Resilient Distributed Dataset (RDD)¶
Resilient Distributed Dataset (aka RDD) is the primary data abstraction in Apache Spark and the core of Spark (that I often refer to as Spark Core).
The origins of RDD
The original paper that gave birth to the concept of RDD is Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing by Matei Zaharia, et al.
Read the paper and skip the rest of this page. You'll save a great deal of your precious time 😎
An RDD is a description of a fault-tolerant and resilient computation over a distributed collection of records (spread over one or many partitions).
RDDs and Scala Collections
RDDs are like Scala collections, and they only differ by their distribution, i.e. a RDD is computed on many JVMs while a Scala collection lives on a single JVM.
Using RDD Spark hides data partitioning and so distribution that in turn allowed them to design parallel computational framework with a higher-level programming interface (API) for four mainstream programming languages.
The features of RDDs (decomposing the name):
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures.
- Distributed with data residing on multiple nodes in a Spark cluster
- Dataset is a collection of partitioned data with primitive values or values of values, e.g. tuples or other objects (that represent records of the data you work with).
From the scaladoc of org.apache.spark.rdd.RDD:
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
From the original paper about RDD - Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing:
Resilient Distributed Datasets (RDDs) are a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
Beside the above traits (that are directly embedded in the name of the data abstraction - RDD) it has the following additional traits:
- In-Memory, i.e. data inside RDD is stored in memory as much (size) and long (time) as possible.
- Immutable or Read-Only, i.e. it does not change once created and can only be transformed using transformations to new RDDs.
- Lazy evaluated, i.e. the data inside RDD is not available or transformed until an action is executed that triggers the execution.
- Cacheable, i.e. you can hold all the data in a persistent "storage" like memory (default and the most preferred) or disk (the least preferred due to access speed).
- Parallel, i.e. process data in parallel.
- Typed -- RDD records have types, e.g.
LonginRDD[Long]or(Int, String)inRDD[(Int, String)]. - Partitioned -- records are partitioned (split into logical partitions) and distributed across nodes in a cluster.
- Location-Stickiness --
RDDcan define <
Note
Preferred location (aka locality preferences or placement preferences or locality info) is information about the locations of RDD records (that Spark's DAGScheduler uses to place computing partitions on to have the tasks as close to the data as possible).
Computing partitions in a RDD is a distributed process by design and to achieve even data distribution as well as leverage data locality (in distributed systems like HDFS or Apache Kafka in which data is partitioned by default), they are partitioned to a fixed number of partitions - logical chunks (parts) of data. The logical division is for processing only and internally it is not divided whatsoever. Each partition comprises of records.
Partitions are the units of parallelism. You can control the number of partitions of a RDD using RDD.repartition or RDD.coalesce transformations. Spark tries to be as close to data as possible without wasting time to send data across network by means of RDD shuffling, and creates as many partitions as required to follow the storage layout and thus optimize data access. It leads to a one-to-one mapping between (physical) data in distributed data storage (e.g., HDFS or Cassandra) and partitions.
RDDs support two kinds of operations:
- transformations - lazy operations that return another RDD.
- actions - operations that trigger computation and return values.
The motivation to create RDD were (after the authors) two types of applications that current computing frameworks handle inefficiently:
- iterative algorithms in machine learning and graph computations
- interactive data mining tools as ad-hoc queries on the same dataset
The goal is to reuse intermediate in-memory results across multiple data-intensive workloads with no need for copying large amounts of data over the network.
Technically, RDDs follow the contract defined by the five main intrinsic properties:
- Parent RDDs (aka RDD dependencies)
- An array of partitions that a dataset is divided to
- A compute function to do a computation on partitions
- An optional Partitioner that defines how keys are hashed, and the pairs partitioned (for key-value RDDs)
- Optional preferred locations (aka locality info), i.e. hosts for a partition where the records live or are the closest to read from
This RDD abstraction supports an expressive set of operations without having to modify scheduler for each one.
An RDD is a named (by name) and uniquely identified (by id) entity in a SparkContext (available as context property).
RDDs live in one and only one SparkContext that creates a logical boundary.
Note
RDDs cannot be shared between SparkContexts.
An RDD can optionally have a friendly name accessible using name that can be changed using =:
scala> val ns = sc.parallelize(0 to 10)
ns: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> ns.id
res0: Int = 2
scala> ns.name
res1: String = null
scala> ns.name = "Friendly name"
ns.name: String = Friendly name
scala> ns.name
res2: String = Friendly name
scala> ns.toDebugString
res3: String = (8) Friendly name ParallelCollectionRDD[2] at parallelize at <console>:24 []
RDDs are a container of instructions on how to materialize big (arrays of) distributed data, and how to split it into partitions so Spark (using executors) can hold some of them.
