CoarseGrainedExecutorBackend¶
CoarseGrainedExecutorBackend is an ExecutorBackend that controls the lifecycle of a single executor.
CoarseGrainedExecutorBackend is an IsolatedThreadSafeRpcEndpoint that connects to the driver (before accepting messages) and shuts down when the driver disconnects.
CoarseGrainedExecutorBackend can receive the following messages:
- DecommissionExecutor
- KillTask
- LaunchTask
- RegisteredExecutor
- Shutdown
- StopExecutor
- UpdateDelegationTokens
When launched, CoarseGrainedExecutorBackend immediately connects to the parent CoarseGrainedSchedulerBackend (to inform that it is ready to launch tasks).
CoarseGrainedExecutorBackend registers the Executor RPC endpoint to communicate with the driver (with DriverEndpoint).
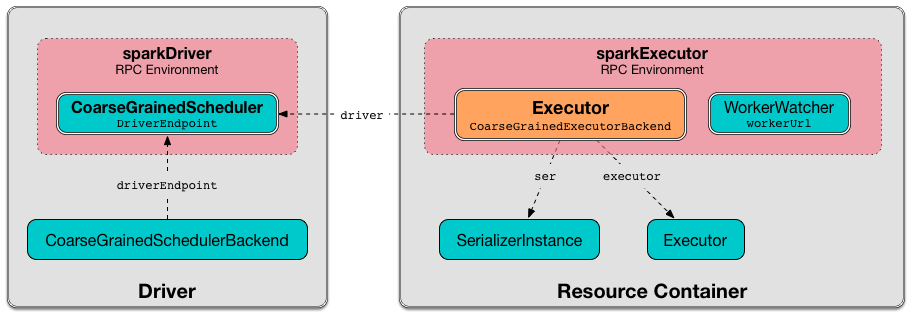
CoarseGrainedExecutorBackend sends regular executor status updates to the driver (to keep the Spark scheduler updated on the number of CPU cores free for task scheduling).
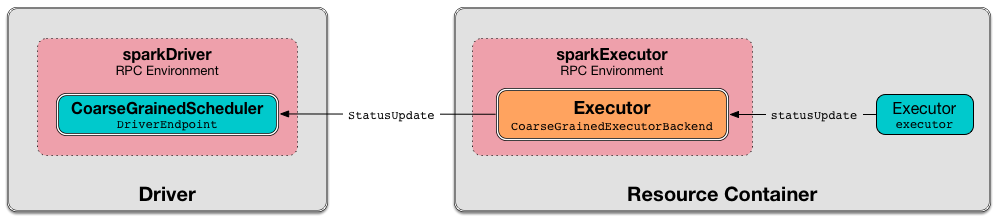
CoarseGrainedExecutorBackend is started in a resource container (as a standalone application).
Creating Instance¶
CoarseGrainedExecutorBackend takes the following to be created:
- RpcEnv
- Driver URL
- Executor ID
- Bind Address (unused)
- Hostname
- Number of CPU cores
- SparkEnv
- Resources Configuration File
- ResourceProfile
Note
driverUrl, executorId, hostname, cores and userClassPath correspond to CoarseGrainedExecutorBackend standalone application's command-line arguments.
CoarseGrainedExecutorBackend is created upon launching CoarseGrainedExecutorBackend standalone application.
Executor¶
CoarseGrainedExecutorBackend manages the lifecycle of a single Executor:
- An
Executoris created upon receiving a RegisteredExecutor message - Stopped upon receiving a Shutdown message (that happens on a separate
CoarseGrainedExecutorBackend-stop-executorthread)
The Executor is used for the following:
- decommissionSelf
- Launching a task (upon receiving a LaunchTask message)
- Killing a task (upon receiving a KillTask message)
- Reporting the number of CPU cores used for a given task in statusUpdate
Reporting Task Status¶
ExecutorBackend
statusUpdate is part of the ExecutorBackend abstraction.
statusUpdate...FIXME
Starting Up¶
With spark.decommission.enabled enabled, onStart...FIXME
onStart prints out the following INFO message to the logs (with the driverUrl):
onStart builds a transport-related configuration for shuffle module.
onStart parseOrFindResources in the given resourcesFileOpt, if defined, and initializes the _resources internal registry (of ResourceInformations).
onStart asyncSetupEndpointRefByURI (with the given driverUrl).
If successful, onStart initializes the driver internal registry.
onStart makes this CoarseGrainedExecutorBackend available to other Spark services using the executorBackend registry.
onStart sends a blocking RegisterExecutor message. If successful, onStart sends a RegisteredExecutor (to itself).
In case of any failure, onStart terminates this CoarseGrainedExecutorBackend with the error code 1 and the following reason (with no notification to the driver):
Messages¶
DecommissionExecutor¶
DecommissionExecutor is sent out when CoarseGrainedSchedulerBackend is requested to decommissionExecutors
When received, CoarseGrainedExecutorBackend decommissionSelf.
RegisteredExecutor¶
When received, CoarseGrainedExecutorBackend prints out the following INFO message to the logs:
CoarseGrainedExecutorBackend initializes the single managed Executor (with the given executorId, the hostname) and sends a LaunchedExecutor message back to the driver.
RegisteredExecutor is sent out when CoarseGrainedSchedulerBackend has finished onStart successfully (and registered with the driver).
Logging¶
Enable ALL logging level for org.apache.spark.executor.CoarseGrainedExecutorBackend logger to see what happens inside.
Add the following line to conf/log4j2.properties:
logger.CoarseGrainedExecutorBackend.name = org.apache.spark.executor.CoarseGrainedExecutorBackend
logger.CoarseGrainedExecutorBackend.level = all
Refer to Logging.