, handleJobCancellation prints out the following DEBUG message to the logs:
handleJobCancellation is used when DAGScheduler is requested to handle a JobCancelled event, doCancelAllJobs, handleJobGroupCancelled, handleStageCancellation.
JobGroupCancelled Event Handler¶
handleJobGroupCancelled finds active jobs in a group and cancels them.
Internally, handleJobGroupCancelled computes all the active jobs (registered in the internal collection of active jobs) that have spark.jobGroup.id scheduling property set to groupId.
handleJobGroupCancelled then cancels every active job in the group one by one and the cancellation reason:
handleJobGroupCancelled is used when DAGScheduler is requested to handle JobGroupCancelled event.
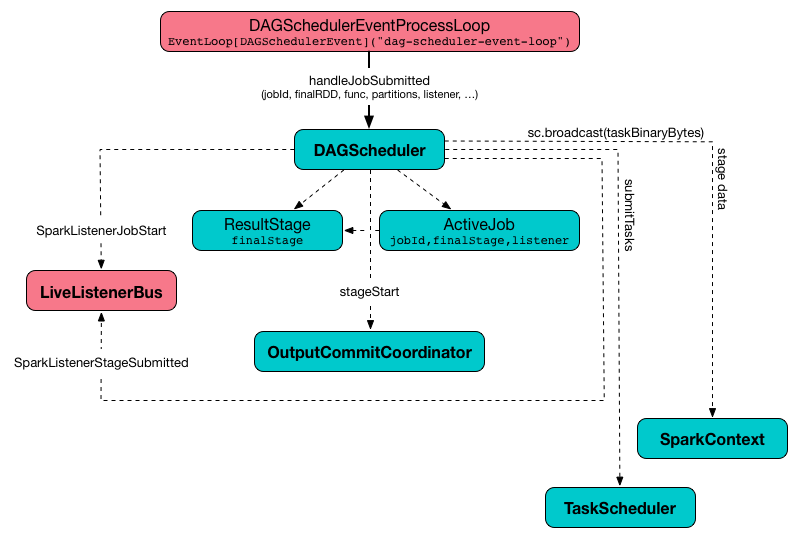
Handling JobSubmitted Event¶
handleJobSubmitted(
jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit
handleJobSubmitted creates a ResultStage (finalStage) for the given RDD, func, partitions, jobId and callSite.
BarrierJobSlotsNumberCheckFailed Exception
Creating a ResultStage may fail with a BarrierJobSlotsNumberCheckFailed exception.
handleJobSubmitted removes the given jobId from the barrierJobIdToNumTasksCheckFailures.
handleJobSubmitted creates an ActiveJob for the ResultStage (with the given jobId, the callSite, the JobListener and the properties).
handleJobSubmitted clears the internal cache of RDD partition locations.
FIXME Why is this clearing here so important?
handleJobSubmitted prints out the following INFO messages to the logs (with missingParentStages):
Got job [id] ([callSite]) with [number] output partitions
Final stage: [finalStage] ([name])
Parents of final stage: [parents]
Missing parents: [missingParentStages]
handleJobSubmitted registers the new ActiveJob in jobIdToActiveJob and activeJobs internal registries.
handleJobSubmitted requests the ResultStage to associate itself with the ActiveJob.
handleJobSubmitted uses the jobIdToStageIds internal registry to find all registered stages for the given jobId. handleJobSubmitted uses the stageIdToStage internal registry to request the Stages for the latestInfo.
In the end, handleJobSubmitted posts a SparkListenerJobStart message to the LiveListenerBus and submits the ResultStage.
handleJobSubmitted is used when:
DAGSchedulerEventProcessLoopis requested to handle a JobSubmitted event
BarrierJobSlotsNumberCheckFailed¶
In case of a BarrierJobSlotsNumberCheckFailed exception while creating a ResultStage, handleJobSubmitted increments the number of failures in the barrierJobIdToNumTasksCheckFailures for the given jobId.
handleJobSubmitted prints out the following WARN message to the logs (with spark.scheduler.barrier.maxConcurrentTasksCheck.maxFailures):
Barrier stage in job [jobId] requires [requiredConcurrentTasks] slots, but only [maxConcurrentTasks] are available. Will retry up to [maxFailures] more times
If the number of failures is below the spark.scheduler.barrier.maxConcurrentTasksCheck.maxFailures threshold, handleJobSubmitted requests the messageScheduler to schedule a one-shot task that requests the DAGSchedulerEventProcessLoop to post a JobSubmitted event (after spark.scheduler.barrier.maxConcurrentTasksCheck.interval seconds).
Note
Posting a JobSubmitted event is to request the DAGScheduler to re-consider the request, hoping that there will be enough resources to fulfill the resource requirements of a barrier job.
