Spark Scheduler¶
Spark Scheduler is a core component of Apache Spark that is responsible for scheduling tasks for execution.
Spark Scheduler uses the high-level stage-oriented DAGScheduler and the low-level task-oriented TaskScheduler.
Stage Execution¶
Every partition of a Stage is transformed into a Task (ShuffleMapTask or ResultTask for ShuffleMapStage and ResultStage, respectively).
Submitting a stage can therefore trigger execution of a series of dependent parent stages.

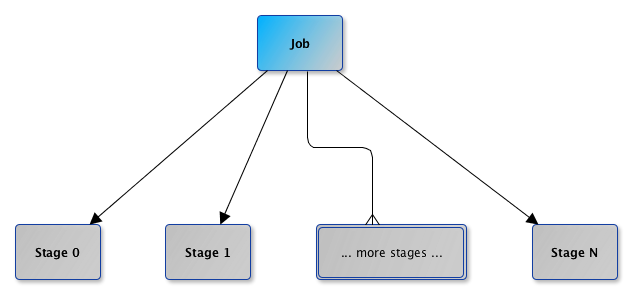
When a Spark job is submitted, a new stage is created (they can be created from scratch or linked to, i.e. shared, if other jobs use them already).
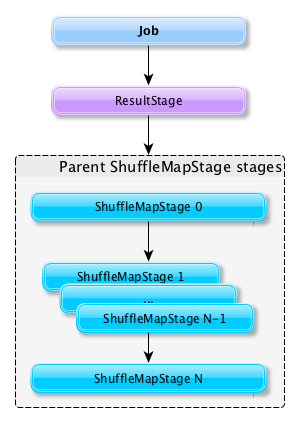
DAGScheduler splits up a job into a collection of Stages. A Stage contains a sequence of narrow transformations that can be completed without shuffling data set, separated at shuffle boundaries (where shuffle occurs). Stages are thus a result of breaking the RDD graph at shuffle boundaries.
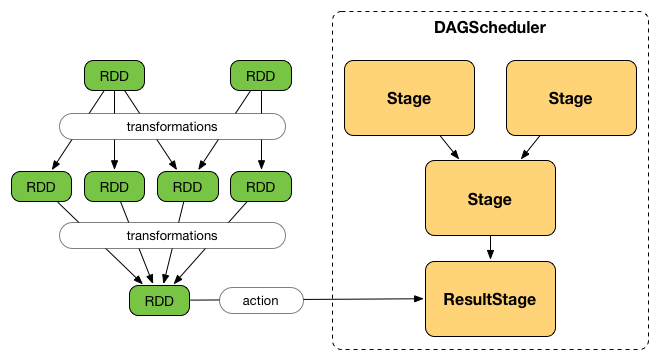
Shuffle boundaries introduce a barrier where stages/tasks must wait for the previous stage to finish before they fetch map outputs.
Resources¶
- Deep Dive into the Apache Spark Scheduler by Xingbo Jiang (Databricks)