SparkContext¶
SparkContext is the entry point to all of the components of Apache Spark (execution engine) and so the heart of a Spark application. In fact, you can consider an application a Spark application only when it uses a SparkContext (directly or indirectly).

Important
There should be one active SparkContext per JVM and Spark developers should use SparkContext.getOrCreate utility for sharing it (e.g. across threads).
Creating Instance¶
SparkContext takes the following to be created:
SparkContext is created (directly or indirectly using getOrCreate utility).
While being created, SparkContext sets up core services and establishes a connection to a cluster manager.
Checkpoint Directory¶
SparkContext defines checkpointDir internal registry for the path to a checkpoint directory.
checkpointDir is undefined (None) when SparkContext is created and is set using setCheckpointDir.
checkpointDir is required for Reliable Checkpointing.
checkpointDir is available using getCheckpointDir.
getCheckpointDir¶
getCheckpointDir returns the checkpointDir.
getCheckpointDir is used when:
ReliableRDDCheckpointDatais requested for the checkpoint path
Submitting MapStage for Execution¶
submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C]): SimpleFutureAction[MapOutputStatistics]
submitMapStage requests the DAGScheduler to submit the given ShuffleDependency for execution (that eventually produces a MapOutputStatistics).
submitMapStage is used when:
ShuffleExchangeExec(Spark SQL) unary physical operator is executed
ExecutorMetricsSource¶
SparkContext creates an ExecutorMetricsSource when created with spark.metrics.executorMetricsSource.enabled enabled.
SparkContext requests the ExecutorMetricsSource to register with the MetricsSystem.
SparkContext uses the ExecutorMetricsSource to create the Heartbeater.
Services¶
-
ExecutorAllocationManager (optional)
ResourceProfileManager¶
SparkContext creates a ResourceProfileManager when created.
resourceProfileManager¶
resourceProfileManager returns the ResourceProfileManager.
resourceProfileManager is used when:
KubernetesClusterSchedulerBackend(Spark on Kubernetes) is created- others
DriverLogger¶
SparkContext can create a DriverLogger when created.
SparkContext requests the DriverLogger to startSync in postApplicationStart.
AppStatusSource¶
SparkContext can create an AppStatusSource when created (based on the spark.metrics.appStatusSource.enabled configuration property).
SparkContext uses the AppStatusSource to create the AppStatusStore.
If configured, SparkContext registers the AppStatusSource with the MetricsSystem.
AppStatusStore¶
SparkContext creates an AppStatusStore when created (with itself and the AppStatusSource).
SparkContext requests AppStatusStore for the AppStatusListener and requests the LiveListenerBus to add it to the application status queue.
SparkContext uses the AppStatusStore to create the following:
AppStatusStore is requested to status/AppStatusStore.md#close in stop.
statusStore¶
statusStore returns the AppStatusStore.
statusStore is used when:
SparkContextis requested to getRDDStorageInfoConsoleProgressBaris requested to refreshHiveThriftServer2is requested tocreateListenerAndUISharedState(Spark SQL) is requested for aSQLAppStatusStoreand aStreamingQueryStatusListener
SparkStatusTracker¶
SparkContext creates a SparkStatusTracker when created (with itself and the AppStatusStore).
statusTracker¶
statusTracker returns the SparkStatusTracker.
Local Properties¶
SparkContext uses an InheritableThreadLocal (Java) of key-value pairs of thread-local properties to pass extra information from a parent thread (on the driver) to child threads.
localProperties is meant to be used by developers using SparkContext.setLocalProperty and SparkContext.getLocalProperty.
Local Properties are available using TaskContext.getLocalProperty.
Local Properties are available to SparkListeners using the following events:
localProperties are passed down when SparkContext is requested for the following:
- Running Job (that in turn makes the local properties available to the DAGScheduler to run a job)
- Running Approximate Job
- Submitting Job
- Submitting MapStage
DAGScheduler passes down local properties when scheduling:
Spark (Core) defines the following local properties.
| Name | Default Value | Setter |
|---|---|---|
callSite.long | ||
callSite.short | SparkContext.setCallSite | |
spark.job.description | callSite.short | SparkContext.setJobDescription ( SparkContext.setJobGroup) |
spark.job.interruptOnCancel | SparkContext.setJobGroup | |
spark.jobGroup.id | SparkContext.setJobGroup | |
spark.scheduler.pool |
ShuffleDriverComponents¶
SparkContext creates a ShuffleDriverComponents when created.
