Executor¶
Creating Instance¶
Executor takes the following to be created:
- Executor ID
- Host name
- SparkEnv
- User-defined jars
- isLocal flag
-
UncaughtExceptionHandler(default:SparkUncaughtExceptionHandler) - Resources (
Map[String, ResourceInformation])
Executor is created when:
CoarseGrainedExecutorBackendis requested to handle a RegisteredExecutor message (after having registered with the driver)LocalEndpointis created
When Created¶
When created, Executor prints out the following INFO messages to the logs:
(only for non-local modes) Executor sets SparkUncaughtExceptionHandler as the default handler invoked when a thread abruptly terminates due to an uncaught exception.
(only for non-local modes) Executor requests the BlockManager to initialize (with the Spark application id of the SparkConf).
(only for non-local modes) Executor requests the MetricsSystem to register the following metric sources:
- ExecutorSource
JVMCPUSource- ExecutorMetricsSource
- ShuffleMetricsSource (of the BlockManager)
Executor uses SparkEnv to access the MetricsSystem and BlockManager.
Executor creates a task class loader (optionally with REPL support) and requests the system Serializer to use as the default classloader (for deserializing tasks).
Executor starts sending heartbeats with the metrics of active tasks.
PluginContainer¶
Executor creates a PluginContainer (with the SparkEnv and the resources).
The PluginContainer is used to create a TaskRunner for launching a task.
The PluginContainer is requested to shutdown in stop.
ExecutorSource¶
When created, Executor creates an ExecutorSource (with the threadPool, the executorId and the schemes).
The ExecutorSource is then registered with the application's MetricsSystem (in local and non-local modes) to report metrics.
The metrics are updated right after a TaskRunner has finished executing a task.
ExecutorMetricsSource¶
Executor creates an ExecutorMetricsSource when created with the spark.metrics.executorMetricsSource.enabled enabled.
Executor uses the ExecutorMetricsSource to create the ExecutorMetricsPoller.
Executor requests the ExecutorMetricsSource to register immediately when created with the isLocal flag disabled.
ExecutorMetricsPoller¶
Executor creates an ExecutorMetricsPoller when created with the following:
Executor requests the ExecutorMetricsPoller to start immediately when created and to stop when requested to stop.
TaskRunner requests the ExecutorMetricsPoller to onTaskStart and onTaskCompletion at the beginning and the end of run, respectively.
When requested to reportHeartBeat with pollOnHeartbeat enabled, Executor requests the ExecutorMetricsPoller to poll.
Fetching File and Jar Dependencies¶
updateDependencies fetches missing or outdated extra files (in the given newFiles). For every name-timestamp pair that...FIXME..., updateDependencies prints out the following INFO message to the logs:
updateDependencies fetches missing or outdated extra jars (in the given newJars). For every name-timestamp pair that...FIXME..., updateDependencies prints out the following INFO message to the logs:
updateDependencies fetches the file to the SparkFiles root directory.
updateDependencies...FIXME
updateDependencies is used when:
TaskRunneris requested to start (and run a task)
spark.driver.maxResultSize¶
Executor uses the spark.driver.maxResultSize for TaskRunner when requested to run a task (and decide on a serialized task result).
Maximum Size of Direct Results¶
Executor uses the minimum of spark.task.maxDirectResultSize and spark.rpc.message.maxSize when TaskRunner is requested to run a task (and decide on the type of a serialized task result).
isLocal Flag¶
Executor is given the isLocal flag when created to indicate a non-local mode (whether the executor and the Spark application runs with local or cluster-specific master URL).
isLocal is disabled (false) by default and is off explicitly when CoarseGrainedExecutorBackend is requested to handle a RegisteredExecutor message.
isLocal is enabled (true) when LocalEndpoint is created
spark.executor.userClassPathFirst¶
Executor reads the value of the spark.executor.userClassPathFirst configuration property when created.
When enabled, Executor uses ChildFirstURLClassLoader (not MutableURLClassLoader) when requested to createClassLoader (and addReplClassLoaderIfNeeded).
User-Defined Jars¶
Executor is given user-defined jars when created. No jars are assumed by default.
The jars are specified using spark.executor.extraClassPath configuration property (via --user-class-path command-line option of CoarseGrainedExecutorBackend).
Running Tasks Registry¶
Executor tracks TaskRunners by task IDs.
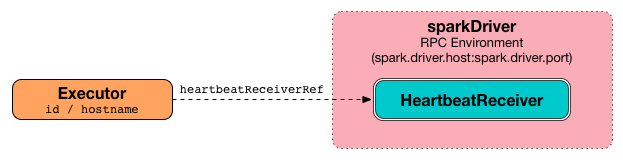
HeartbeatReceiver RPC Endpoint Reference¶
When created, Executor creates an RPC endpoint reference to HeartbeatReceiver (running on the driver).
