SparkEnv¶
SparkEnv is a handle to Spark Execution Environment with the core services of Apache Spark (that interact with each other to establish a distributed computing platform for a Spark application).
There are two separate SparkEnvs of the driver and executors.
Core Services¶
| Property | Service |
|---|---|
| blockManager | BlockManager |
| broadcastManager | BroadcastManager |
| closureSerializer | Serializer |
| conf | SparkConf |
| mapOutputTracker | MapOutputTracker |
| memoryManager | MemoryManager |
| metricsSystem | MetricsSystem |
| outputCommitCoordinator | OutputCommitCoordinator |
| rpcEnv | RpcEnv |
| securityManager | SecurityManager |
| serializer | Serializer |
| serializerManager | SerializerManager |
| shuffleManager | ShuffleManager |
Creating Instance¶
SparkEnv takes the following to be created:
- Executor ID
- RpcEnv
- Serializer
- Serializer
- SerializerManager
- MapOutputTracker
- ShuffleManager
- BroadcastManager
- BlockManager
- SecurityManager
- MetricsSystem
- MemoryManager
- OutputCommitCoordinator
- SparkConf
SparkEnv is created using create utility.
Driver's Temporary Directory¶
SparkEnv defines driverTmpDir internal registry for the driver to be used as the root directory of files added using SparkContext.addFile.
driverTmpDir is undefined initially and is defined for the driver only when SparkEnv utility is used to create a "base" SparkEnv.
Demo¶
// :pa -raw
// BEGIN
package org.apache.spark
object BypassPrivateSpark {
def driverTmpDir(sparkEnv: SparkEnv) = {
sparkEnv.driverTmpDir
}
}
// END
The above is equivalent to the following snippet.
Creating SparkEnv for Driver¶
createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv
createDriverEnv creates a SparkEnv execution environment for the driver.
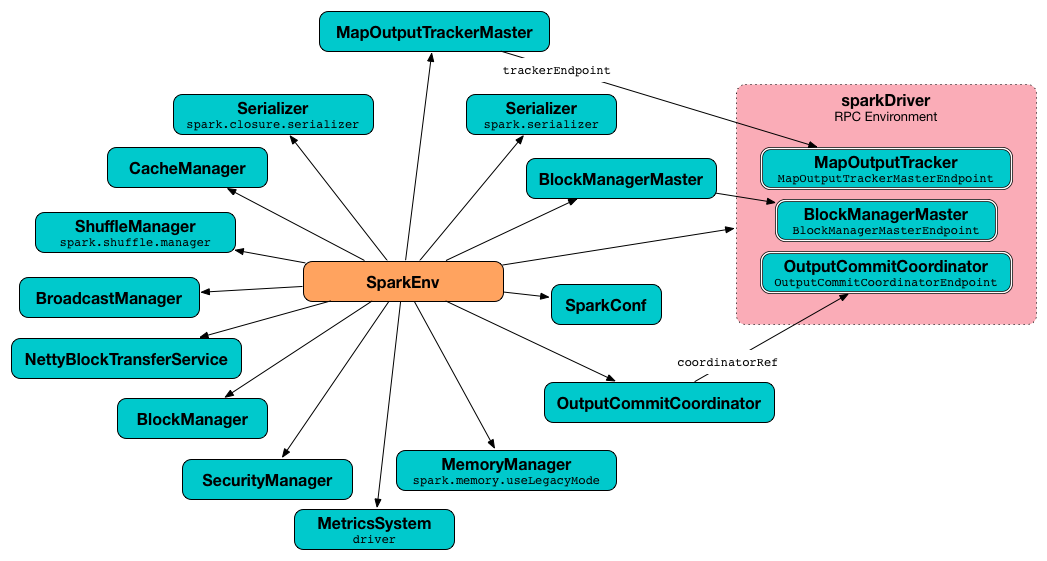
createDriverEnv accepts an instance of SparkConf, whether it runs in local mode or not, scheduler:LiveListenerBus.md[], the number of cores to use for execution in local mode or 0 otherwise, and a OutputCommitCoordinator (default: none).
createDriverEnv ensures that spark-driver.md#spark_driver_host[spark.driver.host] and spark-driver.md#spark_driver_port[spark.driver.port] settings are defined.
It then passes the call straight on to the <driver executor id, isDriver enabled, and the input parameters).
createDriverEnv is used when SparkContext is created.
Creating SparkEnv for Executor¶
createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnv
createExecutorEnv(
conf: SparkConf,
executorId: String,
bindAddress: String,
hostname: String,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnv
createExecutorEnv creates an executor's (execution) environment that is the Spark execution environment for an executor.