SparkContext loads the ShuffleDataIO that is in turn requested for the ShuffleDriverComponents. SparkContext requests the ShuffleDriverComponents to initialize.
The ShuffleDriverComponents is used when:
ShuffleDependencyis createdSparkContextcreates the ContextCleaner (if enabled)
SparkContext requests the ShuffleDriverComponents to clean up when stopping.
Static Files¶
addFile¶
Firstly, addFile validate the schema of given path. For a no-schema path, addFile converts it to a canonical form. For a local schema path, addFile prints out the following WARN message to the logs and exits.
File with 'local' scheme is not supported to add to file server, since it is already available on every node.
addFile creates a Hadoop Path from the given path. addFile Will validate the URL if the path is an HTTP, HTTPS or FTP URI.
addFile Will throw SparkException with below message if path is local directories but not in local mode.
addFile Will throw SparkException with below message if path is directories but not turn on recursive flag.
In the end, addFile adds the file to the addedFiles internal registry (with the current timestamp):
-
For new files,
addFileprints out the following INFO message to the logs, fetches the file (to the root directory and without using the cache) and postEnvironmentUpdate. -
For files that were already added,
addFileprints out the following WARN message to the logs:
addFile is used when:
SparkContextis created
listFiles¶
listFiles is the files added.
addedFiles Internal Registry¶
addedFiles is a collection of static files by the timestamp the were added at.
addedFiles is used when:
SparkContextis requested to postEnvironmentUpdate and listFilesTaskSetManageris created (and resourceOffer)
files¶
files is a collection of file paths defined by spark.files configuration property.
Posting SparkListenerEnvironmentUpdate Event¶
postEnvironmentUpdate...FIXME
postEnvironmentUpdate is used when:
getOrCreate Utility¶
getOrCreate...FIXME
PluginContainer¶
SparkContext creates a PluginContainer when created.
PluginContainer is created (for the driver where SparkContext lives) using PluginContainer.apply utility.
PluginContainer is then requested to registerMetrics with the applicationId.
PluginContainer is requested to shutdown when SparkContext is requested to stop.
Creating SchedulerBackend and TaskScheduler¶
createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler)
createTaskScheduler creates a SchedulerBackend and a TaskScheduler for the given master URL and deployment mode.
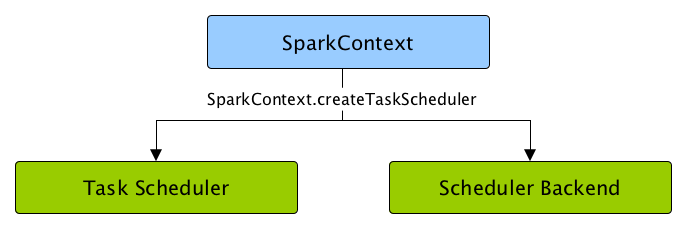
Internally, createTaskScheduler branches off per the given master URL to select the requested implementations.
createTaskScheduler accepts the following master URLs:
local- local mode with 1 thread onlylocal[n]orlocal[*]- local mode withnthreadslocal[n, m]orlocal[*, m]-- local mode withnthreads andmnumber of failuresspark://hostname:portfor Spark Standalonelocal-cluster[n, m, z]-- local cluster withnworkers,mcores per worker, andzmemory per worker- Other URLs are simply handed over to getClusterManager to load an external cluster manager if available
createTaskScheduler is used when SparkContext is created.
Loading ExternalClusterManager¶
getClusterManager uses Java's ServiceLoader to find and load an ExternalClusterManager that supports the given master URL.
ExternalClusterManager Service Discovery
For ServiceLoader to find ExternalClusterManagers, they have to be registered using the following file:
getClusterManager throws a SparkException when multiple cluster managers were found:
getClusterManager is used when SparkContext is requested for a SchedulerBackend and TaskScheduler.