In general data distribution can help executing processing in parallel so a task processes a chunk of data that it could eventually keep in memory.
Spark does jobs in parallel, and RDDs are split into partitions to be processed and written in parallel. Inside a partition, data is processed sequentially.
Saving partitions results in part-files instead of one single file (unless there is a single partition).
Transformations¶
A transformation is a lazy operation on a RDD that returns another RDD (e.g., map, flatMap, filter, reduceByKey, join, cogroup, etc.)
Learn more in Transformations.
Actions¶
An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver - the user program).
Learn more in Actions.
Creating RDDs¶
SparkContext.parallelize¶
One way to create a RDD is with SparkContext.parallelize method. It accepts a collection of elements as shown below (sc is a SparkContext instance):
scala> val rdd = sc.parallelize(1 to 1000)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25
You may also want to randomize the sample data:
scala> val data = Seq.fill(10)(util.Random.nextInt)
data: Seq[Int] = List(-964985204, 1662791, -1820544313, -383666422, -111039198, 310967683, 1114081267, 1244509086, 1797452433, 124035586)
scala> val rdd = sc.parallelize(data)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:29
Given the reason to use Spark to process more data than your own laptop could handle, SparkContext.parallelize is mainly used to learn Spark in the Spark shell.
SparkContext.parallelize requires all the data to be available on a single machine - the Spark driver - that eventually hits the limits of your laptop.