Otherwise, if the number of failures crossed the spark.scheduler.barrier.maxConcurrentTasksCheck.maxFailures threshold, handleJobSubmitted removes the jobId from the barrierJobIdToNumTasksCheckFailures and informs the given JobListener that the jobFailed.
MapStageSubmitted¶
handleMapStageSubmitted(
jobId: Int,
dependency: ShuffleDependency[_, _, _],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit

Note
MapStageSubmitted event processing is very similar to JobSubmitted event's.
handleMapStageSubmitted finds or creates a new ShuffleMapStage for the given ShuffleDependency and jobId.
handleMapStageSubmitted creates an ActiveJob (with the given jobId, the ShuffleMapStage, the given JobListener).
handleMapStageSubmitted clears the internal cache of RDD partition locations.
handleMapStageSubmitted prints out the following INFO messages to the logs:
Got map stage job [id] ([callSite]) with [number] output partitions
Final stage: [stage] ([name])
Parents of final stage: [parents]
Missing parents: [missingParentStages]
handleMapStageSubmitted adds the new ActiveJob to jobIdToActiveJob and activeJobs internal registries, and the ShuffleMapStage.
Note
ShuffleMapStage can have multiple ActiveJobs registered.
handleMapStageSubmitted finds all the registered stages for the input jobId and collects their latest StageInfo.
In the end, handleMapStageSubmitted posts a SparkListenerJobStart event to the LiveListenerBus and submits the ShuffleMapStage.
When the ShuffleMapStage is available already, handleMapStageSubmitted marks the job finished.
When handleMapStageSubmitted could not find or create a ShuffleMapStage, handleMapStageSubmitted prints out the following WARN message to the logs.
handleMapStageSubmitted notifies the JobListener about the job failure and exits.
handleMapStageSubmitted is used when:
- DAGSchedulerEventProcessLoop is requested to handle a MapStageSubmitted event
ResubmitFailedStages Event Handler¶
resubmitFailedStages iterates over the internal collection of failed stages and submits them.
Note
resubmitFailedStages does nothing when there are no failed stages reported.
resubmitFailedStages prints out the following INFO message to the logs:
resubmitFailedStages clears the internal cache of RDD partition locations and makes a copy of the collection of failed stages to track failed stages afresh.
Note
At this point DAGScheduler has no failed stages reported.
The previously-reported failed stages are sorted by the corresponding job ids in incremental order and resubmitted.
resubmitFailedStages is used when DAGSchedulerEventProcessLoop is requested to handle a ResubmitFailedStages event.
SpeculativeTaskSubmitted Event Handler¶
handleSpeculativeTaskSubmitted...FIXME
handleSpeculativeTaskSubmitted is used when DAGSchedulerEventProcessLoop is requested to handle a SpeculativeTaskSubmitted event.
StageCancelled Event Handler¶
handleStageCancellation...FIXME
handleStageCancellation is used when DAGSchedulerEventProcessLoop is requested to handle a StageCancelled event.
TaskSetFailed Event Handler¶
handleTaskSetFailed...FIXME
handleTaskSetFailed is used when DAGSchedulerEventProcessLoop is requested to handle a TaskSetFailed event.
WorkerRemoved Event Handler¶
handleWorkerRemoved...FIXME
handleWorkerRemoved is used when DAGSchedulerEventProcessLoop is requested to handle a WorkerRemoved event.
Internal Properties¶
failedEpoch¶
The lookup table of lost executors and the epoch of the event.
failedStages¶
Stages that failed due to fetch failures (when a DAGSchedulerEventProcessLoop.md#handleTaskCompletion-FetchFailed[task fails with FetchFailed exception]).
jobIdToActiveJob¶
The lookup table of ActiveJobs per job id.
jobIdToStageIds¶
The lookup table of all stages per ActiveJob id
nextJobId Counter¶
nextJobId is a Java AtomicInteger for job IDs.
nextJobId starts at 0.
Used when DAGScheduler is requested for numTotalJobs, to submitJob, runApproximateJob and submitMapStage.
nextStageId¶
The next stage id counting from 0.
Used when DAGScheduler creates a shuffle map stage and a result stage. It is the key in stageIdToStage.
runningStages¶
The set of stages that are currently "running".