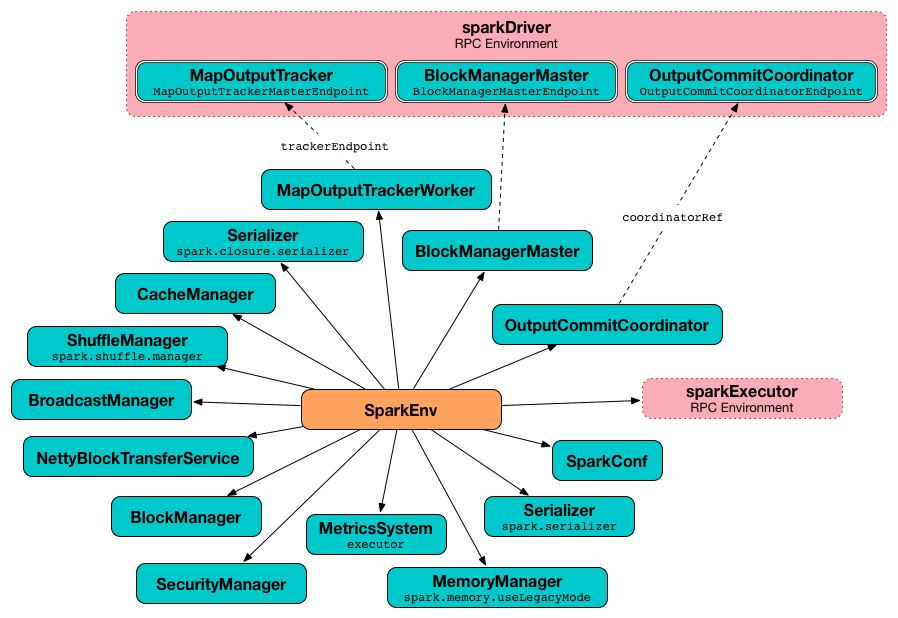
createExecutorEnv simply <
NOTE: The number of cores numCores is configured using --cores command-line option of CoarseGrainedExecutorBackend and is specific to a cluster manager.
createExecutorEnv is used when CoarseGrainedExecutorBackend utility is requested to run.
Creating "Base" SparkEnv¶
create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Option[Int],
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv
create creates the "base" SparkEnv (that is common across the driver and executors).
create creates a RpcEnv as sparkDriver on the driver and sparkExecutor on executors.
create creates a Serializer (based on spark.serializer configuration property). create prints out the following DEBUG message to the logs:
create creates a SerializerManager.
create creates a JavaSerializer as the closure serializer.
creates creates a BroadcastManager.
creates creates a MapOutputTrackerMaster (on the driver) or a MapOutputTrackerWorker (on executors). creates registers or looks up a MapOutputTrackerMasterEndpoint under the name of MapOutputTracker. creates prints out the following INFO message to the logs (on the driver only):
creates creates a ShuffleManager (based on spark.shuffle.manager configuration property).
create creates a UnifiedMemoryManager.
With spark.shuffle.service.enabled configuration property enabled, create creates an ExternalBlockStoreClient.
create creates a BlockManagerMaster.
create creates a NettyBlockTransferService.
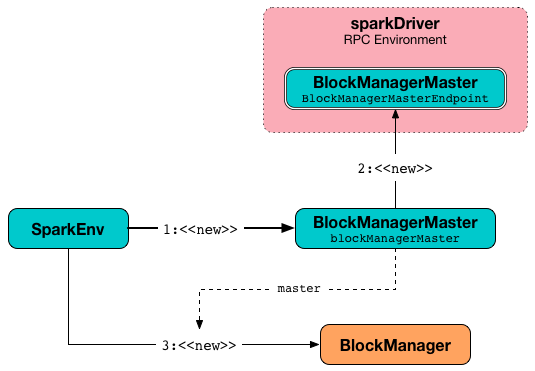
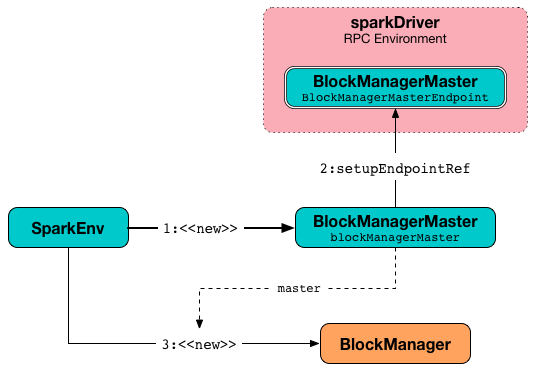
create creates a BlockManager.
create creates a MetricsSystem.
create creates a OutputCommitCoordinator and registers or looks up a OutputCommitCoordinatorEndpoint under the name of OutputCommitCoordinator.
create creates a SparkEnv (with all the services "stitched" together).
Logging¶
Enable ALL logging level for org.apache.spark.SparkEnv logger to see what happens inside.
Add the following line to conf/log4j.properties:
Refer to Logging.