Executor uses the RPC endpoint reference when requested to reportHeartBeat.
Launching Task¶
launchTask creates a TaskRunner (with the given ExecutorBackend, the TaskDescription and the PluginContainer) and adds it to the runningTasks internal registry.
launchTask requests the "Executor task launch worker" thread pool to execute the TaskRunner (sometime in the future).
In case the decommissioned flag is enabled, launchTask prints out the following ERROR message to the logs:
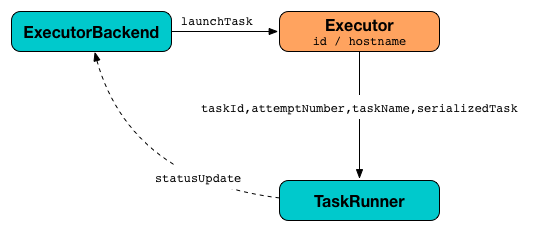
launchTask is used when:
CoarseGrainedExecutorBackendis requested to handle a LaunchTask messageLocalEndpointRPC endpoint (of LocalSchedulerBackend) is requested to reviveOffers
Sending Heartbeats and Active Tasks Metrics¶
Executors keep sending metrics for active tasks to the driver every spark.executor.heartbeatInterval (defaults to 10s with some random initial delay so the heartbeats from different executors do not pile up on the driver).
An executor sends heartbeats using the Heartbeat Sender Thread.
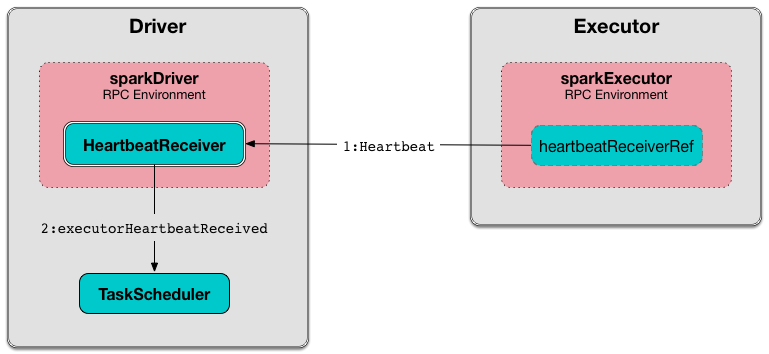
For each task in TaskRunner (in runningTasks internal registry), the task's metrics are computed and become part of the heartbeat (with accumulators).
A blocking Heartbeat message that holds the executor id, all accumulator updates (per task id), and BlockManagerId is sent to HeartbeatReceiver RPC endpoint.
If the response requests to re-register BlockManager, Executor prints out the following INFO message to the logs:
BlockManager is requested to reregister.
The internal heartbeatFailures counter is reset.
If there are any issues with communicating with the driver, Executor prints out the following WARN message to the logs:
The internal heartbeatFailures is incremented and checked to be less than the spark.executor.heartbeat.maxFailures. If the number is greater, the following ERROR is printed out to the logs:
The executor exits (using System.exit and exit code 56).
Heartbeat Sender Thread¶
heartbeater is a ScheduledThreadPoolExecutor (Java) with a single thread.
The name of the thread pool is driver-heartbeater.
Executor task launch worker Thread Pool¶
When created, Executor creates threadPool daemon cached thread pool with the name Executor task launch worker-[ID] (with ID being the task id).
The threadPool thread pool is used for launching tasks.
