Accumulators¶
Accumulators are shared variables that accumulate values from executors on the driver using associative and commutative "add" operation.
The main abstraction is AccumulatorV2.
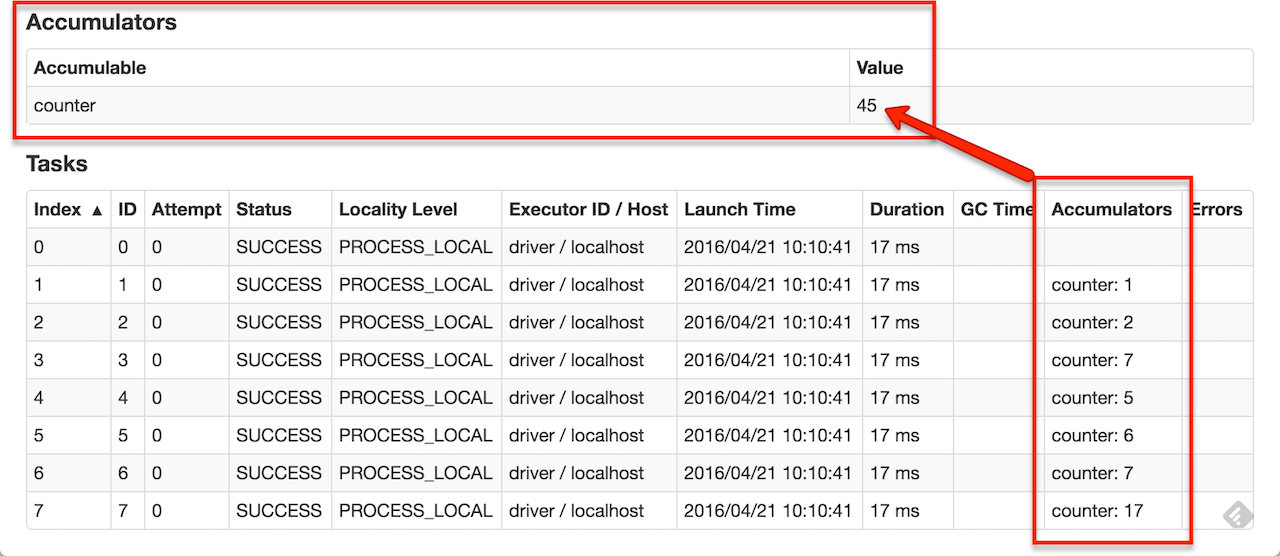
Accumulators are registered (created) using SparkContext with or without a name. Only named accumulators are displayed in web UI.
DAGScheduler is responsible for updating accumulators (from partial values from tasks running on executors every heartbeat).
Accumulators are serializable so they can safely be referenced in the code executed in executors and then safely send over the wire for execution.
// on the driver
val counter = sc.longAccumulator("counter")
sc.parallelize(1 to 9).foreach { x =>
// on executors
counter.add(x) }
// on the driver
println(counter.value)