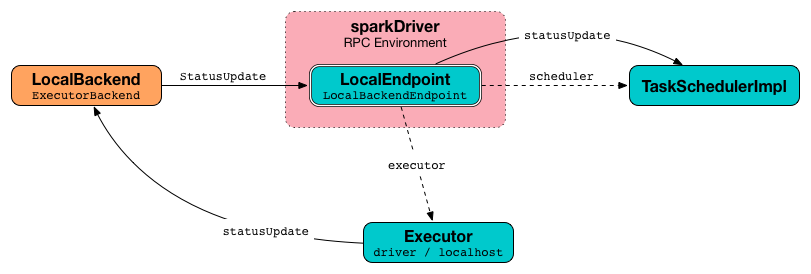
LocalSchedulerBackend¶
LocalSchedulerBackend is a SchedulerBackend and an ExecutorBackend for Spark local deployment.
| Master URL | Total CPU Cores |
|---|---|
local | 1 |
local[n] | n |
local[*] | The number of available CPU cores on the local machine |
local[n, m] | n CPU cores and m task retries |
local[*, m] | The number of available CPU cores on the local machine and m task retries |
Creating Instance¶
LocalSchedulerBackend takes the following to be created:
- SparkConf
- TaskSchedulerImpl
- Total number of CPU cores
LocalSchedulerBackend is created when:
SparkContextis requested to create a Spark Scheduler (forlocalmaster URL)KubernetesClusterManager(Spark on Kubernetes) is requested for aSchedulerBackend
Maximum Number of Concurrent Tasks¶
SchedulerBackend
maxNumConcurrentTasks is part of the SchedulerBackend abstraction.
maxNumConcurrentTasks calculates the number of CPU cores per task for the given ResourceProfile (and this SparkConf).
In the end, maxNumConcurrentTasks is the total CPU cores available divided by the number of CPU cores per task.
Logging¶
Enable ALL logging level for org.apache.spark.scheduler.local.LocalSchedulerBackend logger to see what happens inside.
Add the following line to conf/log4j2.properties:
logger.LocalSchedulerBackend.name = org.apache.spark.scheduler.local.LocalSchedulerBackend
logger.LocalSchedulerBackend.level = all
Refer to Logging.