A stage is added when submitMissingTasks gets executed (without first checking if the stage has not already been added).
shuffleIdToMapStage¶
A lookup table of ShuffleMapStages by ShuffleDependency
stageIdToStage¶
A lookup table of stages by stage ID
Used when DAGScheduler creates a shuffle map stage, creates a result stage, cleans up job state and independent stages, is informed that a task is started, a taskset has failed, a job is submitted (to compute a ResultStage), a map stage was submitted, a task has completed or a stage was cancelled, updates accumulators, aborts a stage and fails a job and independent stages.
waitingStages¶
Stages with parents to be computed
Event Posting Methods¶
Posting AllJobsCancelled¶
Posts an AllJobsCancelled
Used when SparkContext is requested to cancel all running or scheduled Spark jobs
Posting JobCancelled¶
Posts a JobCancelled
Used when SparkContext or JobWaiter are requested to cancel a Spark job
Posting JobGroupCancelled¶
Posts a JobGroupCancelled
Used when SparkContext is requested to cancel a job group
Posting StageCancelled¶
Posts a StageCancelled
Used when SparkContext is requested to cancel a stage
Posting ExecutorAdded¶
Posts an ExecutorAdded
Used when TaskSchedulerImpl is requested to handle resource offers (and a new executor is found in the resource offers)
Posting ExecutorLost¶
Posts a ExecutorLost
Used when TaskSchedulerImpl is requested to handle a task status update (and a task gets lost which is used to indicate that the executor got broken and hence should be considered lost) or executorLost
Posting JobSubmitted¶
Posts a JobSubmitted
Used when SparkContext is requested to run an approximate job
Posting SpeculativeTaskSubmitted¶
Posts a SpeculativeTaskSubmitted
Used when TaskSetManager is requested to checkAndSubmitSpeculatableTask
Posting CompletionEvent¶
Posts a CompletionEvent
Used when TaskSetManager is requested to handleSuccessfulTask, handleFailedTask, and executorLost
Posting GettingResultEvent¶
Posts a GettingResultEvent
Used when TaskSetManager is requested to handle a task fetching result
Posting TaskSetFailed¶
Posts a TaskSetFailed
Used when TaskSetManager is requested to abort
Posting BeginEvent¶
Posts a BeginEvent
Used when TaskSetManager is requested to start a task
Posting WorkerRemoved¶
Posts a WorkerRemoved
Used when TaskSchedulerImpl is requested to handle a removed worker event
Updating Accumulators of Completed Tasks¶
updateAccumulators merges the partial values of accumulators from a completed task (based on the given CompletionEvent) into their "source" accumulators on the driver.
For every AccumulatorV2 update (in the given CompletionEvent), updateAccumulators finds the corresponding accumulator on the driver and requests the AccumulatorV2 to merge the updates.
updateAccumulators...FIXME
For named accumulators with the update value being a non-zero value, i.e. not Accumulable.zero:
stage.latestInfo.accumulablesfor theAccumulableInfo.idis setCompletionEvent.taskInfo.accumulableshas a new AccumulableInfo added.
CAUTION: FIXME Where are Stage.latestInfo.accumulables and CompletionEvent.taskInfo.accumulables used?
updateAccumulators is used when DAGScheduler is requested to handle a task completion.
Posting SparkListenerTaskEnd (at Task Completion)¶
postTaskEnd reconstructs task metrics (from the accumulator updates in the CompletionEvent).
In the end, postTaskEnd creates a SparkListenerTaskEnd and requests the LiveListenerBus to post it.
postTaskEnd is used when:
DAGScheduleris requested to handle a task completion
checkBarrierStageWithNumSlots¶
Noop for Non-Barrier RDDs
Unless the given RDD is isBarrier, checkBarrierStageWithNumSlots does nothing (is a noop).
checkBarrierStageWithNumSlots requests the given RDD for the number of partitions.
checkBarrierStageWithNumSlots requests the SparkContext for the maximum number of concurrent tasks for the given ResourceProfile.
If the number of partitions (based on the RDD) is greater than the maximum number of concurrent tasks (based on the ResourceProfile), checkBarrierStageWithNumSlots reports a BarrierJobSlotsNumberCheckFailed exception.
checkBarrierStageWithNumSlots is used when:
DAGScheduleris requested to create a ShuffleMapStage or a ResultStage stage
Utilities¶
Danger
The section includes (hides) utility methods that do not really contribute to the understanding of how DAGScheduler works internally.
It's very likely they should not even be part of this page.
Finding Shuffle Dependencies and ResourceProfiles of RDD¶
getShuffleDependenciesAndResourceProfiles(
rdd: RDD[_]): (HashSet[ShuffleDependency[_, _, _]], HashSet[ResourceProfile])
getShuffleDependenciesAndResourceProfiles returns the direct ShuffleDependencies and all the ResourceProfiles of the given RDD and parent non-shuffle RDDs, if available.
getShuffleDependenciesAndResourceProfiles collects ResourceProfiles of the given RDD and any parent RDDs, if available.
getShuffleDependenciesAndResourceProfiles collects direct ShuffleDependencies of the given RDD and any parent RDDs of non-ShuffleDependencyies, if available.
getShuffleDependenciesAndResourceProfiles is used when:
DAGScheduleris requested to create a ShuffleMapStage and a ResultStage, and for the missing ShuffleDependencies of a RDD
Logging¶
Enable ALL logging level for org.apache.spark.scheduler.DAGScheduler logger to see what happens inside.
Add the following line to conf/log4j2.properties:
Refer to Logging.