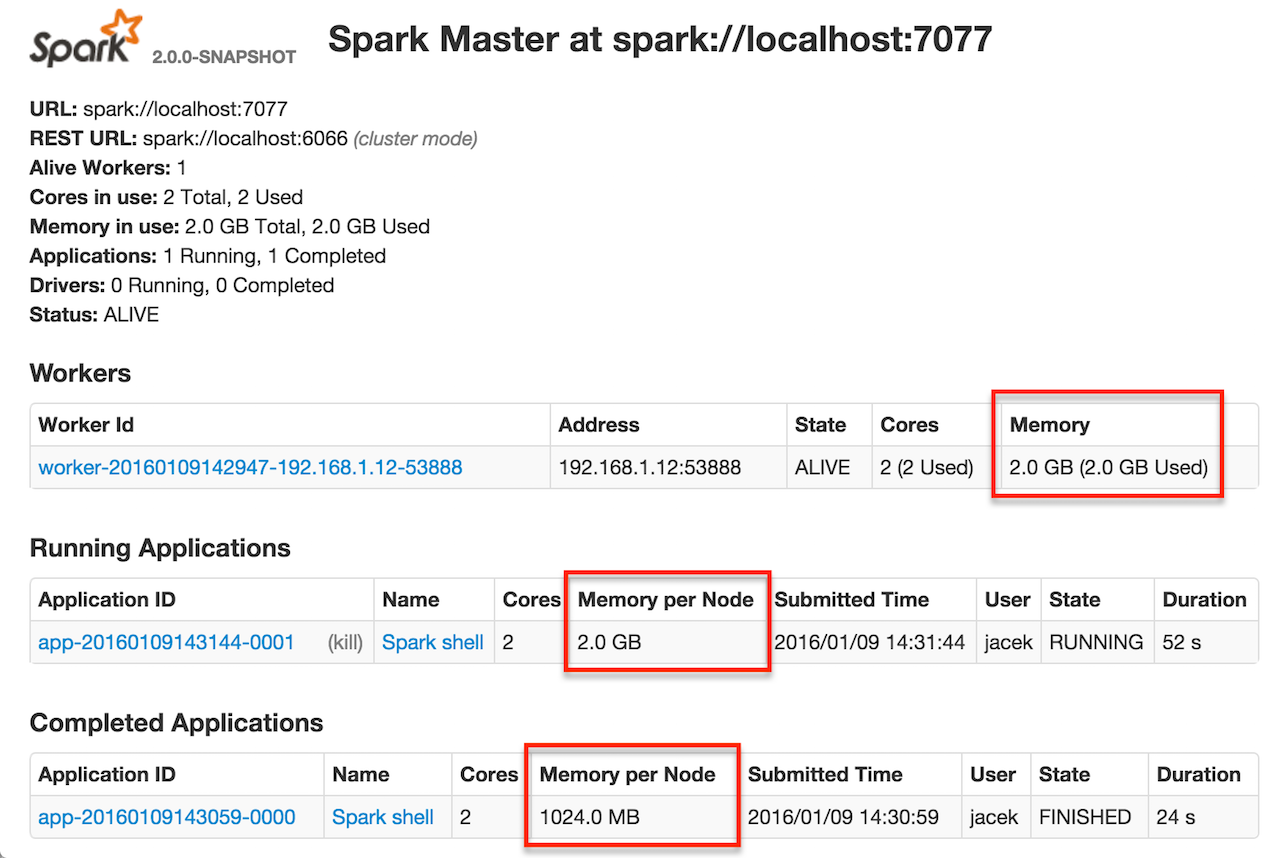
Executor Memory¶
The amount of memory per executor is configured using spark.executor.memory configuration property. It sets the available memory equally for all executors per application.
You can find the value displayed as Memory per Node in the web UI of the standalone Master.
Heartbeating With Partial Metrics For Active Tasks To Driver¶
reportHeartBeat collects TaskRunners for currently running tasks (active tasks) with their tasks deserialized (i.e. either ready for execution or already started).
TaskRunner has task deserialized when it runs the task.
For every running task, reportHeartBeat takes the TaskMetrics and:
reportHeartBeat then records the latest values of internal and external accumulators for every task.
Note
Internal accumulators are a task's metrics while external accumulators are a Spark application's accumulators that a user has created.
reportHeartBeat sends a blocking Heartbeat message to the HeartbeatReceiver (on the driver). reportHeartBeat uses the value of spark.executor.heartbeatInterval configuration property for the RPC timeout.
Note
A Heartbeat message contains the executor identifier, the accumulator updates, and the identifier of the BlockManager.
If the response (from HeartbeatReceiver) is to re-register the BlockManager, reportHeartBeat prints out the following INFO message to the logs and requests the BlockManager to re-register (which will register the blocks the BlockManager manages with the driver).
HeartbeatResponse requests the BlockManager to re-register when either TaskScheduler or HeartbeatReceiver know nothing about the executor.
When posting the Heartbeat was successful, reportHeartBeat resets heartbeatFailures internal counter.
In case of a non-fatal exception, you should see the following WARN message in the logs (followed by the stack trace).
Every failure reportHeartBeat increments heartbeat failures up to spark.executor.heartbeat.maxFailures configuration property. When the heartbeat failures reaches the maximum, reportHeartBeat prints out the following ERROR message to the logs and the executor terminates with the error code: 56.
reportHeartBeat is used when:
Executoris requested to schedule reporting heartbeat and partial metrics for active tasks to the driver (that happens every spark.executor.heartbeatInterval).
spark.executor.heartbeat.maxFailures¶
Executor uses spark.executor.heartbeat.maxFailures configuration property in reportHeartBeat.
Logging¶
Enable ALL logging level for org.apache.spark.executor.Executor logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.