SparkContext.makeRDD¶
scala> sc.makeRDD(0 to 1000)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:25
SparkContext.textFile¶
One of the easiest ways to create an RDD is to use SparkContext.textFile to read files.
You can use the local README.md file (and then flatMap over the lines inside to have an RDD of words):
scala> val words = sc.textFile("README.md").flatMap(_.split("\\W+")).cache
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[27] at flatMap at <console>:24
Note
You cache it so the computation is not performed every time you work with words.
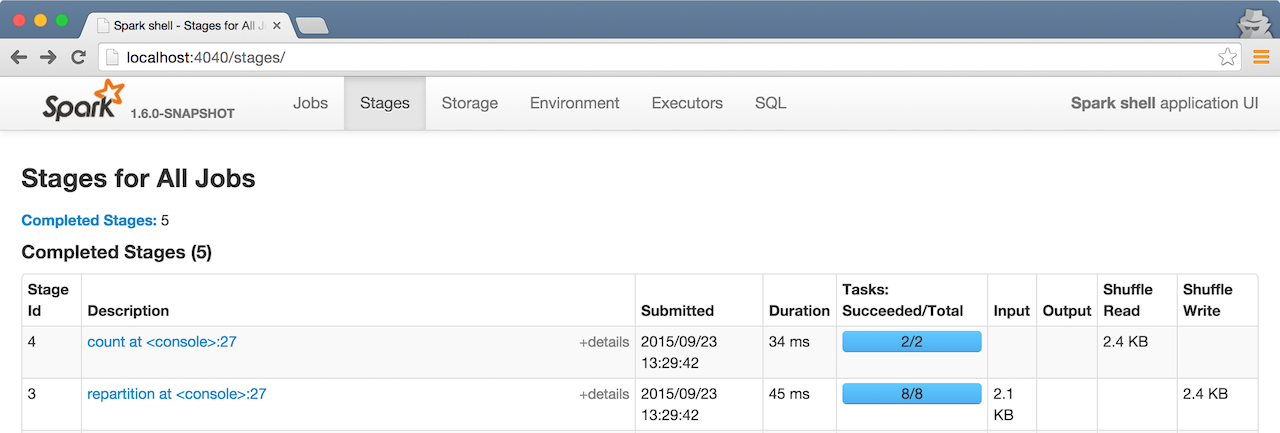
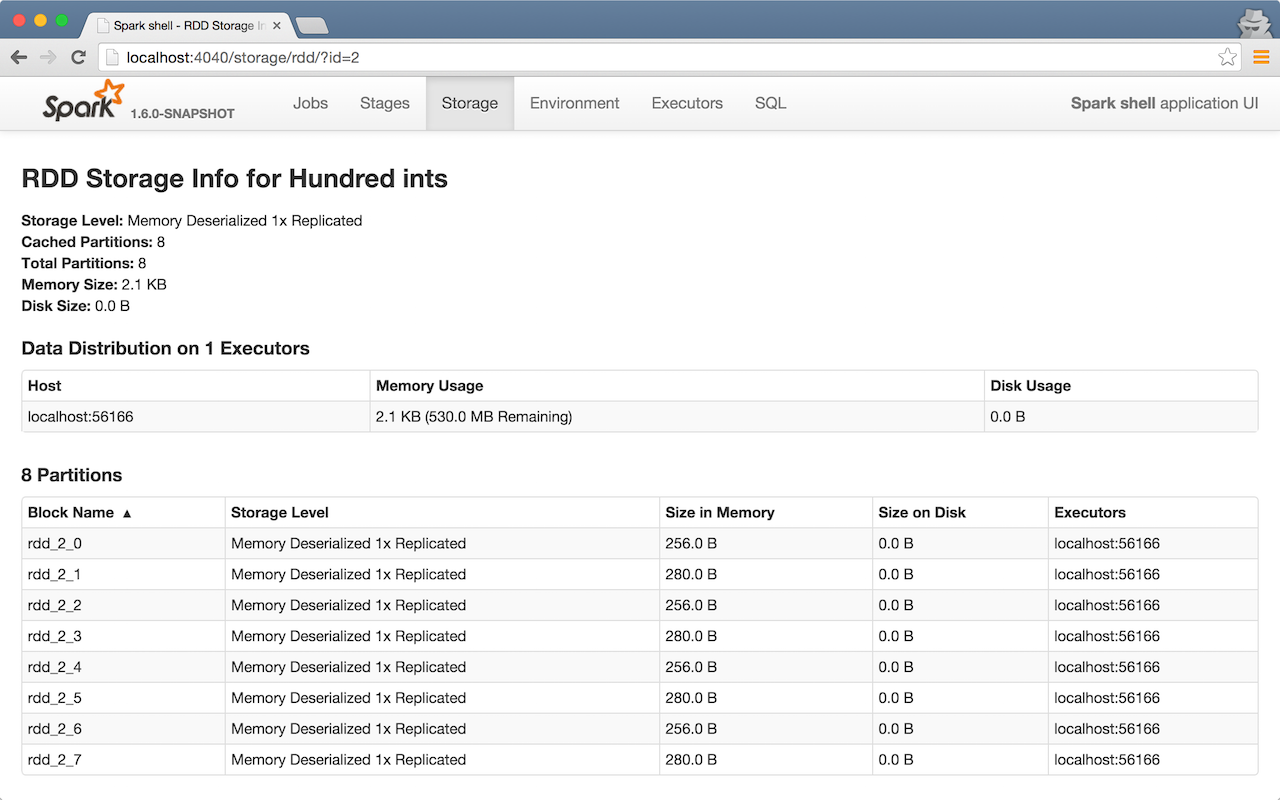
RDDs in Web UI¶
It is quite informative to look at RDDs in the Web UI that is at http://localhost:4040 for Spark shell.
Execute the following Spark application (type all the lines in spark-shell):
val ints = sc.parallelize(1 to 100) // (1)!
ints.setName("Hundred ints") // (2)!
ints.cache // (3)!
ints.count // (4)!
- Creates an RDD with hundred of numbers (with as many partitions as possible)
- Sets the name of the RDD
- Caches the RDD for performance reasons that also makes it visible in Storage tab in the web UI
- Executes action (and materializes the RDD)
With the above executed, you should see the following in the Web UI:
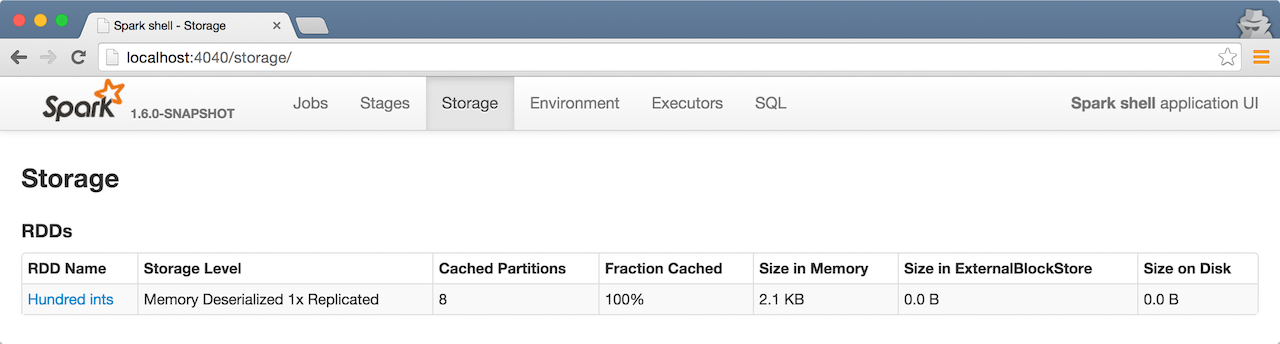
Click the name of the RDD (under RDD Name) and you will get the details of how the RDD is cached.
Execute the following Spark job and you will see how the number of partitions decreases.