Spark local¶
Spark local is one of the available runtime environments in Apache Spark. It is the only available runtime with no need for a proper cluster manager (and hence many call it a pseudo-cluster, however such concept do exist in Spark and is a bit different).
Spark local is used for the following master URLs (as specified using <<../SparkConf.md#, SparkConf.setMaster>> method or <<../configuration-properties.md#spark.master, spark.master>> configuration property):
-
local (with exactly 1 CPU core)
-
local[n] (with exactly
nCPU cores) -
local[*] (with the total number of CPU cores that is the number of available CPU cores on the local machine)
-
local[n, m] (with exactly
nCPU cores andmretries when a task fails) -
local[*, m] (with the total number of CPU cores that is the number of available CPU cores on the local machine)
Internally, Spark local uses <
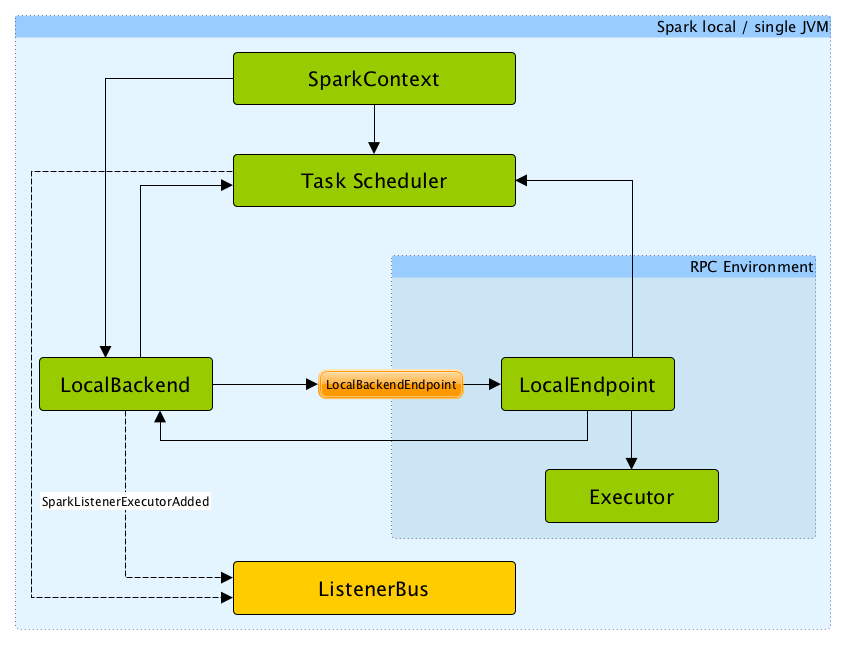
In this non-distributed multi-threaded runtime environment, Spark spawns all the main execution components - the spark-driver.md[driver] and an executor:Executor.md[] - in the same single JVM.
The default parallelism is the number of threads as specified in the <
The local mode is very convenient for testing, debugging or demonstration purposes as it requires no earlier setup to launch Spark applications.
This mode of operation is also called http://spark.apache.org/docs/latest/programming-guide.html#initializing-spark[Spark in-process] or (less commonly) a local version of Spark.
SparkContext.isLocal returns true when Spark runs in local mode.
Spark shell defaults to local mode with local[*] as the the master URL.
Tasks are not re-executed on failure in local mode (unless <
The scheduler:TaskScheduler.md[task scheduler] in local mode works with local/spark-LocalSchedulerBackend.md[LocalSchedulerBackend] task scheduler backend.
Master URL¶
You can run Spark in local mode using local, local[n] or the most general local[*] for the master URL.
The URL says how many threads can be used in total:
-
localuses 1 thread only. -
local[n]usesnthreads. -
local[*]uses as many threads as the number of processors available to the Java virtual machine (it uses https://docs.oracle.com/javase/8/docs/api/java/lang/Runtime.html#availableProcessors--[Runtime.getRuntime.availableProcessors()] to know the number).
NOTE: What happens when there are less cores than n in local[n] master URL? "Breaks" scheduling as Spark assumes more CPU cores available to execute tasks.
- [[local-with-retries]]
local[N, maxFailures](called local-with-retries) withNbeing*or the number of threads to use (as explained above) andmaxFailuresbeing the value of <<../configuration-properties.md#spark.task.maxFailures, spark.task.maxFailures>> configuration property.
== [[task-submission]] Task Submission a.k.a. reviveOffers
.TaskSchedulerImpl.submitTasks in local mode image::taskscheduler-submitTasks-local-mode.png[align="center"]
When ReviveOffers or StatusUpdate messages are received, local/spark-LocalEndpoint.md[LocalEndpoint] places an offer to TaskSchedulerImpl (using TaskSchedulerImpl.resourceOffers).
If there is one or more tasks that match the offer, they are launched (using executor.launchTask method).
The number of tasks to be launched is controlled by the number of threads as specified in <