Running Job (Synchronously)¶
runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U): Array[U]
runJob[T, U: ClassTag](
rdd: RDD[T],
processPartition: (TaskContext, Iterator[T]) => U,
resultHandler: (Int, U) => Unit): Unit
runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U]
runJob[T, U: ClassTag]( // (1)!
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit
runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U): Array[U]
runJob[T, U: ClassTag](
rdd: RDD[T],
processPartition: Iterator[T] => U,
resultHandler: (Int, U) => Unit): Unit
runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U]
- Requests the DAGScheduler to run a job
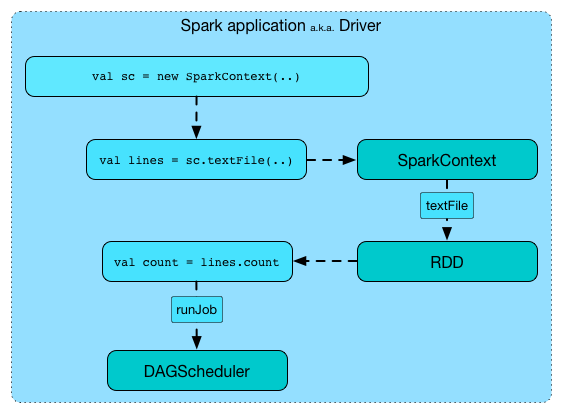
runJob determines the call site and cleans up the given func function.
runJob prints out the following INFO message to the logs:
With spark.logLineage enabled, runJob requests the given RDD for the recursive dependencies and prints out the following INFO message to the logs:
runJob requests the DAGScheduler to run a job with the following:
- The given
rdd - The given
funccleaned up - The given
partitions - The call site
- The given
resultHandlerfunction (procedure) - The local properties
Note
runJob is blocked until the job has finished (regardless of the result, successful or not).
runJob requests the ConsoleProgressBar (if available) to finishAll.
In the end, runJob requests the given RDD to doCheckpoint.
Demo¶
runJob is essentially executing a func function on all or a subset of partitions of an RDD and returning the result as an array (with elements being the results per partition).
sc.setLocalProperty("callSite.short", "runJob Demo")
val partitionsNumber = 4
val rdd = sc.parallelize(
Seq("hello world", "nice to see you"),
numSlices = partitionsNumber)
import org.apache.spark.TaskContext
val func = (t: TaskContext, ss: Iterator[String]) => 1
val result = sc.runJob(rdd, func)
assert(result.length == partitionsNumber)
sc.clearCallSite()
Call Site¶
getCallSite...FIXME
getCallSite is used when:
SparkContextis requested to broadcast, runJob, runApproximateJob, submitJob and submitMapStageAsyncRDDActionsis requested to takeAsyncRDDis created
Closure Cleaning¶
clean cleans up the given f closure (using ClosureCleaner.clean utility).
Tip
Enable DEBUG logging level for org.apache.spark.util.ClosureCleaner logger to see what happens inside the class.
Add the following line to conf/log4j.properties:
Refer to Logging.
With DEBUG logging level you should see the following messages in the logs:
+++ Cleaning closure [func] ([func.getClass.getName]) +++
+ declared fields: [declaredFields.size]
[field]
...
+++ closure [func] ([func.getClass.getName]) is now cleaned +++
Maximum Number of Concurrent Tasks¶
maxNumConcurrentTasks requests the SchedulerBackend for the maximum number of tasks that can be launched concurrently (with the given ResourceProfile).
maxNumConcurrentTasks is used when:
DAGScheduleris requested to checkBarrierStageWithNumSlots
withScope¶
withScope withScope with this SparkContext.
Note
withScope is used for most (if not all) SparkContext API operators.
Finding Preferred Locations for RDD Partition¶
getPreferredLocs requests the DAGScheduler for the preferred locations of the given partition (of the given RDD).
Note
Preferred locations of a RDD partition are also referred to as placement preferences or locality preferences.
getPreferredLocs is used when:
CoalescedRDDPartitionis requested tolocalFractionDefaultPartitionCoalesceris requested tocurrPrefLocsPartitionerAwareUnionRDDis requested tocurrPrefLocs
Logging¶
Enable ALL logging level for org.apache.spark.SparkContext logger to see what happens inside.
Add the following line to conf/log4j2.properties:
Refer to Logging.